By adjusting the three elements in this simple framework, you can build any type of machine learning program.
In the tutorial, Eric shows you how to implement this same framework in Python (using jax) and implement linear regression, logistic regression, and artificial neural networks all in the same way (using gradient descent).
I can’t even begin to explain it as well as Eric does himself, so I highly recommend you watch and code along with the Youtube tutorial (~1 hour):
Have you ever wondered what goes on behind the scenes of a deep learning framework? Or what is going on behind that pre-trained model that you took from Kaggle? Then this tutorial is for you! In this tutorial, we will demystify the internals of deep learning frameworks – in the process equipping us with foundational knowledge that lets us understand what is going on when we train and fit a deep learning model. By learning the foundations without a deep learning framework as a pedagogical crutch, you will walk away with foundational knowledge that will give you the confidence to implement any model you want in any framework you choose.
Several Chinese Ph.D. students wrote a PyTorch program that can turn your holiday pictures into 3D sceneries. They call it 3D photo inpainting. Here are some examples
And here’s the new method compares to previous techniques:
We propose a method for converting a single RGB-D input image into a 3D photo, i.e., a multi-layer representation for novel view synthesis that contains hallucinated color and depth structures in regions occluded in the original view. We use a Layered Depth Image with explicit pixel connectivity as underlying representation, and present a learning-based inpainting model that iteratively synthesizes new local color-and-depth content into the occluded region in a spatial context-aware manner. The resulting 3D photos can be efficiently rendered with motion parallax using standard graphics engines. We validate the effectiveness of our method on a wide range of challenging everyday scenes and show fewer artifacts when compared with the state-of-the-arts.
Google Brain researchers published this amazing paper, with accompanying GIF where they show the true power of AutoML.
AutoML stands for automated machine learning, and basically refers to an algorithm autonomously building the best machine learning model for a given problem.
This task of selecting the best ML model is difficult as it is. There are many different ML algorithms to choose from, and each of these has many different settings ([hyper]parameters) you can change to optimalize the model’s predictions.
For instance, let’s look at one specific ML algorithm: the neural network. Not only can we try out millions of different neural network architectures (ways in which the nodes and lyers of a network are connected), but each of these we can test with different loss functions, learning rates, dropout rates, et cetera. And this is only one algorithm!
In their new paper, the Google Brain scholars display how they managed to automatically discover complete machine learning algorithms just using basic mathematical operations as building blocks. Using evolutionary principles, they have developed an AutoML framework that tailors its own algorithms and architectures to best fit the data and problem at hand.
This is AI research at its finest, and the results are truly remarkable!
Sometimes I find these AI / programming hobby projects that I just wished I had thought of…
Will Stedden combined OpenAI’s GPT-2 deep learning text generation model with another deep-learning language model by Google called BERT (Bidirectional Encoder Representations from Transformers) and created an elaborate architecture that had one purpose: posting the best replies on Reddit.
The architecture is shown at the end of this post — copied from Will’s original bloghere. Moreover, you can read this post for details regarding the construction of the system. But let me see whether I can explain you what it does in simple language.
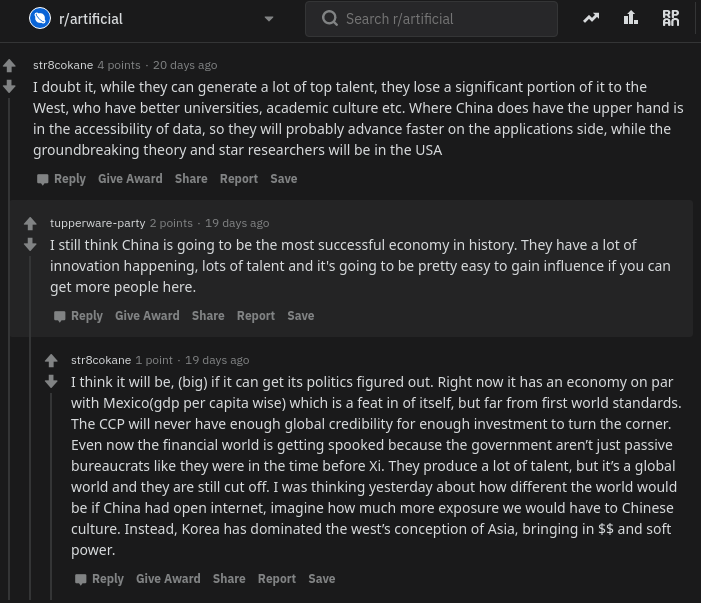
The below is what a Reddit comment and reply thread looks like. We have str8cokane making a comment to an original post (not in the picture), and then tupperware-party making a reply to that comment, followed by another reply by str8cokane. Basically, Will wanted to create an AI/bot that could write replies like tupperware-party that real people like str8cokane would not be able to distinguish from “real-people” replies.
Note that with 4 points, str8cokane‘s original comments was “liked” more than tupperware-party‘s reply and str8cokane‘s next reply, which were only upvoted 2 and 1 times respectively.
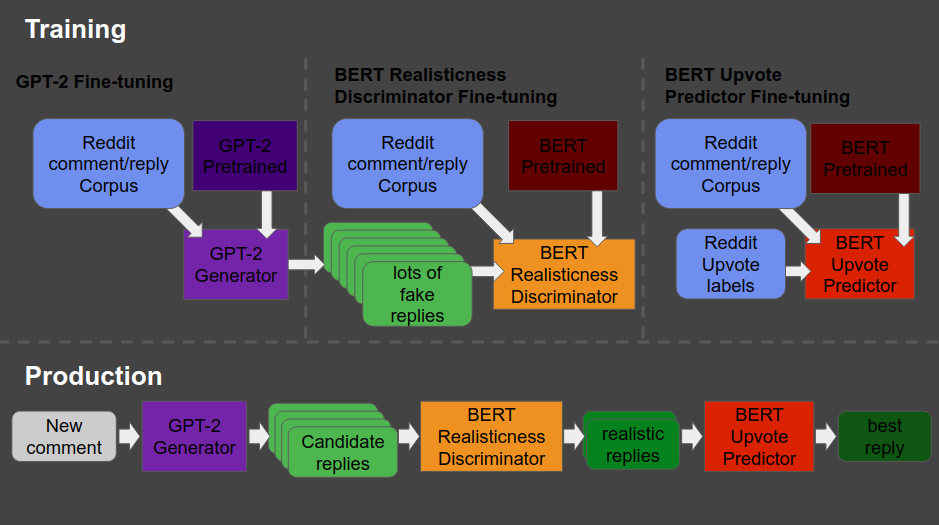
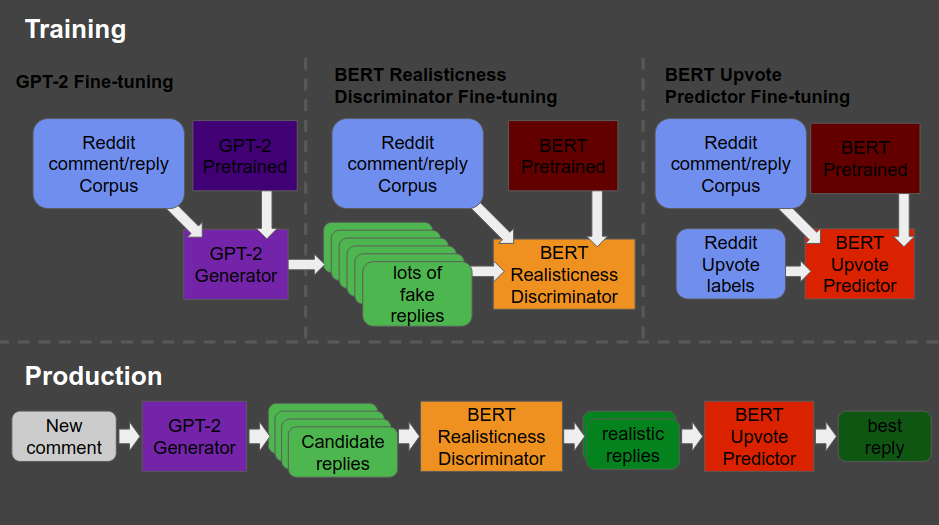
So here’s what the final architecture looks like, and my attempt to explain it to you.
Basically, we start in the upper left corner, where Will uses a database (i.e. corpus) of Reddit comments and replies to fine-tune a standard, pretrained GPT-2 model to get it to be good at generating (red: “fake”) realistic Reddit replies.
Next, in the upper middle section, these fake replies are piped into a standard, pretrained BERT model, along with the original, real Reddit comments and replies. This way the BERT model sees both real and fake comments and replies. Now, our goal is to make replies that are undistinguishable from real replies. Hence, this is the task the BERT model gets. And we keep fine-tuning the original GPT-2 generator until the BERT discriminator that follows is no longer able to distinguish fake from real replies. Then the generator is “fooling” the discriminator, and we know we are generating fake replies that look like real ones! You can find more information about such generative adversarial networks here.
Next, in the top right corner, we fine-tune another BERT model. This time we give it the original Reddit comments and replies along with the amount of times they were upvoted (i.e. sort of like likes on facebook/twitter). Basically, we train a BERT model to predict for a given reply, how much likes it is going to get.
Finally, we can go to production in the lower lane. We give a real-life comment to the GPT-2 generator we trained in the upper left corner, which produces several fake replies for us. These candidates we run through the BERT discriminator we trained in the upper middle section, which determined which of the fake replies we generated look most real. Those fake but realistic replies are then input into our trained BERT model of the top right corner, which predicts for every fake but realistic reply the amount of likes/upvotes it is going to get. Finally, we pick and reply with the fake but realistic reply that is predicted to get the most upvotes!
What Will’s final architecture, combining GPT-2 and BERT, looked like (via bonkerfield.org)
The results are astonishing! Will’s bot sounds like a real youngster internet troll! Do have a look at the original blog, but here are some examples. Note that tupperware-party — the Reddit user from the above example — is actually Will’s AI.
Will ends his blog with a link to the tutorial if you want to build such a bot yourself. Have a try!
Moreover, he also notes the ethical concerns:
I know there are definitely some ethical considerations when creating something like this. The reason I’m presenting it is because I actually think it is better for more people to know about and be able to grapple with this kind of technology. If just a few people know about the capacity of these machines, then it is more likely that those small groups of people can abuse their advantage.
I also think that this technology is going to change the way we think about what’s important about being human. After all, if a computer can effectively automate the paper-pushing jobs we’ve constructed and all the bullshit we create on the internet to distract us, then maybe it’ll be time for us to move on to something more meaningful.
If you think what I’ve done is a problem feel free to email me , or publically shame me on Twitter.
Tait Brown was annoyed at the Victoria Police who had spent $86 million Australian dollars on developing the BlueNet system which basically consists of an license-plate OCR which crosschecks against a car theft database.
Tait was so disgruntled as he thought he could easily replicate this system without spending millions and millions of tax dollars. And so he did. In only 57 lines of JavaScript, though, to be honest, there are many more lines of code hidden away in abstraction and APIs…
Anyway, he built a system that can identify license plates, read them, and should be able to cross check them with a criminal database.















{kind=link}