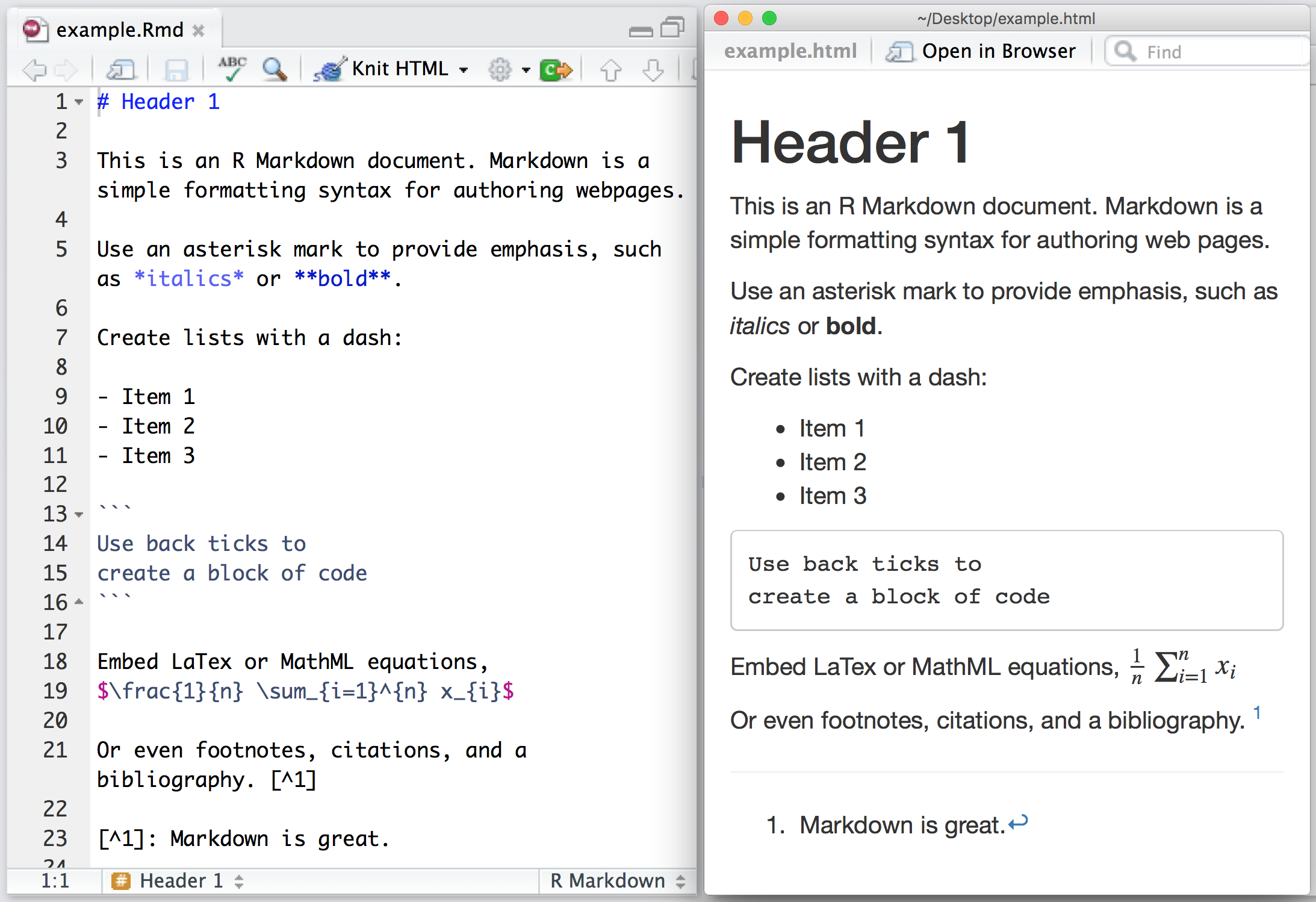
Yan Holtz recently created a neat little overview of handy R Markdown tips and tricks that improve the appearance of output documents. He dubbed this overview Pimp my RMD. Have a look, it’s worth it!
Today I learned about dygraphs, a fast, flexible open source JavaScript charting library. As everything in JavaScript, the charts produced by dygraphs integrate completely in the webbrowser and are thus very functional and interactive. See, for instance, the below where the graph highlights the y-axis value for both time series in the graph based on the x-axis value of my mouse location (January 24 2009). Very cool!
Fortunately, I do know my way around R, and of course someone had already integrated dypgrahs in R in the form of the dygraphs R package. It works like a charm!
Why do groups of people act smart, dumb, kind, or cruel? People behave in strange ways, particularly when they are able to influence one another. Both good and bad things can happen when people interact and behave in network structures. On the bright side, you must be familiar with the wisdom of the crowd, where the aggregated knowledge of a group is more valuable than its sum? Ensemble algorithms – like random forest analysis – rely on this positive principle.
On the dark side, are you familiar with the phenomenon called the tragedy of the commons, where shared resource-systems collapse because individuals behave in their self-interest? Or psychological phenomena such as groupthink, where groups of people make irrational decisions due to social issues? The recent spread of fake news and misinformation is also stimulated by network interactions. In these cases, we could speak of the madness of the crowd.
Nicky Case made a great interactive walkthrough explaining why and when networks of people become wise or mad. You are tasked to change and simulate network interactions while Nicky explains concepts such as (complex) contagion, the majority illusion paradox, bonding and bridging, and small world networks. In the references, Nicky provides links to scientific papers explaining these concepts in more detail. I highly suggest you check out her website here.
Screenshot of one of the explanations/simulations Nicky offers.
If you have ever programmed in R, you are probably familiar with the Grammar of Graphics due to ggplot2. You can read more about the Grammar of Graphics here, but the general idea behind it is that visualizations can be build up through various layers, each of which have certain characteristics (aesthetics in ggplot2).
This post is not about ggplot2 nor specifically the Grammar of Graphics, but rather a summary of the official release of Vega-Lite 2, a high-level language for rapidly creating interactive visualizations which you might know from the R-package ggvis.
Vega-Lite has four operators to compose charts: layer, facet, concat and repeat. Layer stacks charts on top of each other in an orderly fashion. Facet divides and charts the data into groups. Concat combines multiple charts into dashboard layouts and, finally, repeat concatenate charts. Most importantly is that these operators can be combined! The example below compares weather data in New York and Seattle, layering data for individual years and averages within a repeated template for different measurements.
A layered and reapeted Vega-Lite graph of weather data
Vega-Lite 2 is especially useful because of the included interaction options. Programmers can specify how users can interactive select the data in their visualizations (e.g., a point or interval selection), along with possible transformations. With these interactions, users can for instance filter data, highlight points, or pan or zoom a plot. The plot below uses an interval selection, which causes the chart to include an interactive brush (shown in grey). The brush selection parameterizes the red guideline, which visualizes the average value within the selected interval.
An interactive moving average in Vega-Lite 2. Try it out!
However, this is not all! When multiple visualizations are combined in a dashboard, interactive selections can apply to all. Below, you see an interval selection being applied over a set of histograms. As a viewer adjusts the selection, they can immediately see how the other distributions change in response.
A crossfilter interaction in Vega-Lite 2. Try it out!
Jack Zhao from Small Multiples – a multidisciplinary team of data specialists, designers and developers – retrieved the Language Spoken at Home (LANP) data from the 2016 Census and turned it into a dot density map that vividly shows how people from different cultures coexist (or not) in ultra high resolution (using Python, englewood library, QGIS, Carto). Each colored dot in the visualizations below represents five people from the same language group in the area. Highly populated areas have a higher density of dots; while language diversity is shown through the number of different colors in the given area.
Good news: the maps are interactive! Here’s Sydney:
Eastern Asian: Chinese, Japanese, Korean, Other Eastern Asian Languages
Southeast Asian: Burmese and Related Languages, Hmong-Mien, Mon-Khmer, Tai, Southeast Asian Austronesian Languages, Other Southeast Asian Languages
Southern Asian: Dravidian, Indo-Aryan, Other Southern Asian Languages
Southwest And Central Asian: Iranic, Middle Eastern Semitic Languages, Turkic, Other Southwest and Central Asian Languages
Northern European: Celtic, English, German and Related Languages, Dutch and Related Languages, Scandinavian, Finnish and Related Languages
Southern European: French, Greek, Iberian Romance, Italian, Maltese, Other Southern European Languages
Eastern European: Baltic, Hungarian, East Slavic, South Slavic, West Slavic, Other Eastern European Languages
Australian Indigenous: Arnhem Land and Daly River Region Languages, Yolngu Matha, Cape York Peninsula Languages, Torres Strait Island Languages, Northern Desert Fringe Area Languages, Arandic, Western Desert Languages, Kimberley Area Languages, Other Australian Indigenous Languages
The people at Predictive Talent, Inc. took a sample of 23.4 million job postings from 5,200+ job boards and 1,800+ cities around the US. They classified these jobs using the BLS Standard Occupational Classification tree and identified their primary work locations, primary job roles, estimated salaries, and 17 other job search-related characteristics. Next, they calculated five metrics for each role and city in order to identify the 123 biggest job shortages in the US:
Monthly Demand (#): How many people are companies hiring every month? This is simply the number of unique jobs posted every month.
Unmet Demand (%): What percentage of jobs did companies have a hard time filling? Details aside, basically, if a company re-posts the same job every week for 6 weeks, one may assume that they couldn’t find someone for the first 5 weeks.
Salary ($): What’s the estimated salary for these jobs near this city? Using 145,000+ data points from the federal government and proprietary sources, along with salary information parsed from jobs themselves, they estimated the median salary for similar jobs within 100 miles of the city.
Delight (#): On a scale of 1 (least) to 10 (most delight), how easy should the job search be for the average job-seeker? This is basically the opposite of Agony.
The end result is this amazing map of the job market in the U.S, which you can interactively explore here to see where you could best start your next job hunt.