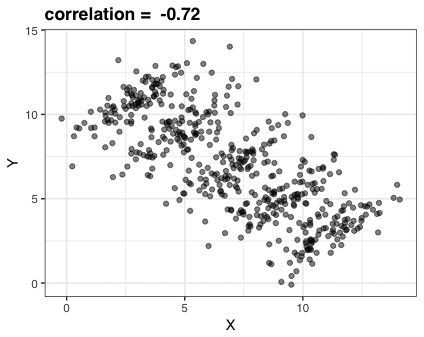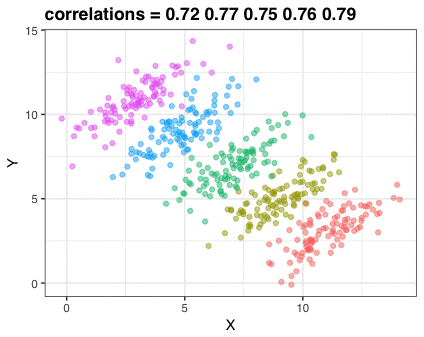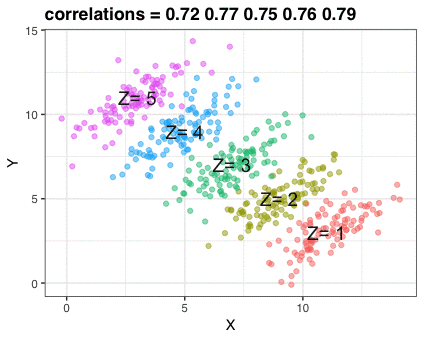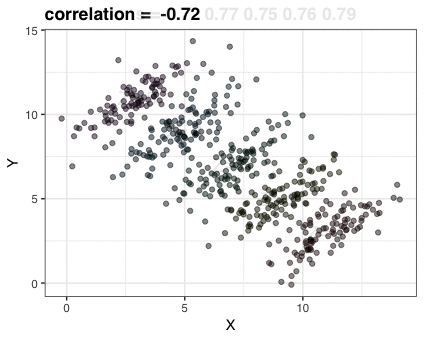
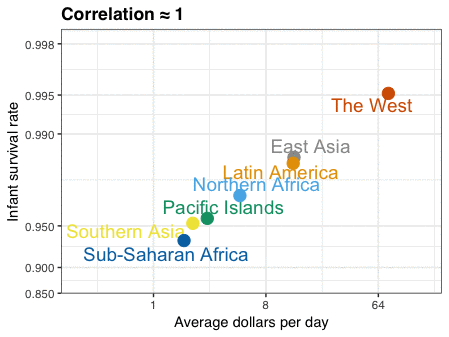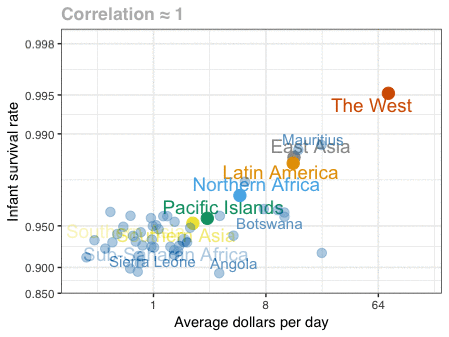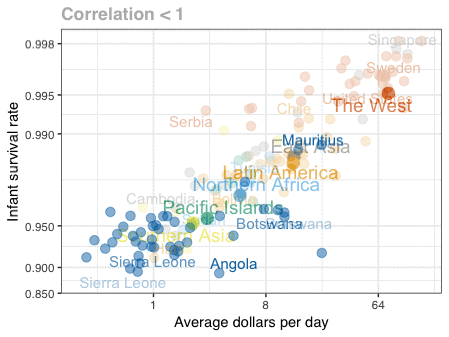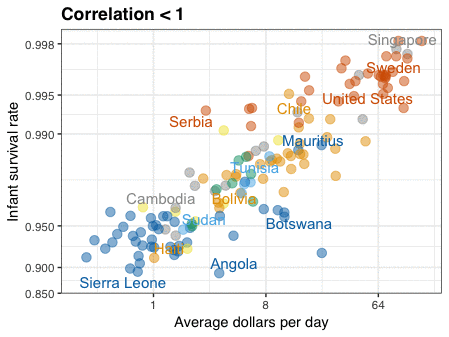
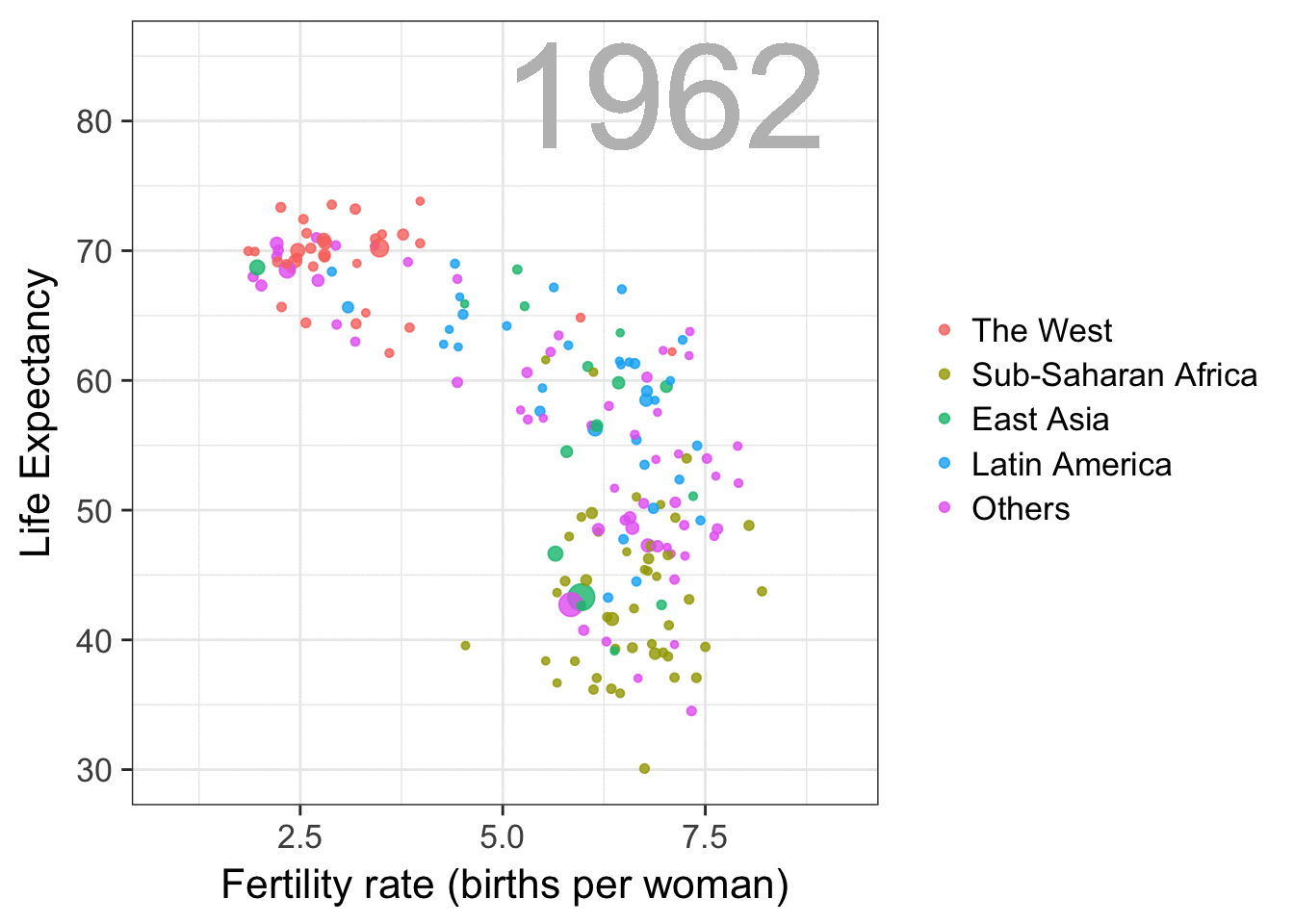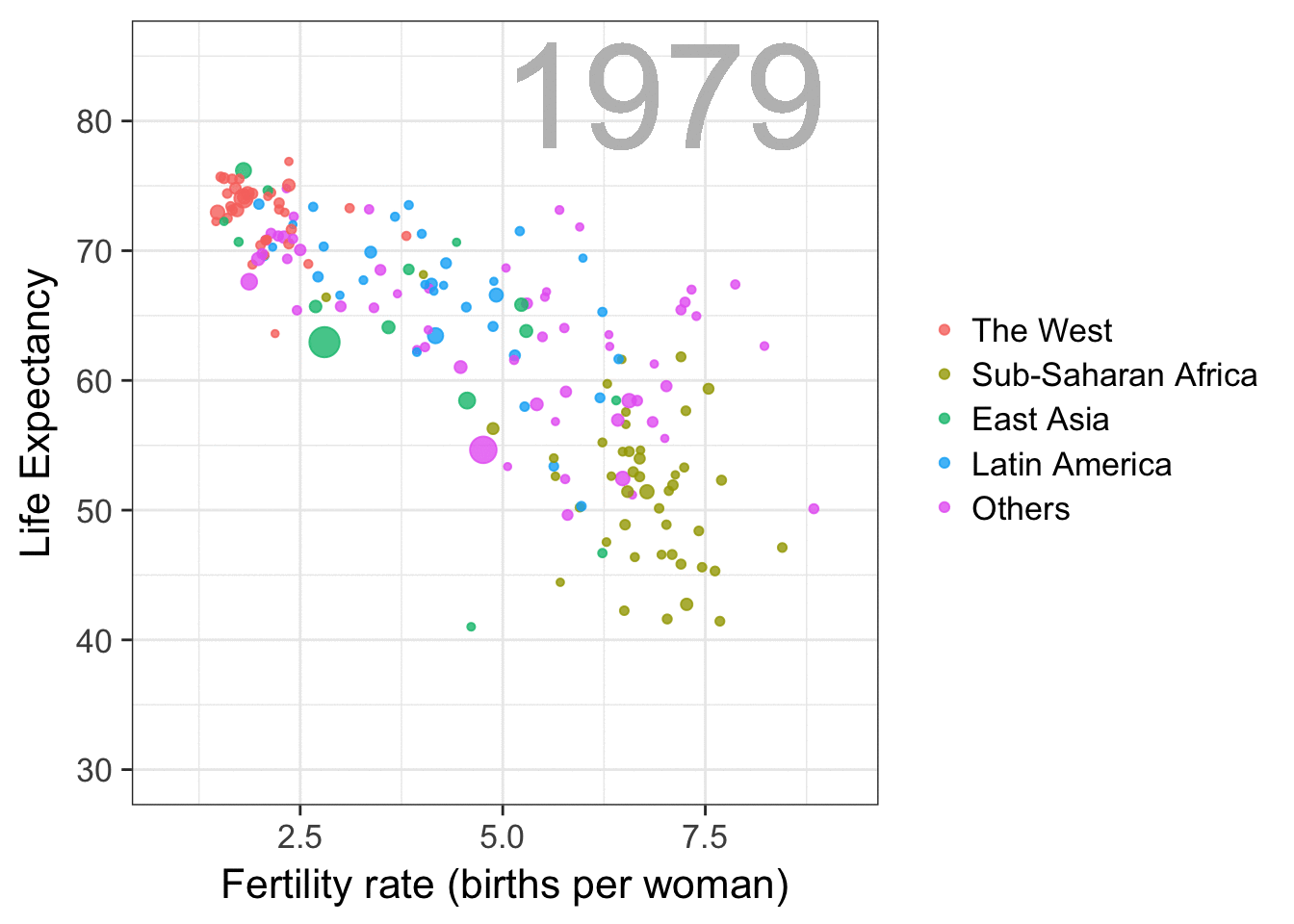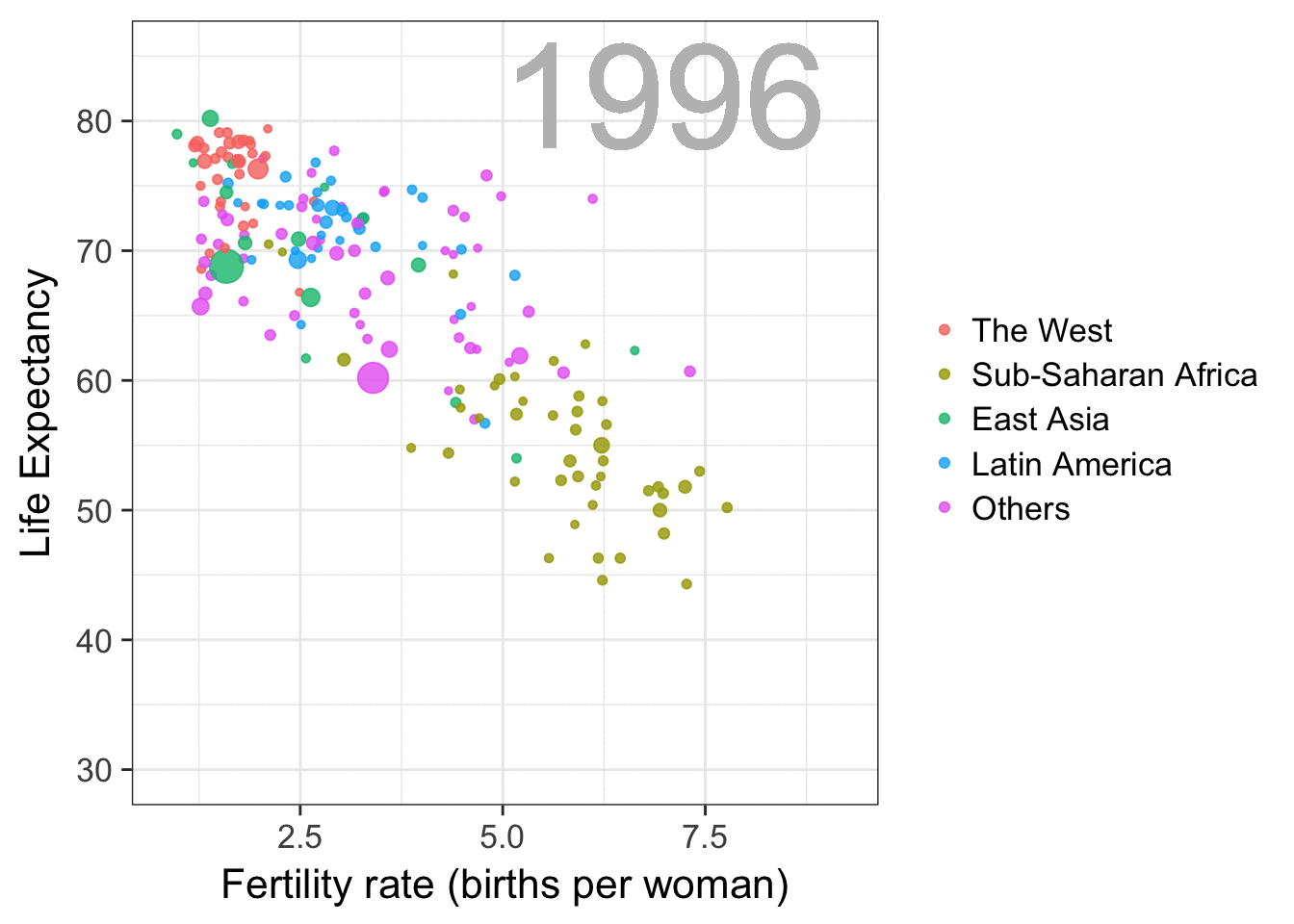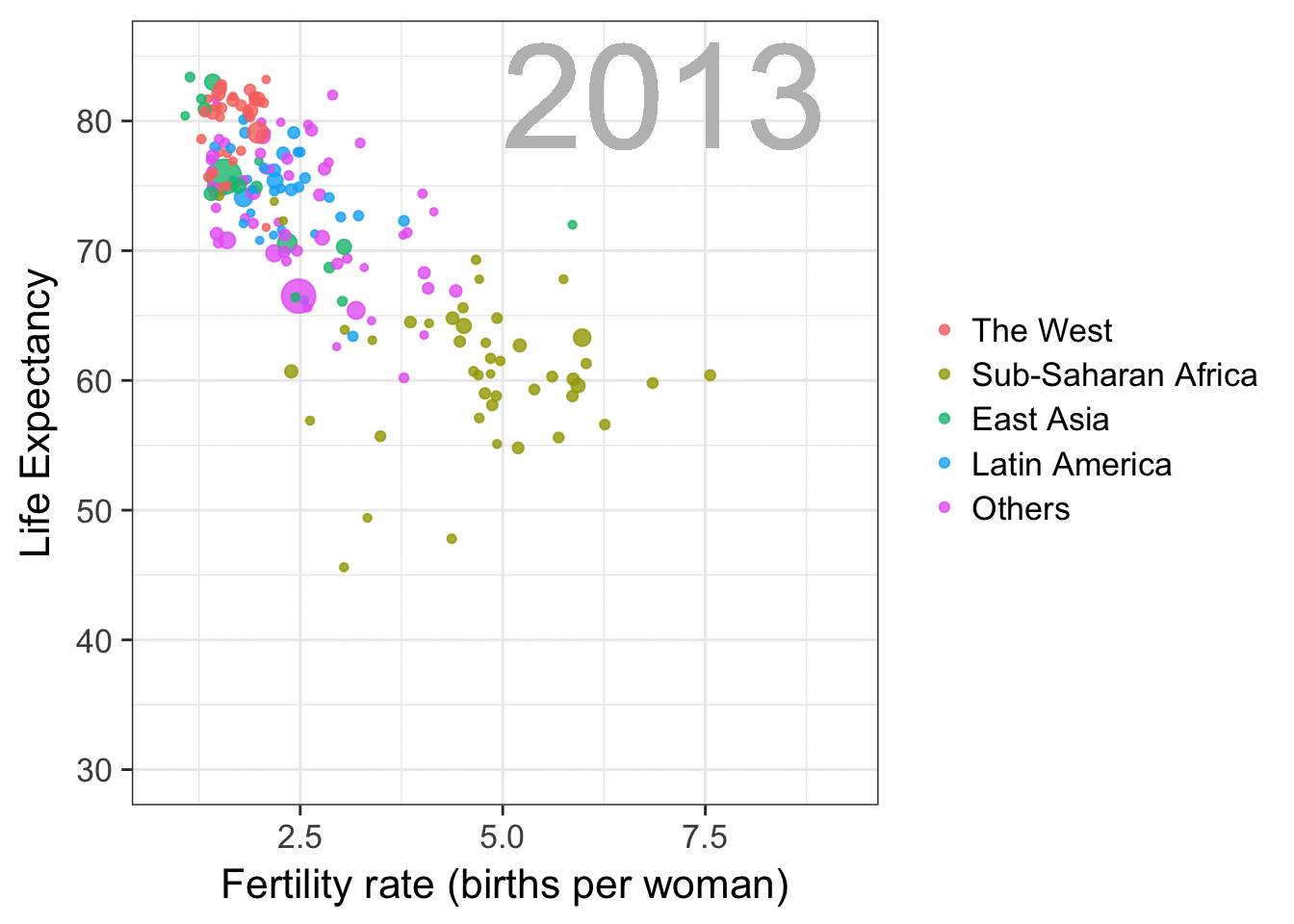
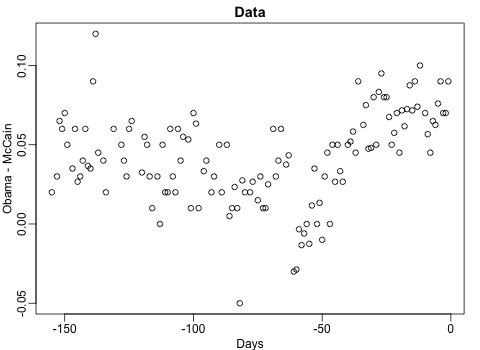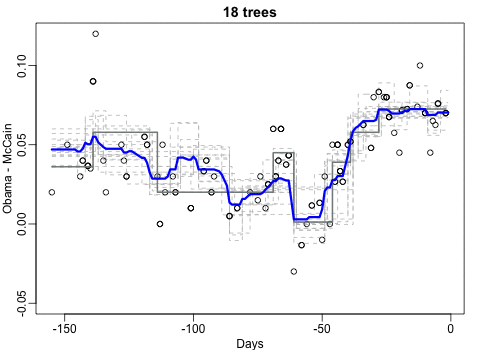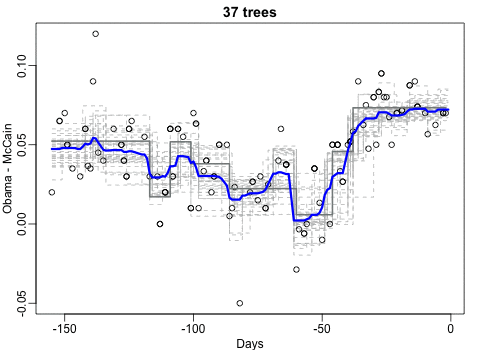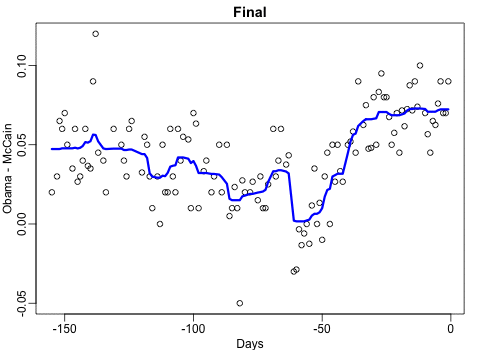
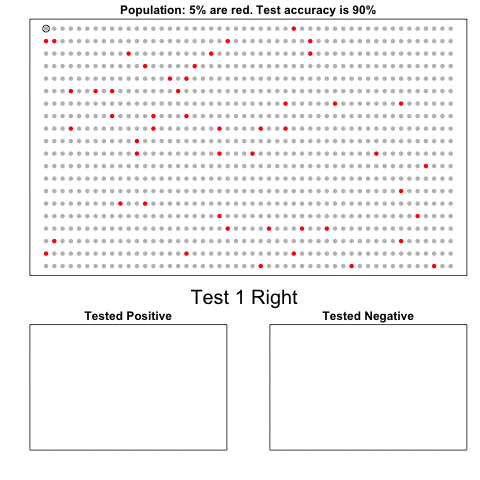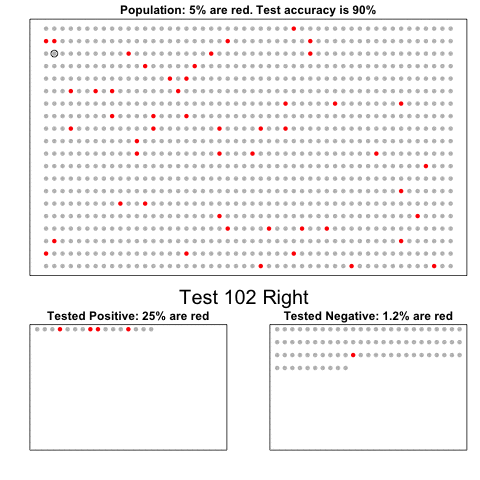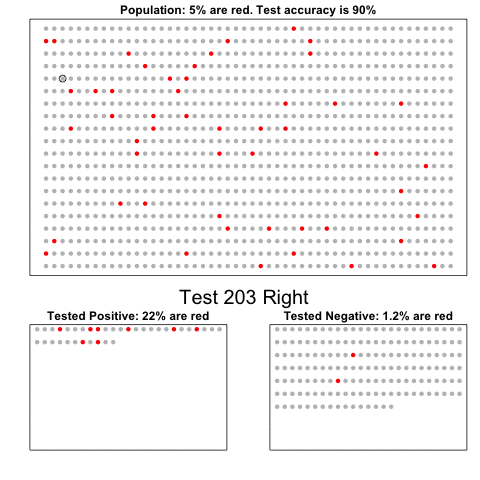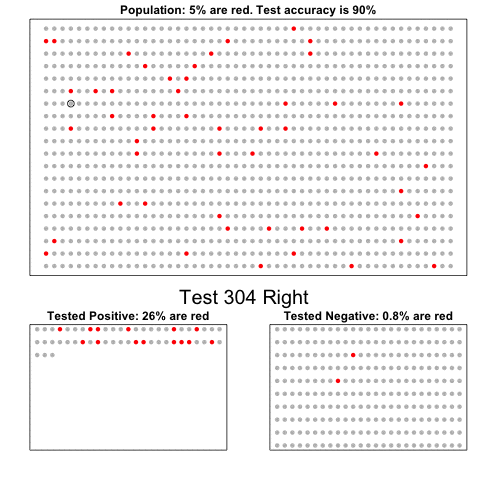
Nathan Yau – the guy behind the wonderful visualizations of FlowingData.com – has been looking into job market data more and more lately. For his latest project, he took data of the Current Population Survey (2011-2016) a survey run by the US Census Bureau and Bureau of Labor Statistics. This survey covers many topics, but Nathan specifically looked into people’s current occupation and what they were doing the year before.
For his first visualization, Nathan examined the percentage of people switching jobs (a statistic he dubs the switching rate). Only occupations with over 100 survey responses are shown:

Next Nathan looked into job moves within job categories, as he hypothesizes that people who decide to switch jobs look for something similar.

The above results in the main question of the blog: Given you have a certain job, what are the possible jobs to switch to? The following interactive bar charts gives the top 20 jobs people with a specific job switched to. In the original blog you can specify a job to examine or ask for a random suggestion. I searched for “analyst” in the picture below, and apparently HR professional would be a good next challenge.

Nathan got the data here, prepared it in R, and used d3.js for the visualizations. I’d have loved to see this data in a network-kind of flowchart or a Markov-chain. For more of Nathan’s work, please visit his FlowingData website.