I really like generative art, or so-called algorithmic art. Basically, it means you take a pattern or a complex system of rules, and apply it to create something new following those patterns/rules.
When I finished my PhD, I got a beautiful poster of where the k-nearest neighbors algorithms was used to generate a set of connected points.
As we recently moved into our new house, I decided I wanted to have a brother for the knn-poster. So I did some research in algorithms I wanted to use to generate a painting. I found some very cool ones, of which I unforunately can’t recollect the artists anymore:
Note: these are NOT mine
However, I preferred to make one myself. So we again turned to the work of the author that made the knn-poster: Marcus Volz.
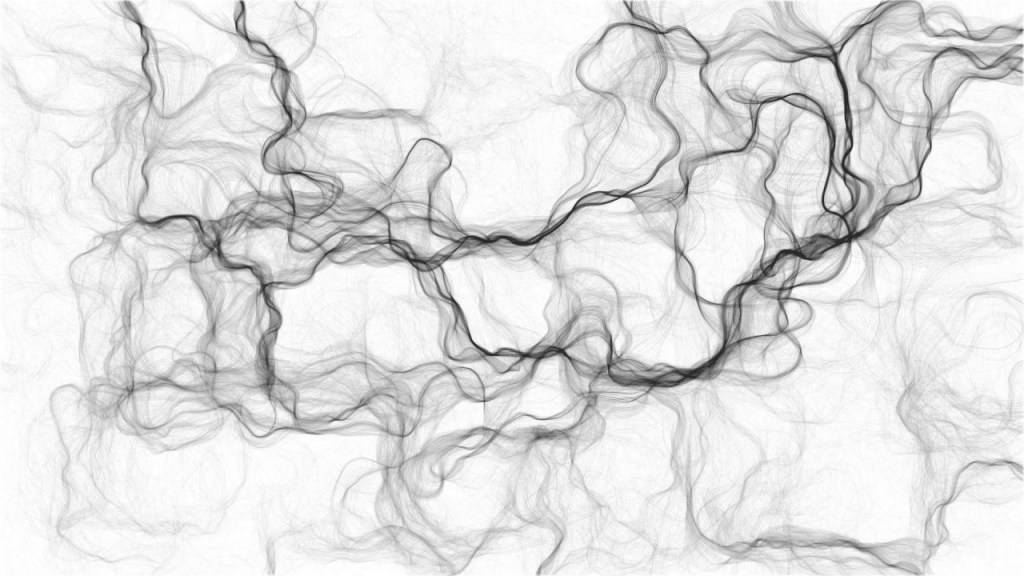
He has written (in R) many other algorithms. And we found that one specifically nicely matched the knn-poster. His metropolis – or generative city:
However, I wanted to make one myself, so I download Marcus code, and tweaked it a bit. Most importantly, I made it start in the center, made it fill up the whole space, and I made it run more efficient so I could generate a couple dozen large cities quickly, and pick the one I liked most. Here’s the end result:
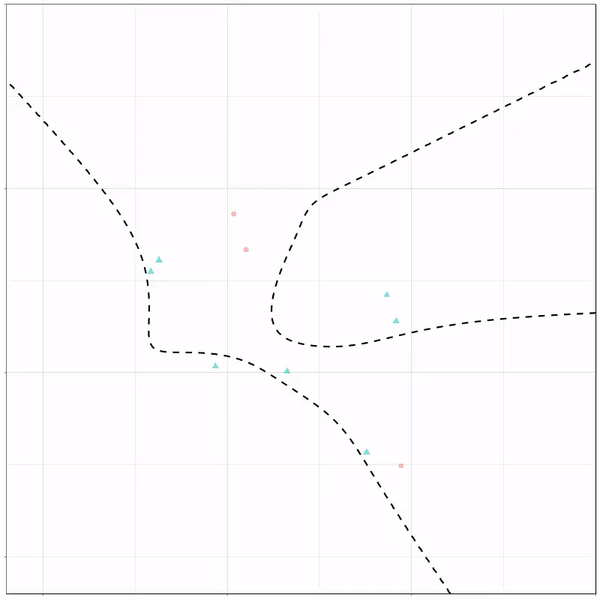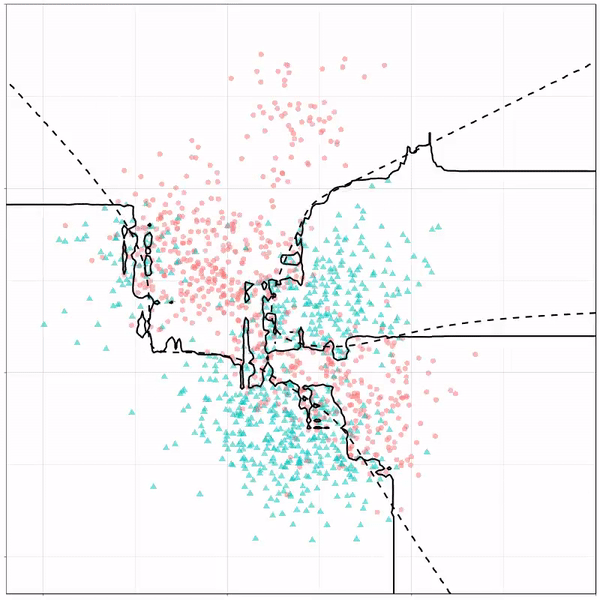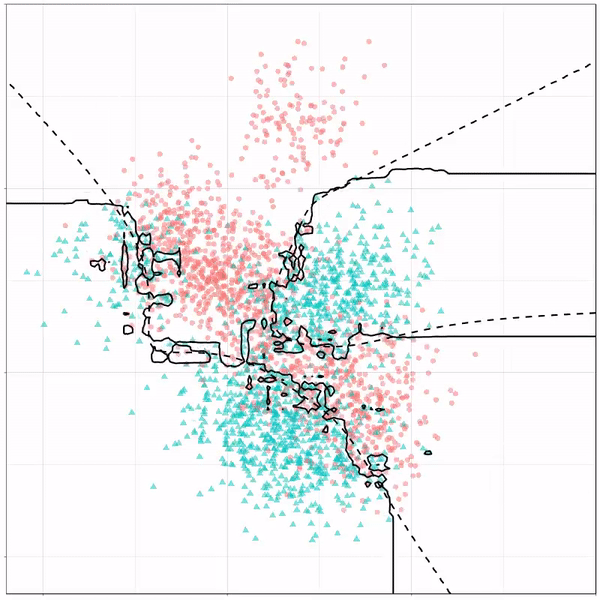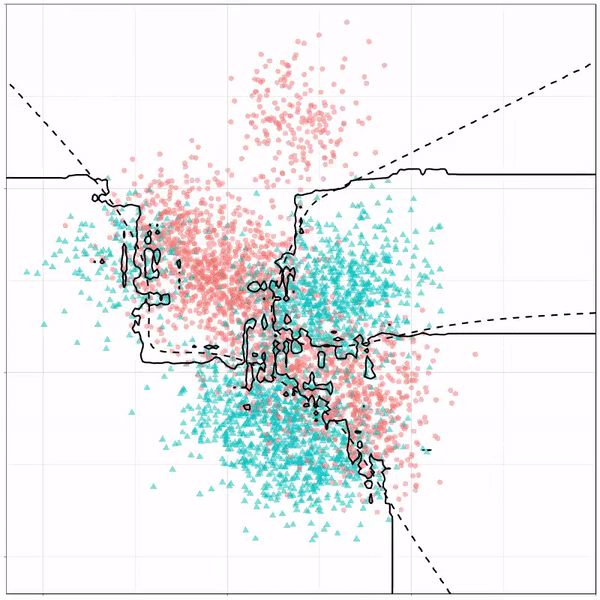
Ryan Holbrook made awesome animated GIFs in R of several classifiers learning a decision rule boundary between two classes. Basically, what you see is a machine learning model in action, learning how to distinguish data of two classes, say cats and dogs, using some X and Y variables.
These visuals can be great to understand these algorithms, the models, and their learning process a bit better.
Here’s the original tweet, with the logistic regression animation. If you follow it, you will find a whole thread of classifier GIFs. These I extracted, pasted, and explained below.
A thread of classifiers learning a decision rule. Dashed line is optimal boundary. Animations with #gganimate by @thomasp85 and @drob. #rstats
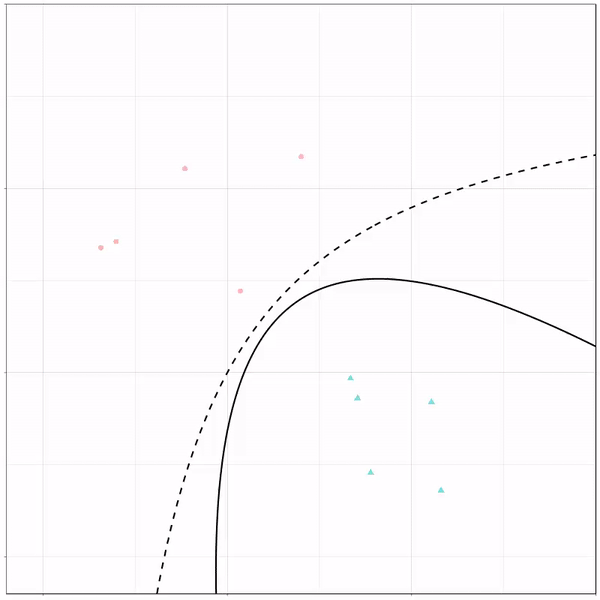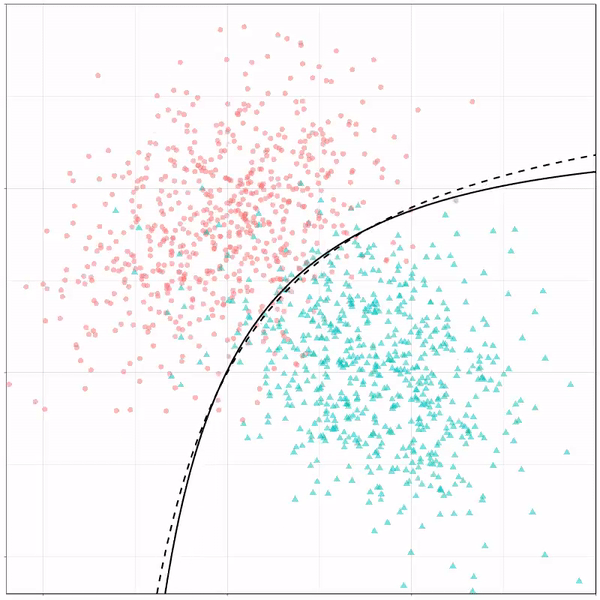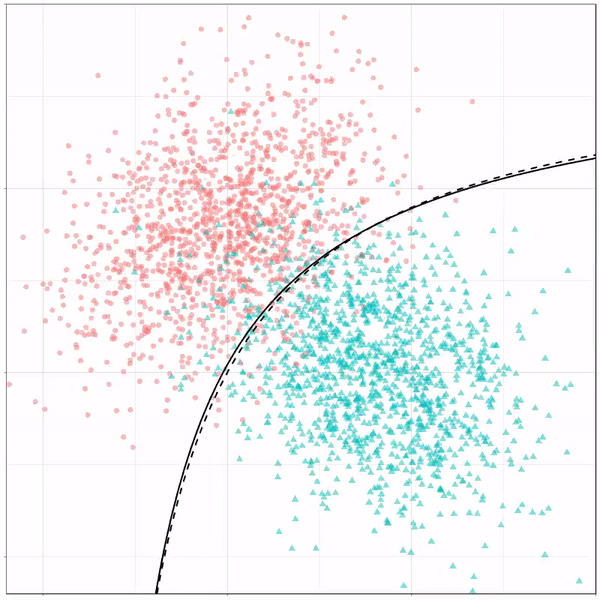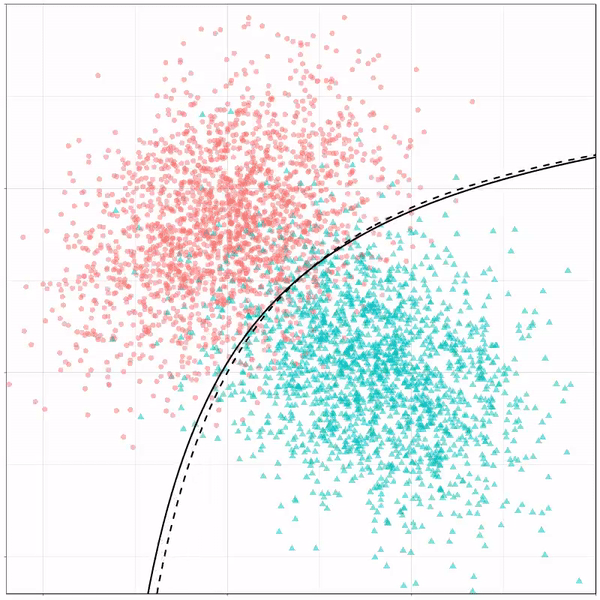
Logistic regression {stats::glm} with each class having normally distributed features. (1/n) pic.twitter.com/kKmqdO2zGy
Below is the GIF which I extracted using EZgif.com.
What you see is observations from two classes, say cats and dogs, each represented using colored dots. The dots are placed along X and Y axes, which represent variables about the observations. Their tail lengths and their hairyness, for instance.
Now there’s an optimal way to seperate these classes, which is the dashed line. That line best seperates the cats from the dogs based on these two variables X and Y. As this is an optimal boundary given this data, it is stable, it does not change.
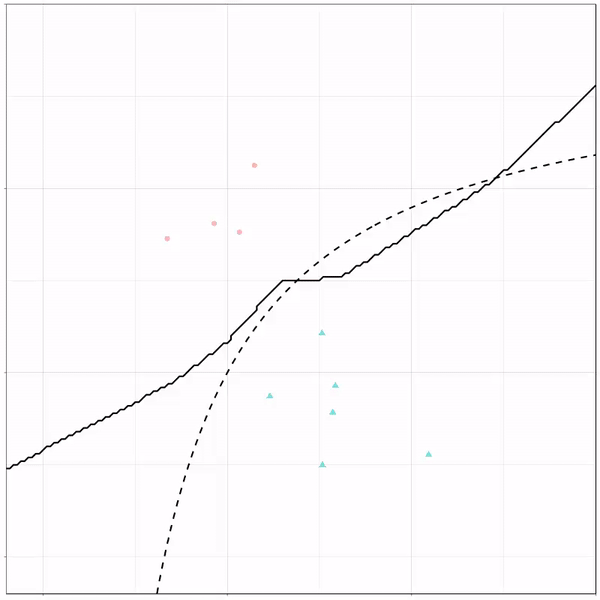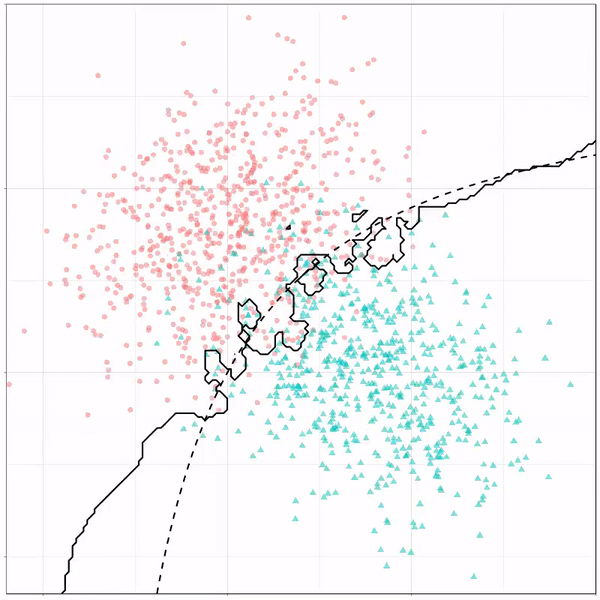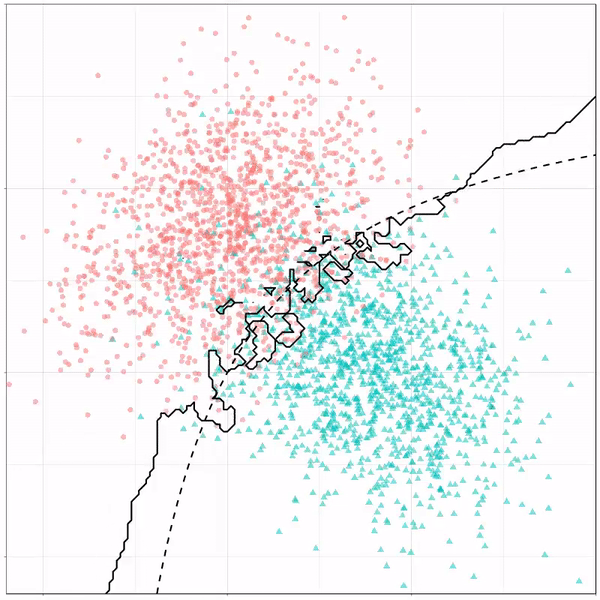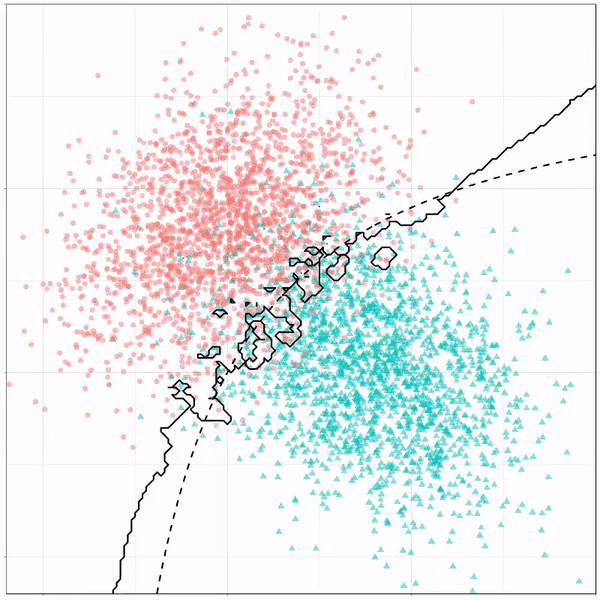
However, there’s also a solid black line, which does change. This line represents the learned boundary by the machine learning model, in this case using logistic regression. As the model is shown more data, it learns, and the boundary is updated. This learned boundary represents the best line with which the model has learned to seperate cats from dogs.
Anything above the boundary is predicted to be class 1, a dog. Everything below predicted to be class 2, a cat. As logistic regression results in a linear model, the seperation boundary is very much linear/straight.
Logistic regression gif by Ryan Holbrook
These animations are great to get a sense of how the models come to their boundaries in the back-end.
For instance, other machine learning models are able to use non-linear boundaries to dinstinguish classes, such as this quadratic discriminant analysis (qda). This “learned” boundary is much closer to the optimal boundary:
Quadratic discriminant analysis gif by Ryan Holbrook
Multivariate adaptive regression splines gif by Ryan Holbrook
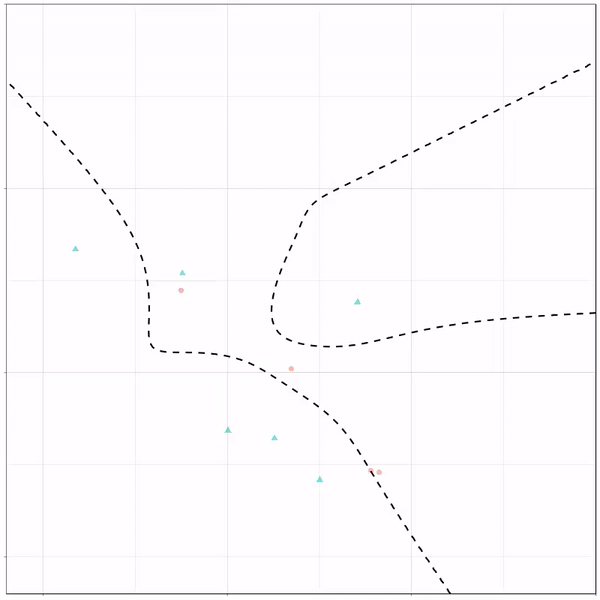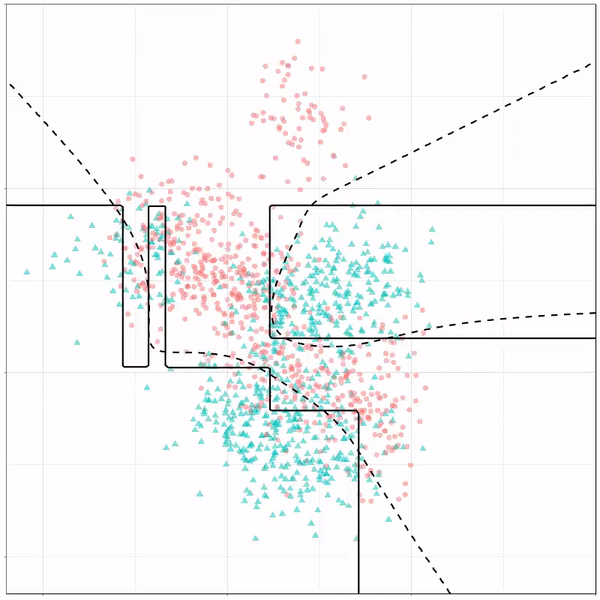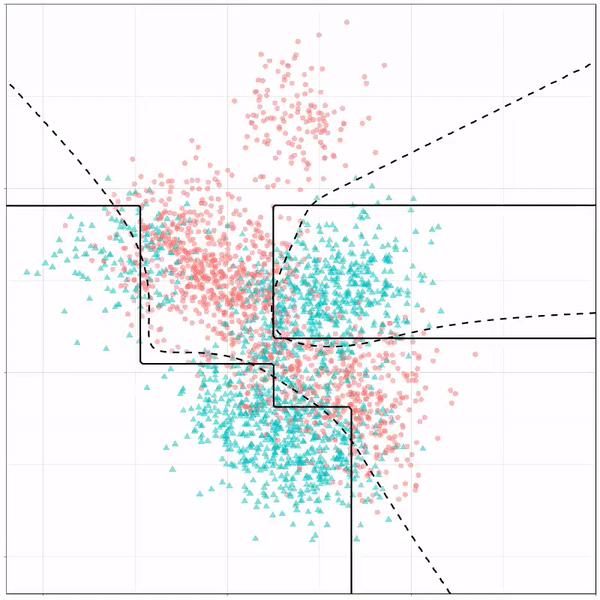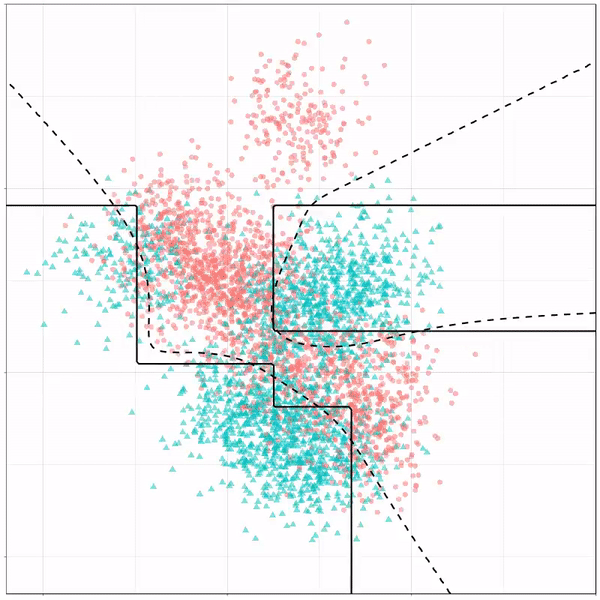
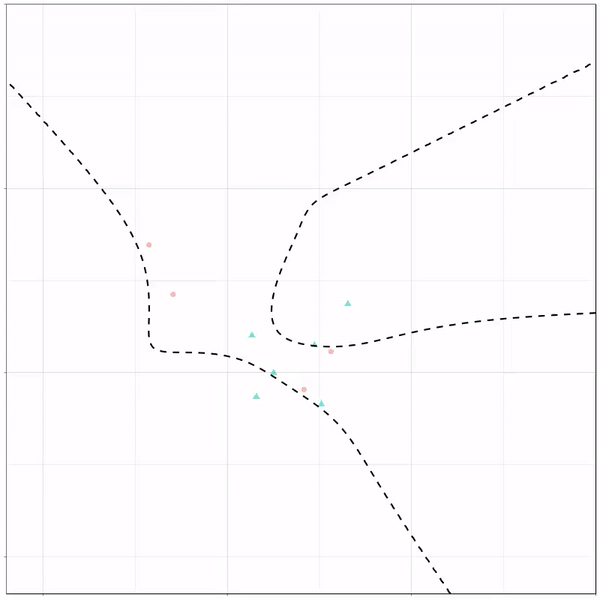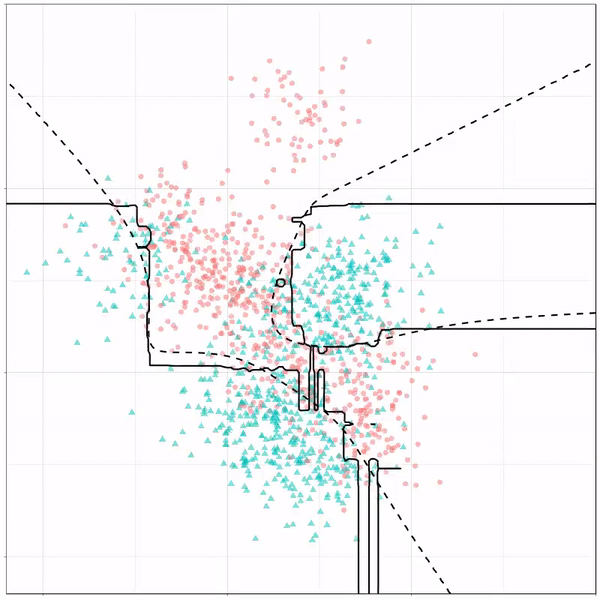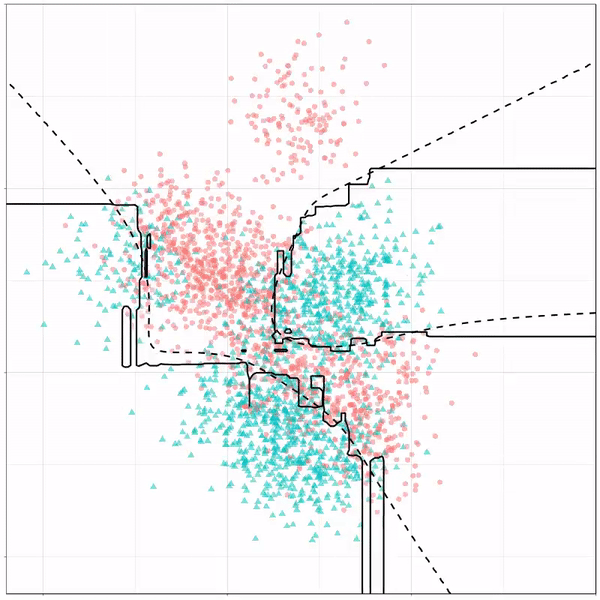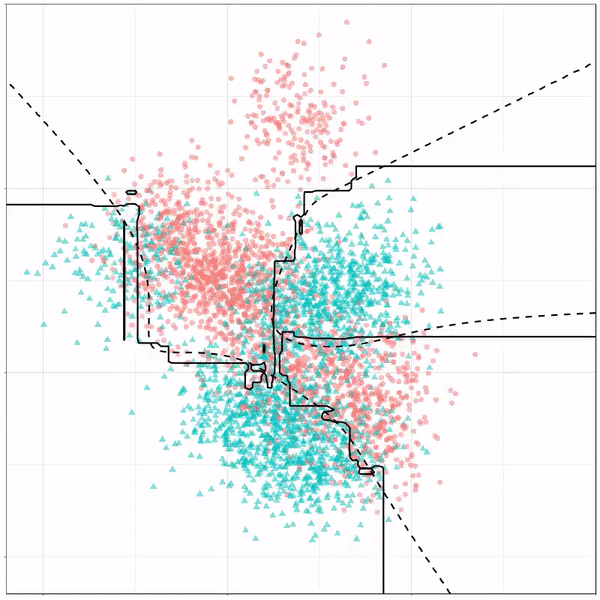
Next, we have the k-nearest neighbors algorithm, which predicts for each point (animal) the class (cat/dog) based on the “k” points closest to it. As you see, this results in a highly fluctuating, localized boundary.
K-nearest neighbors gif by Ryan Holbrook
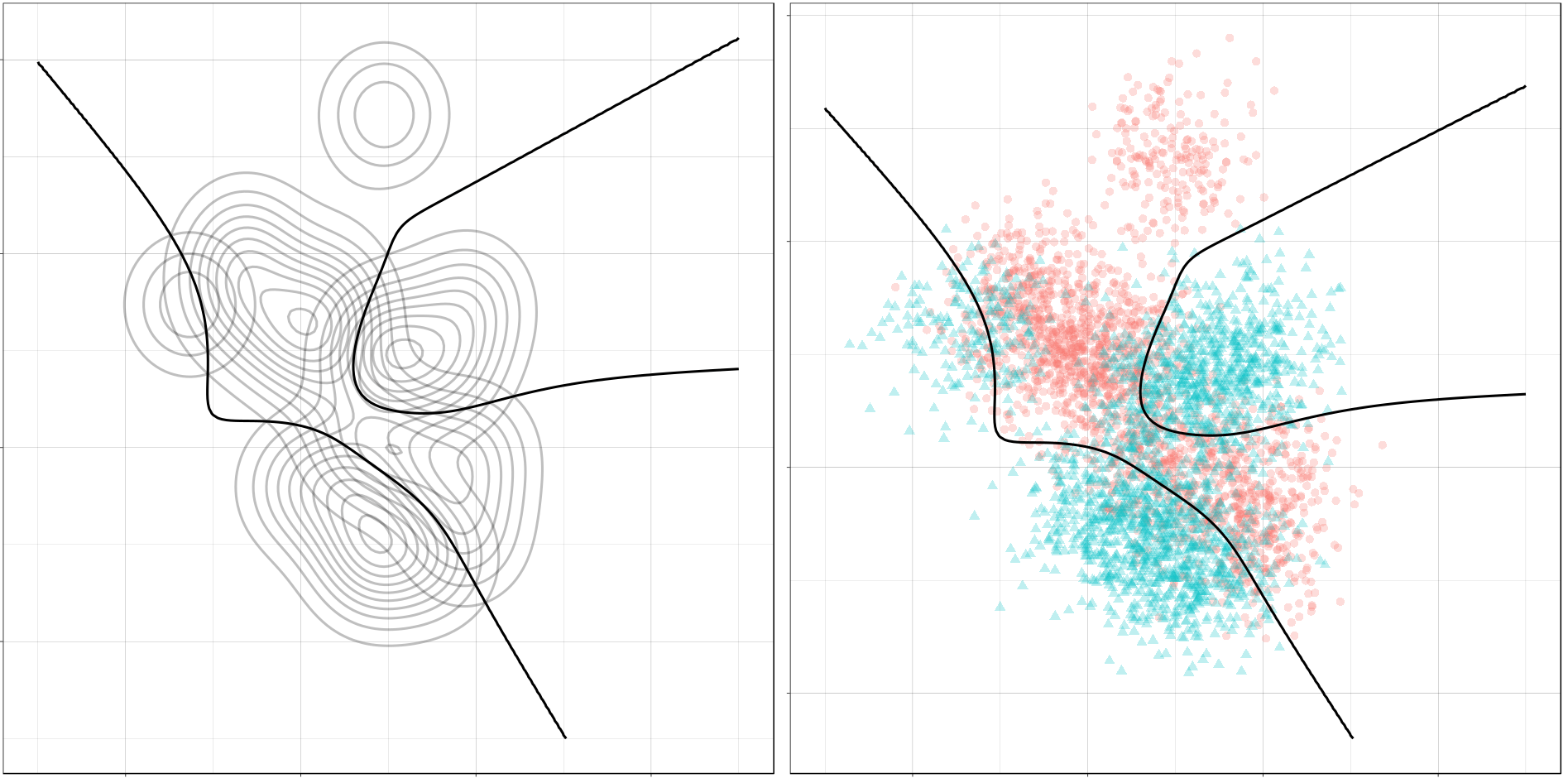
Now, Ryan decided to push the challenge, and simulate new data for two classes with a more difficult decision boundary. The new data and optimal boundaries look like this:
On these data, Ryan put a whole range of non-linear models to work.
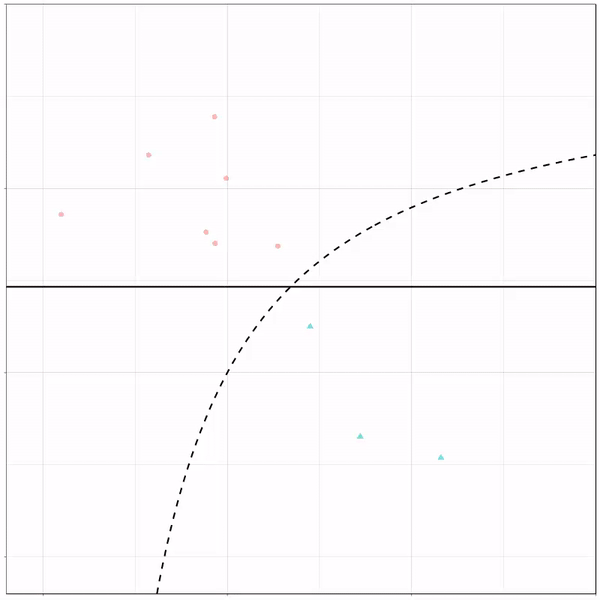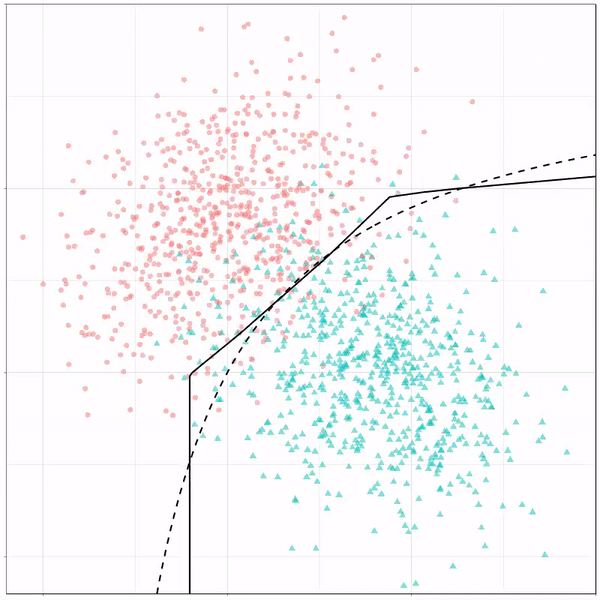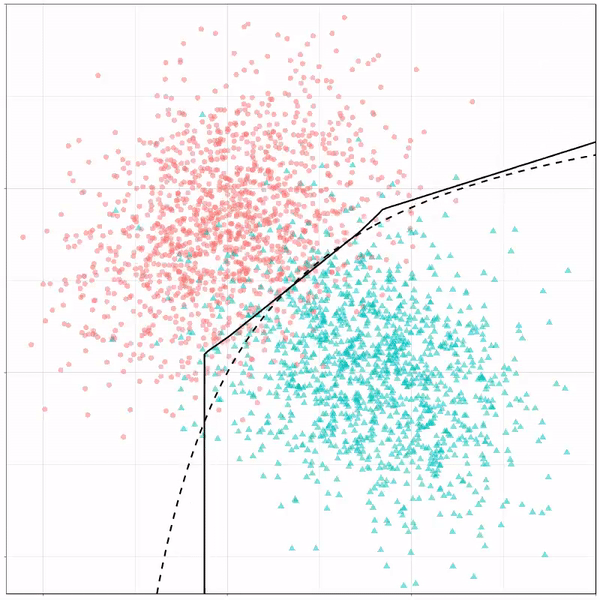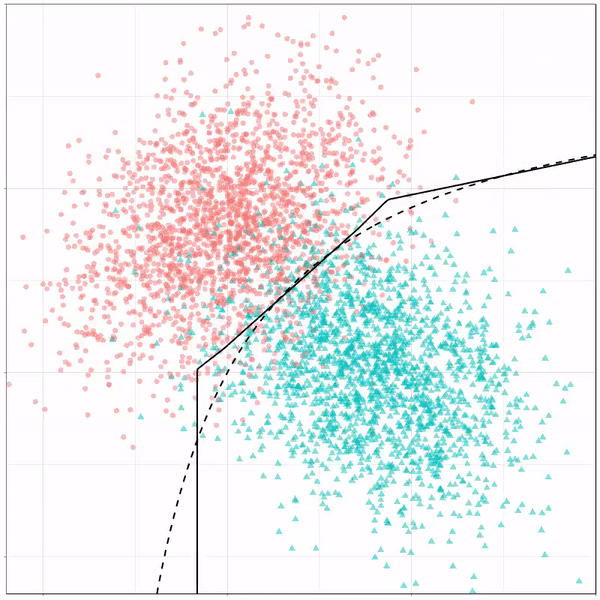
Like this support-vector machine, which tries to create optimal boundaries built of support vectors around all the cats and all the dohs (this is definitely not a technical, error-free explanation of what’s happening here).
Let’s jump into some tree-based algorithms and the resulting models. A decision tree classifies data based on multiple, sequential, binary splits. Here, Ryan trained a simple decision tree:
Decision tree gif by Ryan Holbrook
As well as it’s big brother, a random forest, which uses hundreds of trees in the back end and thus results in a more flexible boundary:
Random forest gif by Ryan Holbrook
Extreme gradient boosting is also a tree-based algorithm, which leverages many machine learning techniques to optimize the bias-variance tradeoff. Here’s an earlier blog on how to get started with Xgboost in Python or R:
Marcus Volz is a research fellow at the University of Melbourne, studying geometric networks, optimisation and computational geometry. He’s interested in visualisation, and always looking for opportunities to represent complex information in novel ways to accelerate learning and uncover the unexpected.
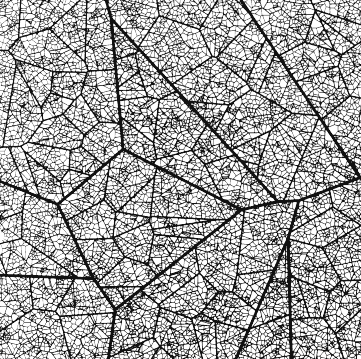
One of Marcus’ hobbies is the visualization of mathematical patterns and statistical algorithms via R. He has a whole portfolio full of them, including a Github page with all the associated R code. For my recent promotion, my girlfriend asked Marcus to generate a K-nearest neighbors visual and she had it printed on a large canvas.
The picture contains about 10.000 points, randomly uniformly distributed across x and y, connected by lines with their closest k other points. Marcus shared the code to generate such k-nearest neighbor algorithm plots here on Github. So if you know your way around R, you could make your own version:
#' k-nearest neighbour graph
#'
#' Computes a k-nearest neighbour graph for a given set of points. Refer to the \href{https://en.wikipedia.org/wiki/Nearest_neighbor_graph}{Wikipedia article} for details.
#' @param points A data frame with x, y coordinates for the points
#' @param k Number of neighbours
#' @keywords nearest neightbour graph
#' @export
#' @examples
#' k_nearest_neighbour_graph()
k_nearest_neighbour_graph <- function(points, k=8) {
get_k_nearest <- function(points, ptnum, k) {
xi <- points$x[ptnum]
yi <- points$y[ptnum] points %>%
dplyr::mutate(dist = sqrt((x - xi)^2 + (y - yi)^2)) %>%
dplyr::arrange(dist) %>%
dplyr::filter(row_number() %in% seq(2, k+1)) %>%
dplyr::mutate(xend = xi, yend = yi)
}
1:nrow(points) %>%
purrr::map_df(~get_k_nearest(points, ., k))
}
Those less versed in R can use Marcus package mathart. With this package, Marcus shares many more visual depictions of cool algorithms! You can install the package and several dependencies with the following lines of code:
This page of Marcus’ mathart Github repository contains the code exact code for these and many other visualizations of algorithms and statistical phenomena. Do check it out if you’re interested!
Also, check out the “Fun” section of my R tips and tricks list for more cool visuals you can generate in R!
Timo Grossenbacher works as reporter/coder for SRF Data, the data journalism unit of Swiss Radio and TV. He analyzes and visualizes data and investigates data-driven stories. On his website, he hosts a growing list of cool projects. One of his recent blogs covers categorical spatial interpolation in R. The end result of that blog looks amazing:
This map was built with data Timo crowdsourced for one of his projects. With this data, Timo took the following steps, which are covered in his tutorial:
Read in the data, first the geometries (Germany political boundaries), then the point data upon which the interpolation will be based on.
Preprocess the data (simplify geometries, convert CSV point data into an sf object, reproject the geodata into the ETRS CRS, clip the point data to Germany, so data outside of Germany is discarded).
Then, a regular grid (a raster without “data”) is created. Each grid point in this raster will later be interpolated from the point data.
Run the spatial interpolation with the kknn package. Since this is quite computationally and memory intensive, the resulting raster is split up into 20 batches, and each batch is computed by a single CPU core in parallel.
Visualize the resulting raster with ggplot2.
All code for the above process can be accessed on Timo’s Github. The georeferenced points underlying the interpolation look like the below, where each point represents the location of a person who selected a certain pronunciation in an online survey. More details on the crowdsourced pronunciation project van be found here, .
Another of Timo’s R map, before he applied k-nearest neighbors on these crowdsourced data. [original]If you want to know more, please read the original blog or follow Timo’s new DataCamp course called Communicating with Data in the Tidyverse.