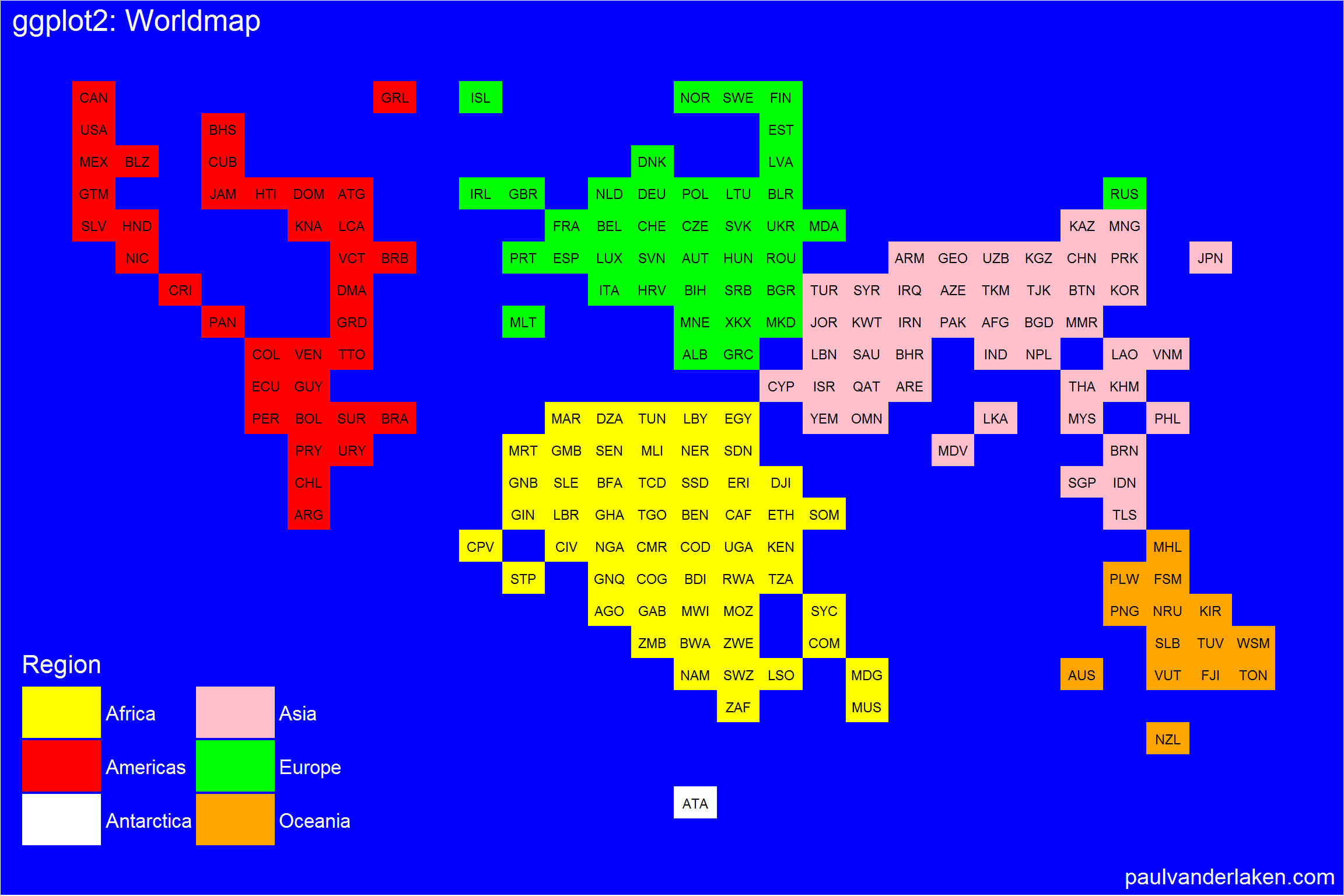
Those of you who follow my blog know I love world maps. Particularly when they are used to visualize data, like these maps of Kaggle programming language preferences, US household incomes, rush hour travel times, or Shazam recognitions. Those who share this passion will probably like this blog’s topic: mapping data to pixel maps! In R obviously!
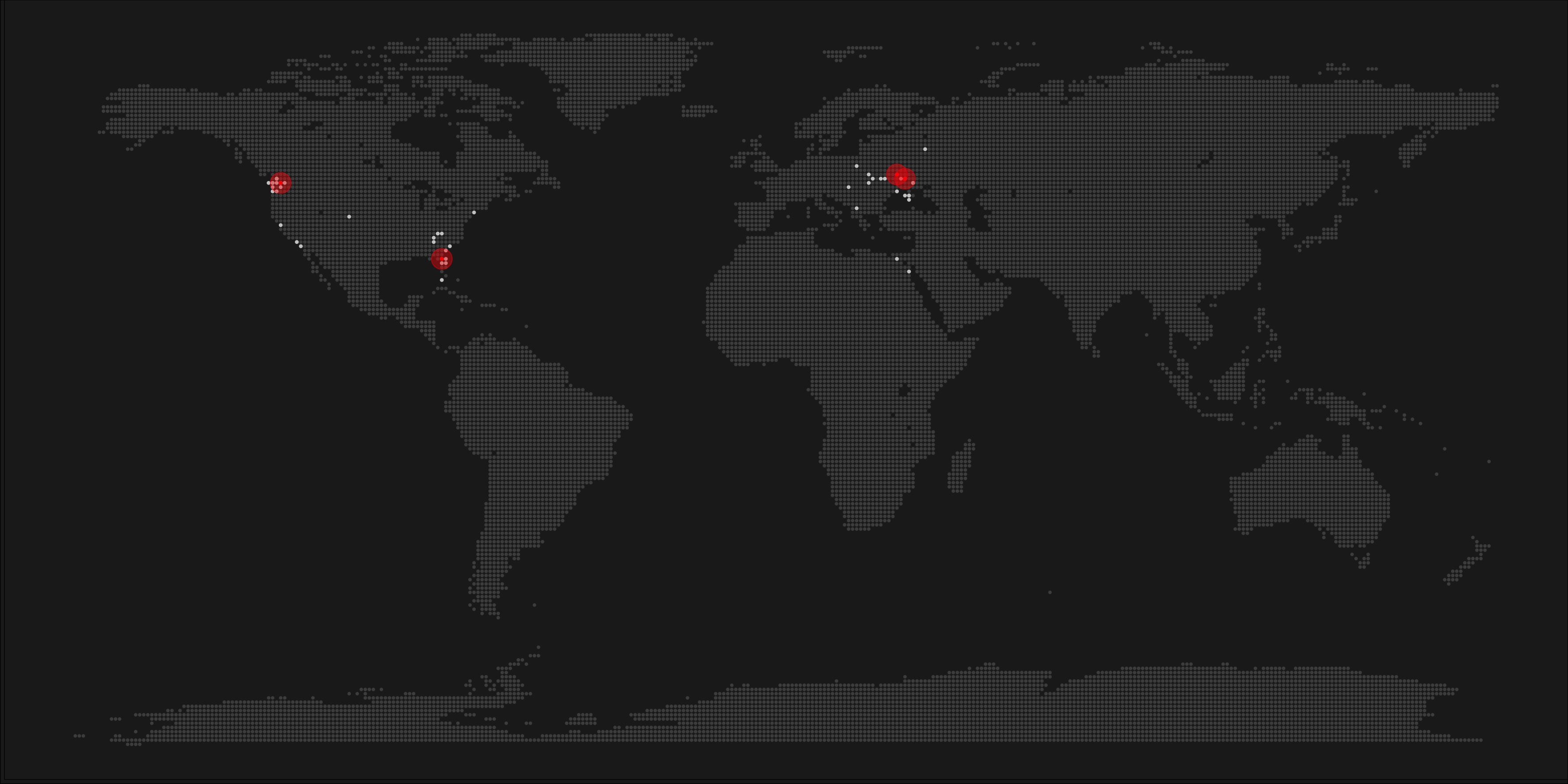
Taras Kaduk seems as excited about R and the tidyverse as I am, as he built the beautiful map above. It flags all the cities he has visited and, in red, the cities he has lived. Taras was nice enough to share his code here, in the original blog post.
Now, I am not much of a globetrotter, but I do like programming. Hence, I immediately wanted to play with the code and visualize my own holiday destinations. Below you can find my attempt. The updated code I also posted below, but WordPress doesn’t handle code well, so you better look here.

Let’s run you through the steps to make such a map. First, we need to load some packages. I use the apply family to install and/or load a set of packages so that if I/you run the script on a different computer, it will still work. In terms of packages, the tidyverse (read more) includes some nice data manipulation packages as well as the famous ggplot2 package for visualizations. We need maps and ggmap for their mapping functionalities. here is a great little package for convenient project management, as you will see (read more).
### setup ----------------------------------------------------------------------
# install and/or load packages
pkg <- c("tidyverse", "maps", "ggmap", "here")
sapply(pkg, function(x){
if(! x %in% installed.packages()) install.packages(x)
require(x, character.only = TRUE)
})Next, we need to load in the coordinates (longitudes and latitudes) of our holiday destinations. Now, I started out creating a dataframe with city coordinates by hand. However, this was definitely not a scale-able solution. Fortunately, after some Googling, I came across ggmap::geocode(). This function allows you to query the Google maps API(no longer works) Data Science Toolkit, which returns all kinds of coordinates data for any character string you feed it.
Although, I ran into two problems with this approach, this was nothing we couldn’t fix. First, my home city of Breda apparently has a name-city in the USA, which Google favors. Accordingly, you need to be careful and/or specific regarding the strings you feed to geocode() (e.g., “Breda NL“). Second, API’s often have a query limit, meaning you can only ask for data every so often. geocode() will quickly return NAs when you feed it more than two, three values. Hence, I wrote a simple while loop to repeat the query until the API retrieves coordinates. The query will pause shortly in between every attempt. Returned coordinates are then stored in the empty dataframe I created earlier. Now, we can easily query a couple dozen of locations without errors.
You can try it yourself: all you need to change is the city_name string.
### cities data ----------------------------------------------------------------
# cities to geolocate
city_name <- c("breda NL", "utrecht", "rotterdam", "tilburg", "amsterdam",
"london", "singapore", "kuala lumpur", "zanzibar", "antwerp",
"middelkerke", "maastricht", "bruges", "san fransisco", "vancouver",
"willemstad", "hurghada", "paris", "rome", "bordeaux",
"berlin", "kos", "crete", "kefalonia", "corfu",
"dubai", " barcalona", "san sebastian", "dominican republic",
"porto", "gran canaria", "albufeira", "istanbul",
"lake como", "oslo", "riga", "newcastle", "dublin",
"nice", "cardiff", "san fransisco", "tokyo", "kyoto", "osaka",
"bangkok", "krabi thailand", "chang mai thailand", "koh tao thailand")
# initialize empty dataframe
tibble(
city = city_name,
lon = rep(NA, length(city_name)),
lat = rep(NA, length(city_name))
) ->
cities
# loop cities through API to overcome SQ limit
# stop after if unsuccessful after 5 attempts
for(c in city_name){
temp <- tibble(lon = NA)
# geolocate until found or tried 5 times
attempt <- 0 # set attempt counter
while(is.na(temp$lon) & attempt < 5) {
temp <- geocode(c, source = "dsk")
attempt <- attempt + 1
cat(c, attempt, ifelse(!is.na(temp[[1]]), "success", "failure"), "\n") # print status
Sys.sleep(runif(1)) # sleep for random 0-1 seconds
}
# write to dataframe
cities[cities$city == c, -1] <- temp
}Now, Taras wrote a very convenient piece of code to generate the dotted world map, which I borrowed from his blog:
### dot data -------------------------------------------------------------------
# generate worldwide dots
lat <- data_frame(lat = seq(-90, 90, by = 1))
lon <- data_frame(lon = seq(-180, 180, by = 1))
dots <- merge(lat, lon, all = TRUE)
# exclude water-based dots
dots %>%
mutate(country = map.where("world", lon, lat),
lakes = map.where("lakes", lon, lat)) %>%
filter(!is.na(country) & is.na(lakes)) %>%
select(-lakes) ->
dotsWith both the dot data and the cities’ geocode() coordinates ready, it is high time to visualize the map. Note that I use one geom_point() layer to plot the dots, small and black, and another layer to plot the cities data in transparent red. Taras added a third layer for the cities he had actually lived in; I purposefully did not as I have only lived in the Netherlands and the UK. Note that I again use the convenient here::here() function to save the plot in my current project folder.
### visualize ------------------------------------------------------------------
# plot the data
dots %>% ggplot(aes(x = lon, y = lat)) +
geom_point(col = "black", size = 0.25) +
geom_point(data = cities, col = "red", size = 3, alpha = 0.7) +
theme_void() +
theme(
panel.background = element_rect(fill = "#006994"),
plot.background = element_rect(fill = "#006994")
) -> dot_map
# save plot
ggsave(here("worlmap_dots.png"), dot_map,
dpi = 600, width = 8, height = 4.5)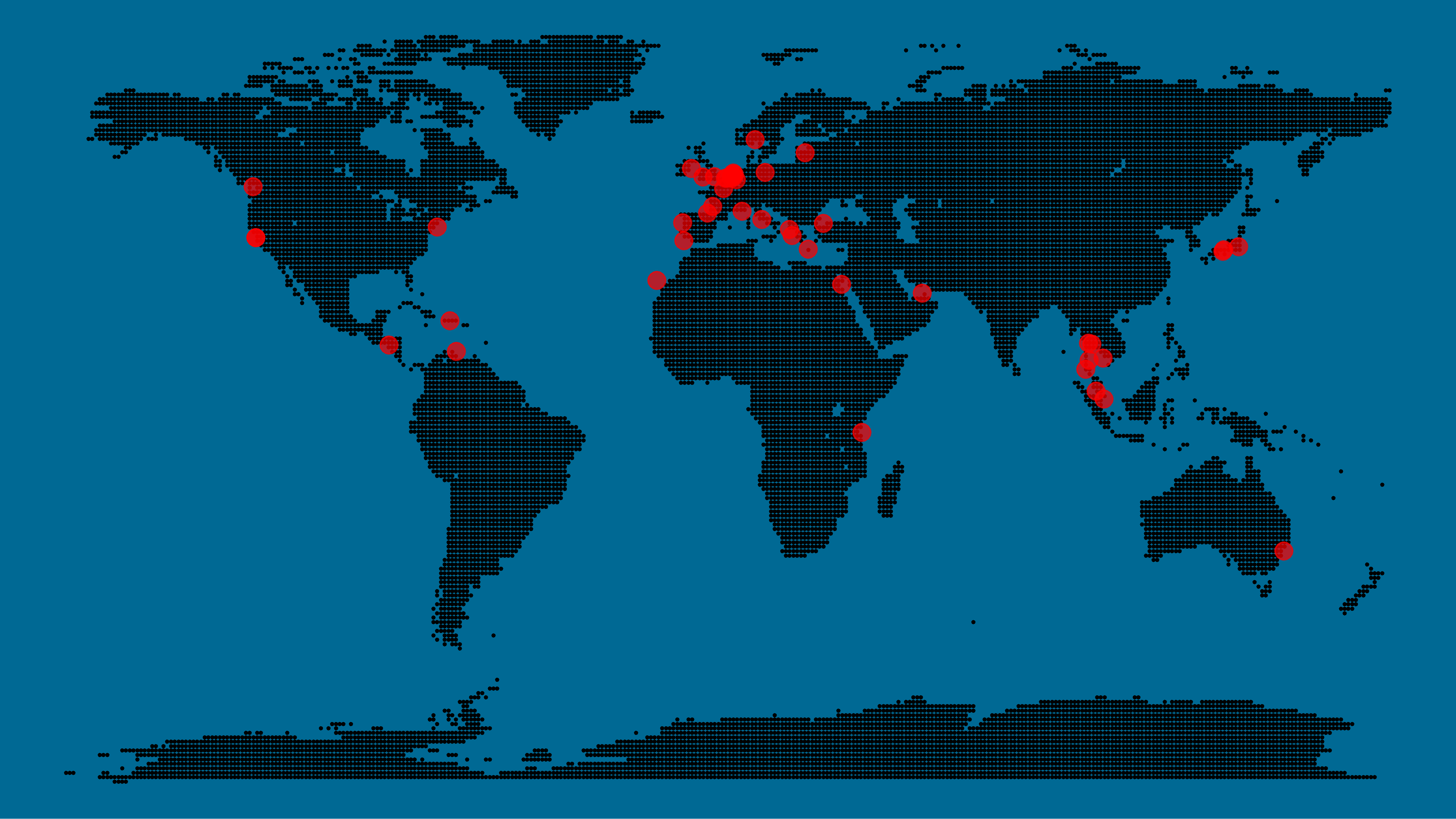
I very much like the look of this map and I’d love to see what innovative, other applications you guys can come up with. To copy the code, please look here on RPubs. Do share your personal creations and also remember to take a look at Taras original blog!