
I found this interesting blog by Guilherme Duarte Marmerola where he shows how the predictions of algorithmic models (such as gradient boosted machines, or random forests) can be calibrated by stacking a logistic regression model on top of it: by using the predicted leaves of the algorithmic model as features / inputs in a subsequent logistic model.
When working with ML models such as GBMs, RFs, SVMs or kNNs (any one that is not a logistic regression) we can observe a pattern that is intriguing: the probabilities that the model outputs do not correspond to the real fraction of positives we see in real life.
Guilherme’s in his blog post
This is visible in the predictions of the light gradient boosted machine (LGBM) Guilherme trained: its predictions range only between ~ 0.45 and ~ 0.55. In contrast, the actual fraction of positive observations in those groups is much lower or higher (ranging from ~ 0.10 to ~0.85).
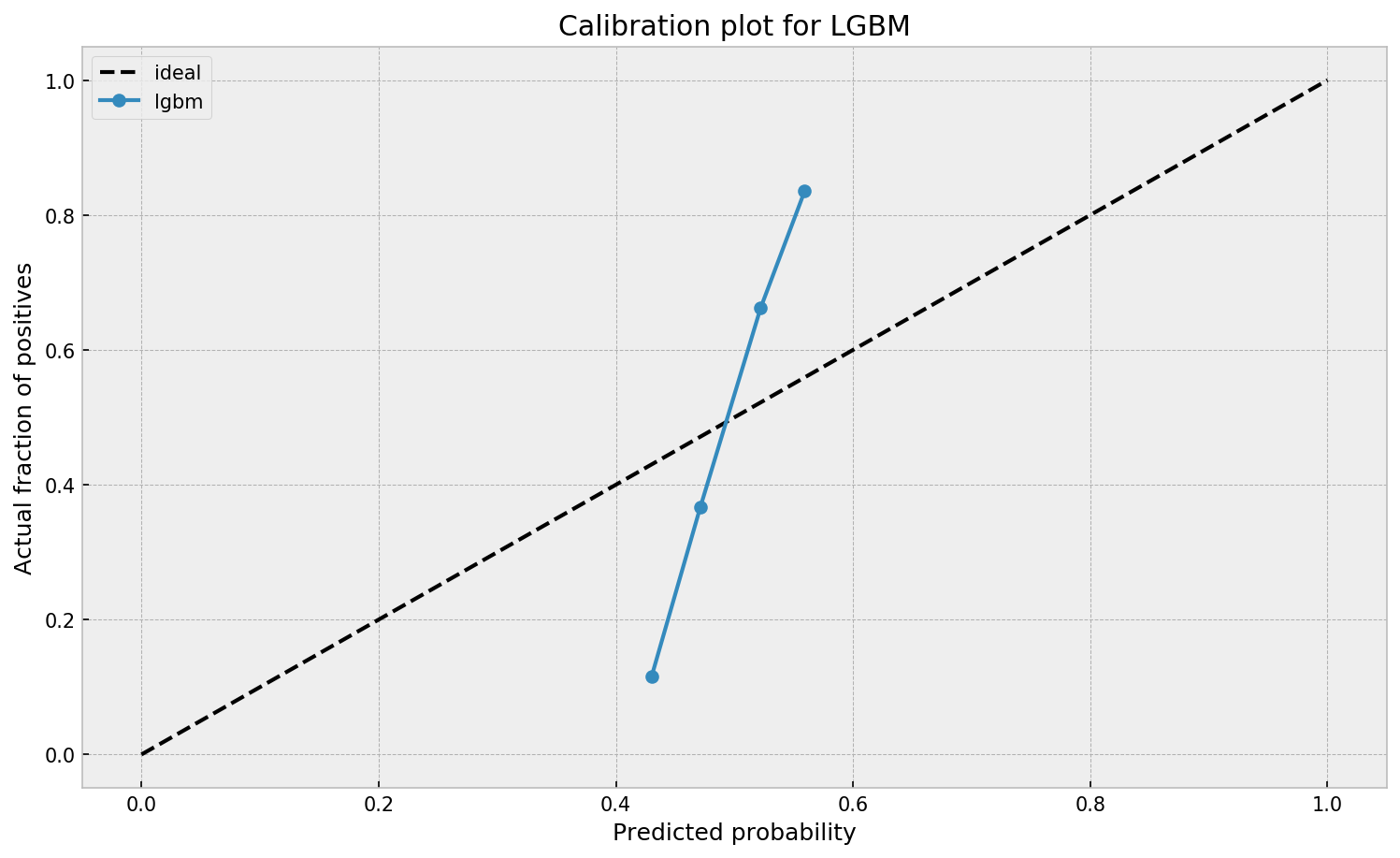
Motivated by sklearn’s topic Probability Calibration and the paper Practical Lessons from Predicting Clicks on Ads at Facebook, Guilherme continues to show how the output probabilities of a tree-based model can be calibrated, while simultenously improving its accuracy.
I highly recommend you look at Guilherme’s code to see for yourself what’s happening behind the scenes, but basically it’s this:
- Train an algorithmic model (e.g., GBM) using your regular features (data)
- Retrieve the probabilities GBM predicts
- Retrieve the leaves (end-nodes) in which the GBM sorts the observations
- Turn the array of leaves into a matrix of (one-hot-encoded) features, showing for each observation which leave it ended up in (1) and which not (many 0’s)
- Basically, until now, you have used the GBM to reduce the original features to a new, one-hot-encoded matrix of binary features
- Now you can use that matrix of new features as input for a logistic regression model predicting your target (Y) variable
- Apparently, those logistic regression predictions will show a greater spread of probabilities with the same or better accuracy
Here’s a visual depiction from Guilherme’s blog, with the original GBM predictions on the X-axis, and the new logistic predictions on the Y-axis.
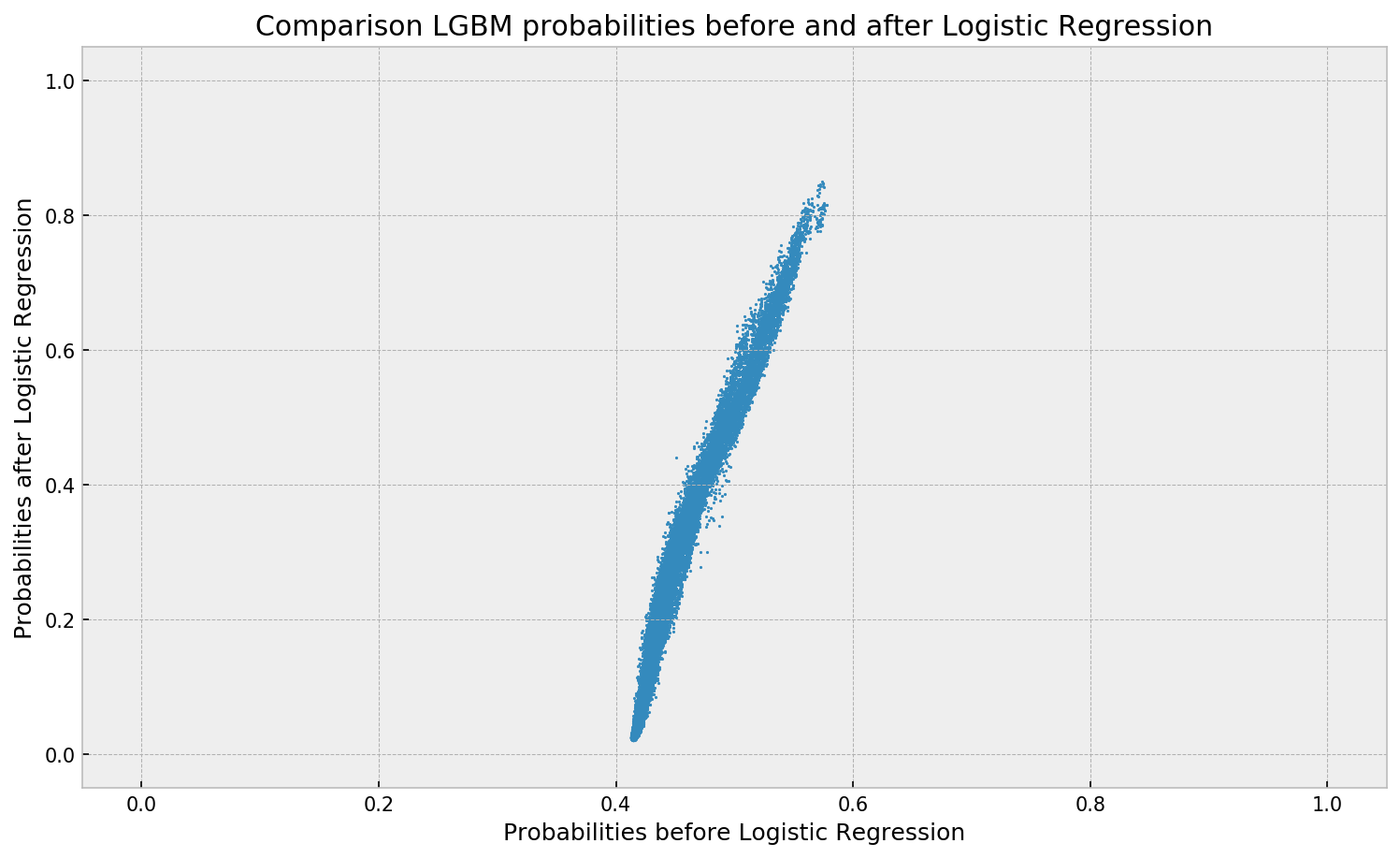
As you can see, you retain roughly the same ordering, but the logistic regression probabilities spread is much larger.
Now according to Guilherme and the Facebook paper he refers to, the accuracy of the logistic predictions should not be less than those of the original algorithmic method.
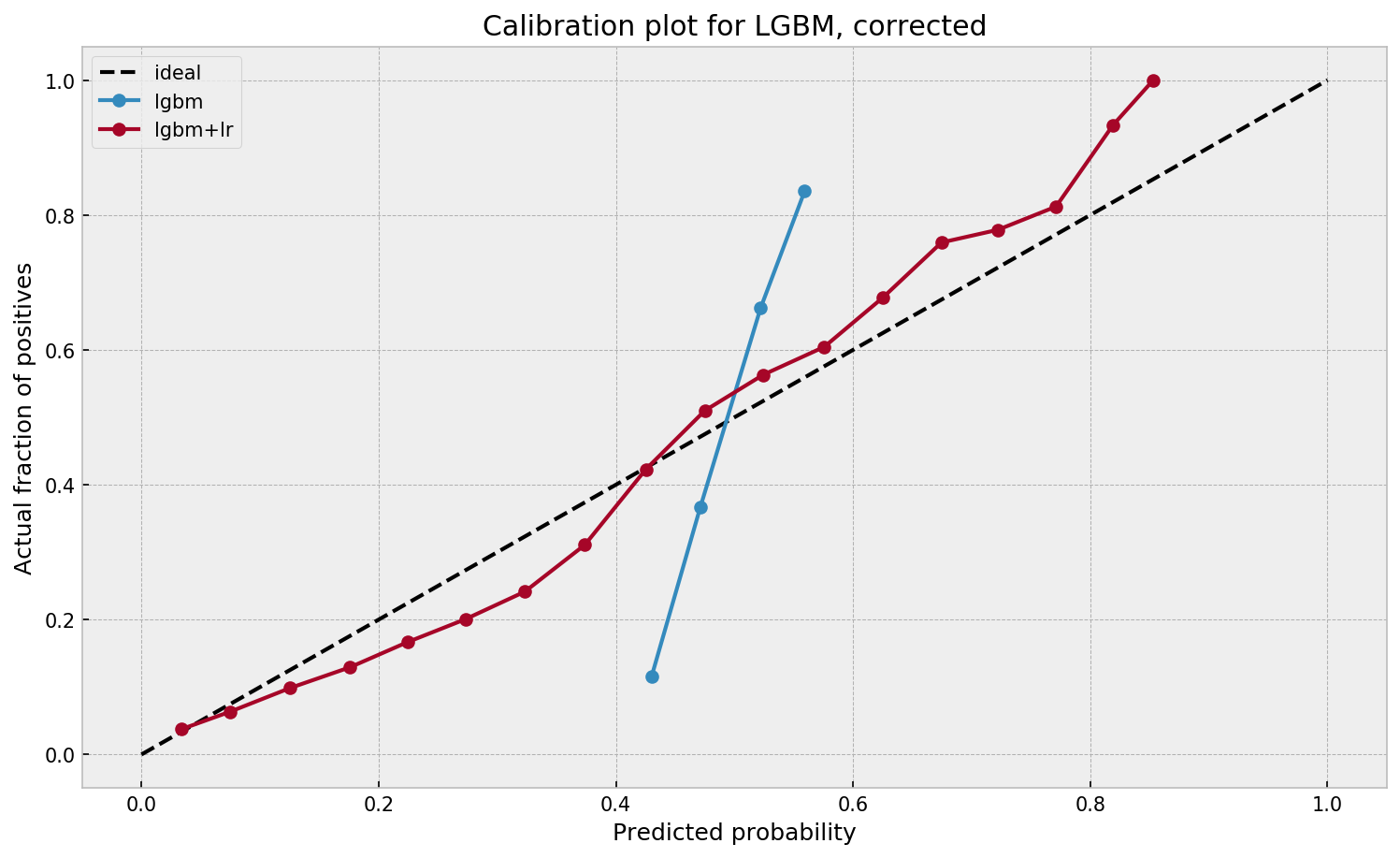
Much better. The calibration plot of
Guilherme in https://gdmarmerola.github.io/probability-calibration/lgbm+lris much closer to the ideal. Now, when the model tells us that the probability of success is 60%, we can actually be much more confident that this is the true fraction of success! Let us now try this with the ET model.
In his blog, Guilherme shows the same process visually for an Extremely Randomized Trees model, so I highly recommend you read the original article. Also, you can find the complete code on his GitHub.


![indico_features_img_callout_small-1024x973[1].jpg](https://paulvanderlaken.com/wp-content/uploads/2017/08/indico_features_img_callout_small-1024x9731.jpg)

