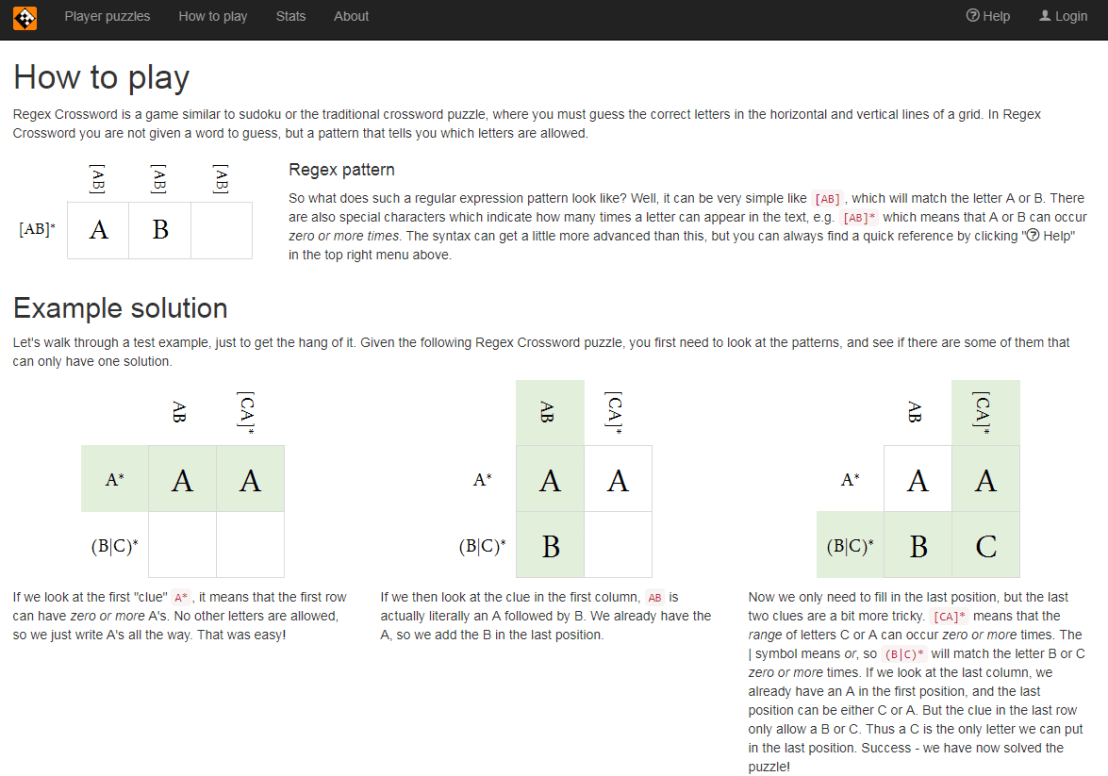
Searching and applying to jobs can be a costly activity, requiring many hours upon hours of perfecting your motivation letter and CV. Hence, it can be very frustrating to get ghosted (not receiving a reply) for a job. Luckily, Talent Works is able to give us some general tips when it comes to improving the success of your applications. You might remember them from their Interactive Map of the US Job Market.
Using a sample of about 1600 job applications, Talent Works recently conducted all kinds of statistical analyses to look at the hiring process. For instance, they examined the time it takes to get from the application stage to your first day on the job. Split out for various jobs, it seems Mechanical Engineers spend quite a while in the interview stage whereas Software developers are put to work within three weeks.

In a different analysis, Talent Works examined how to minimize your risk of getting ghosted on a job application. For instance, they found that during the “Golden Hours” (the first 96 hours after a job gets posted), your chances of getting an invitation for an interview are up to 8 times higher than afterwards.

Based on the above they come to the following three timeframes in the application cycle:
- “Golden Hours”: Applications submitted between 2-4 days after a job is posted have the highest chance of getting an interview. Not only is there a difference, there’s a big difference: you have up to an 8x higher chance of getting an interview during this period, even if you’re submitting the same application.
- Twilight Zone: Chances quickly decrease from OK to really bad: every day you wait after the “Golden Hours” reduces your chances by 28%. The longer you wait, the higher the risk that employers have already checked their inboxes and setup interviews with candidates that met their “good enough”-bar.
- Resume Blackhole: According to Talent.Works it’s nearly not worth applying after 10 days. On average, job applications during this phase have a meager ~1.5% of getting an interview. Put another way, if you send out 50 job applications, you might hear back from one (if you’re lucky).
Next, Talent.Works investigated on a more granular level what would then be the best time to apply for a job.This resulted in the following figure

Again, they provide a summary of their conclusions:
- The best time to apply for a job is between 6am and 10am. During this time, you have an 13% chance of getting an interview.
- After that morning window, your interview odds start falling by 10% every 30 minutes. If you’re late, you’re going to pay dearly.
- There’s a brief reprieve during lunchtime, where your odds climb back up to 11% at around 12:30pm but then start falling precipitously again.
- The single-worst time to apply for a job is after work — if you apply at 7:30pm, you have less than a 3% chance of getting an interview.
If you want to see more, please visit Talent.Works. Here, you can let them process your CV and help you improve your hiring chances (see also this blog post).