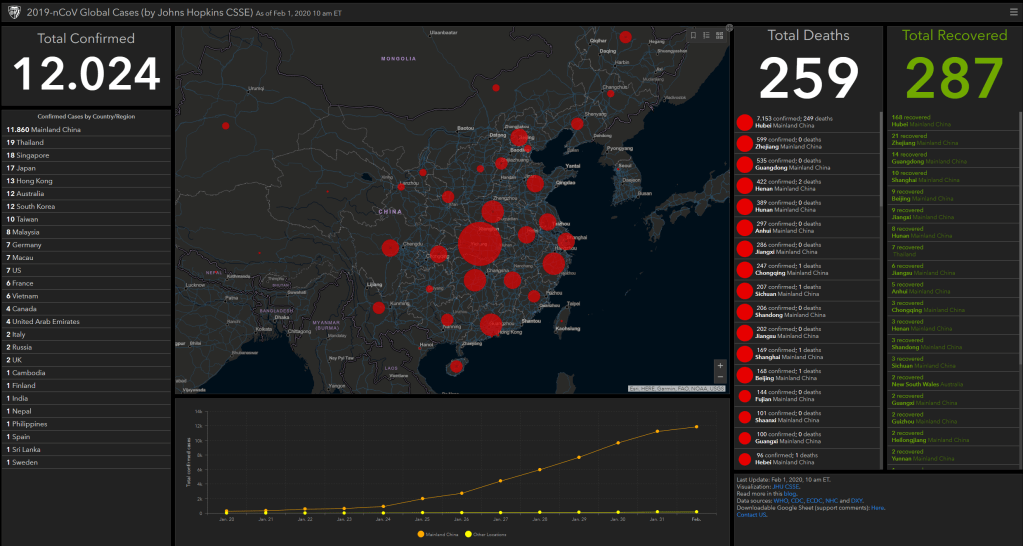
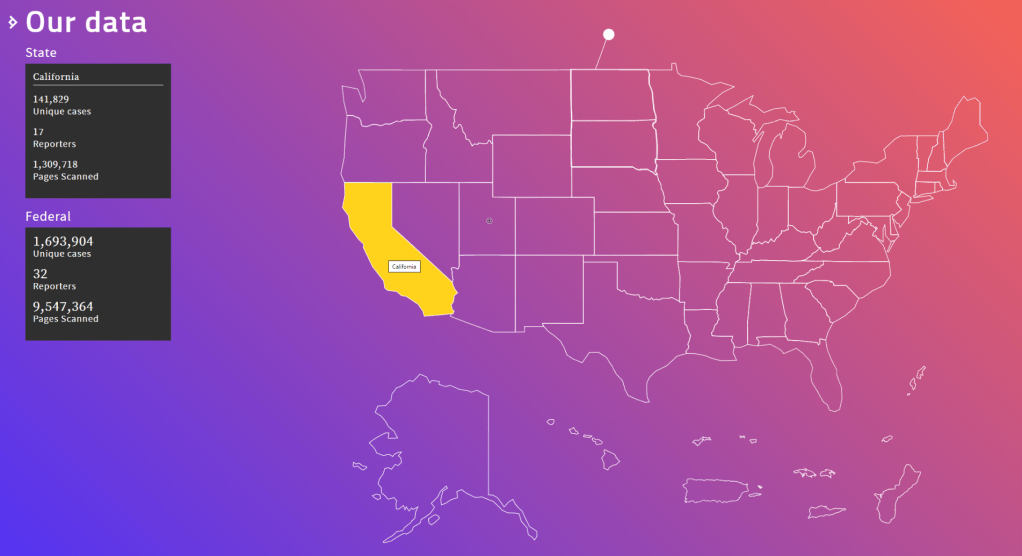
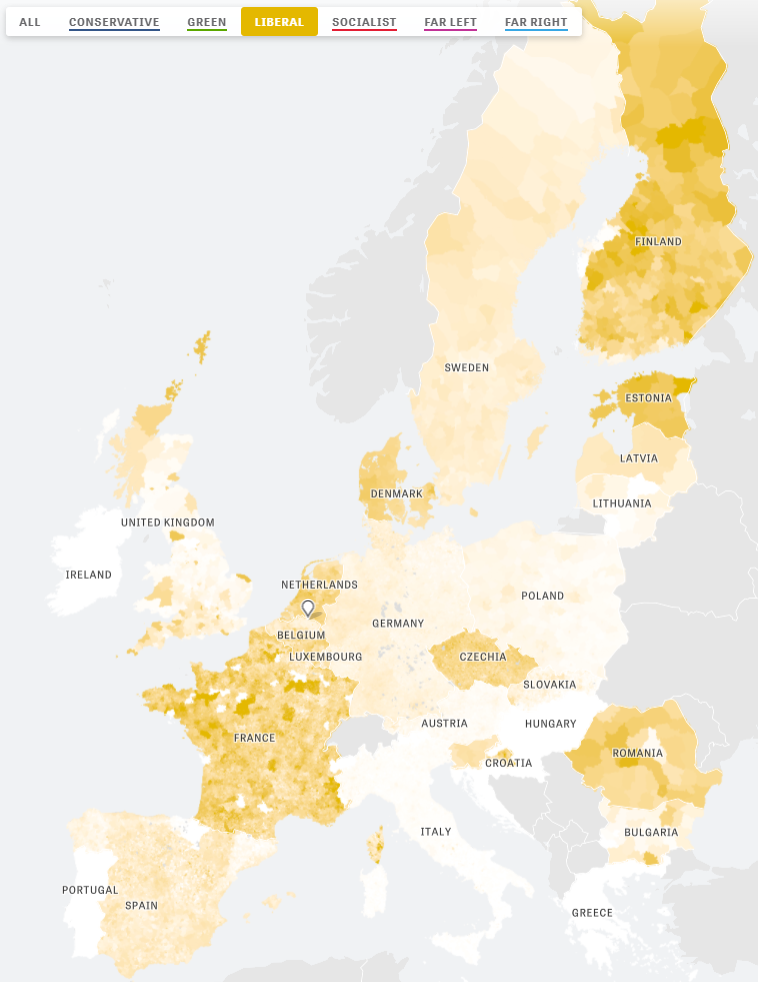
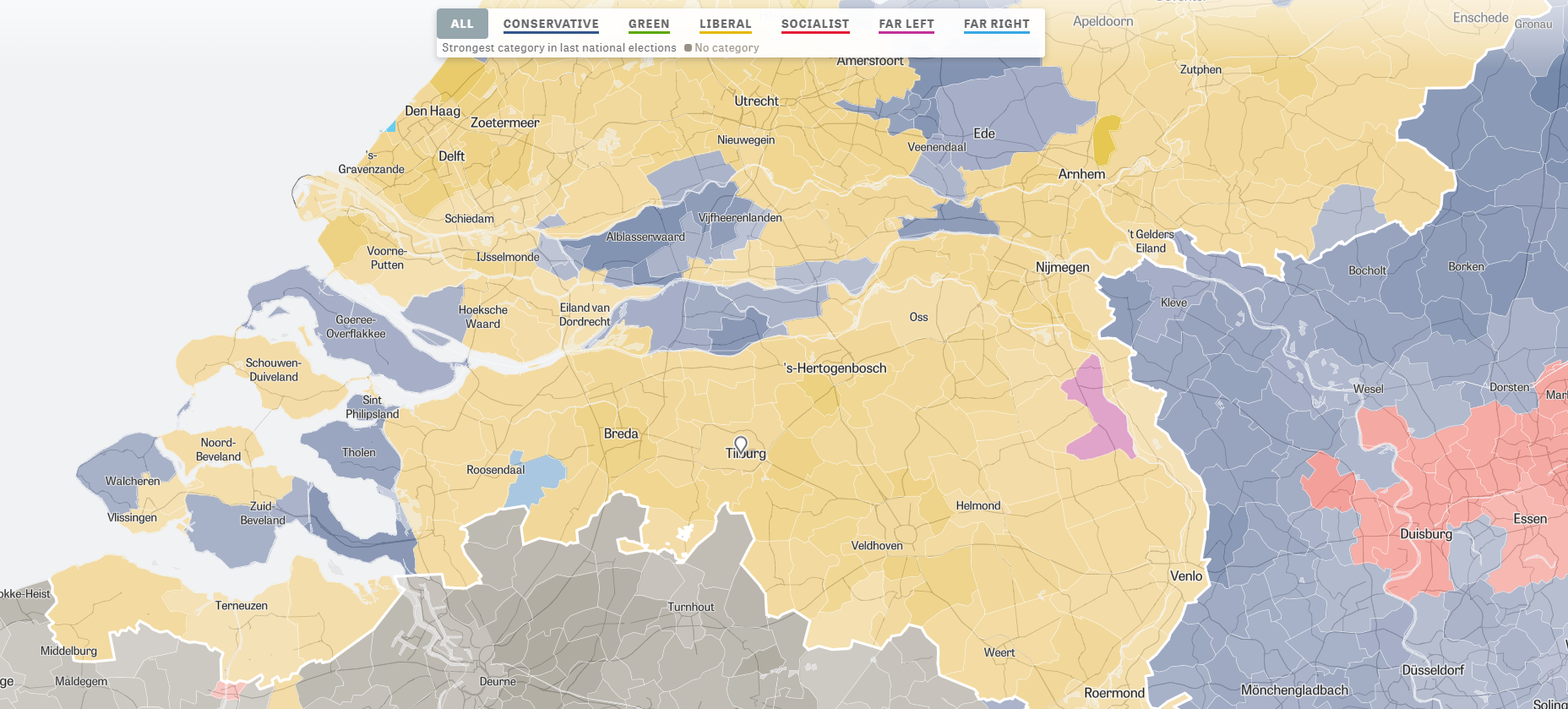
I love how people are using data and data science to fight fake news these days (see also Identifying Dirty Twitter Bots), and I recently came across another great example.
Conspirador Norteño (real name unkown) is a member of what they call #TheResistance. It’s a group of data scientists discovering and analyzing so-called botnets – networks of artificial accounts on social media websites, like Twitter.
TheResistance uses quantitative analysis to unveil large groups of fake accounts, spreading potential fake news, or fake-endorsing the (fake) news spread by others.
In a recent Twitter thread, Norteno shows how they discovered that many of Dr. Shiva Ayyadurai (self-proclaimed Inventor of Email) his early followers are likely bots.
They looked at the date of these accounts started following Shiva, offset by the date of their accounts’ creation. A remarkeable pattern appeared:
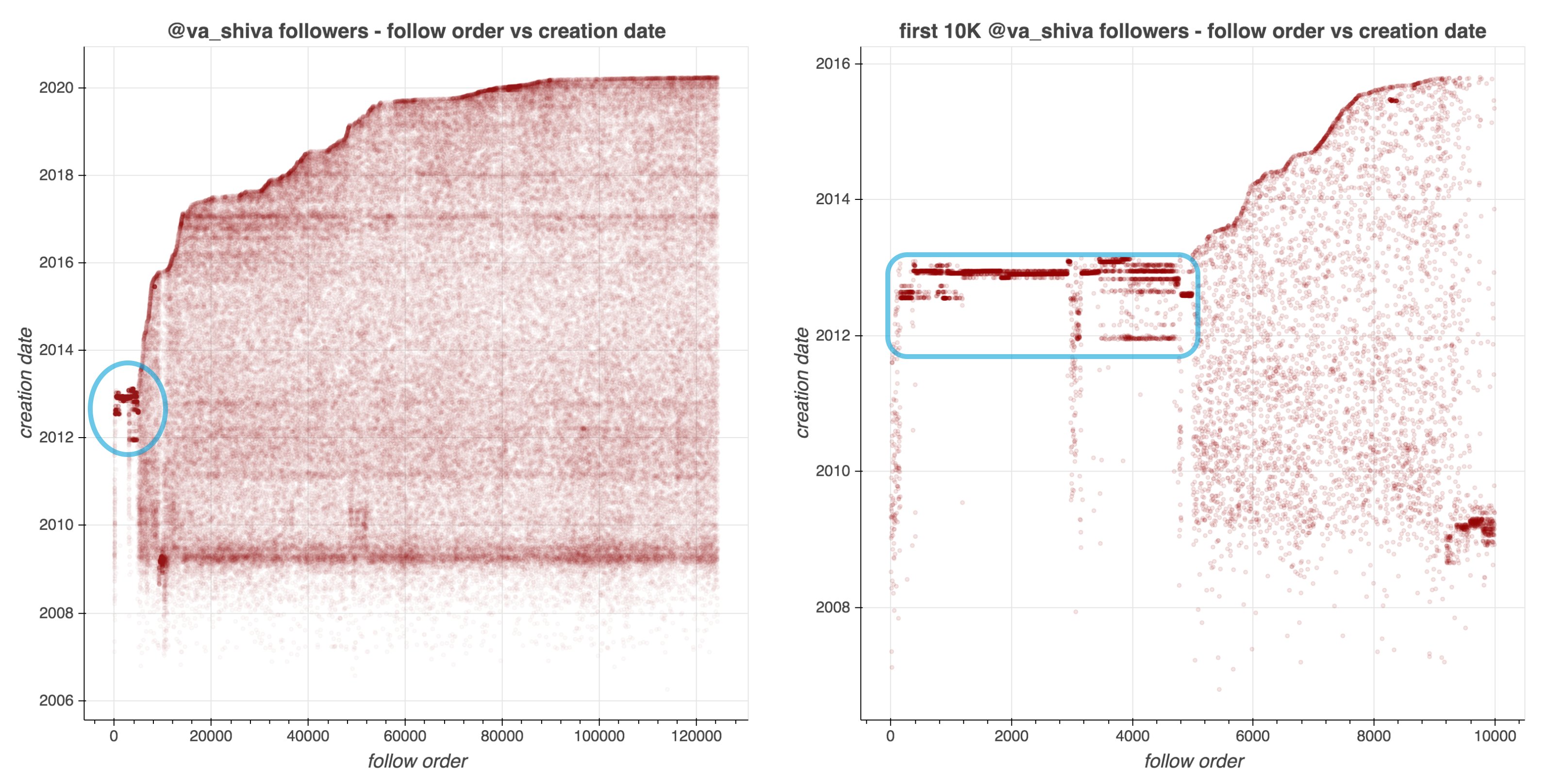
Although @va_shiva‘s recent followers look unremarkable, a significant majority of his first 5000 followers appear to have been created in batches and to have subsequently followed @va_shiva in rapid succession.
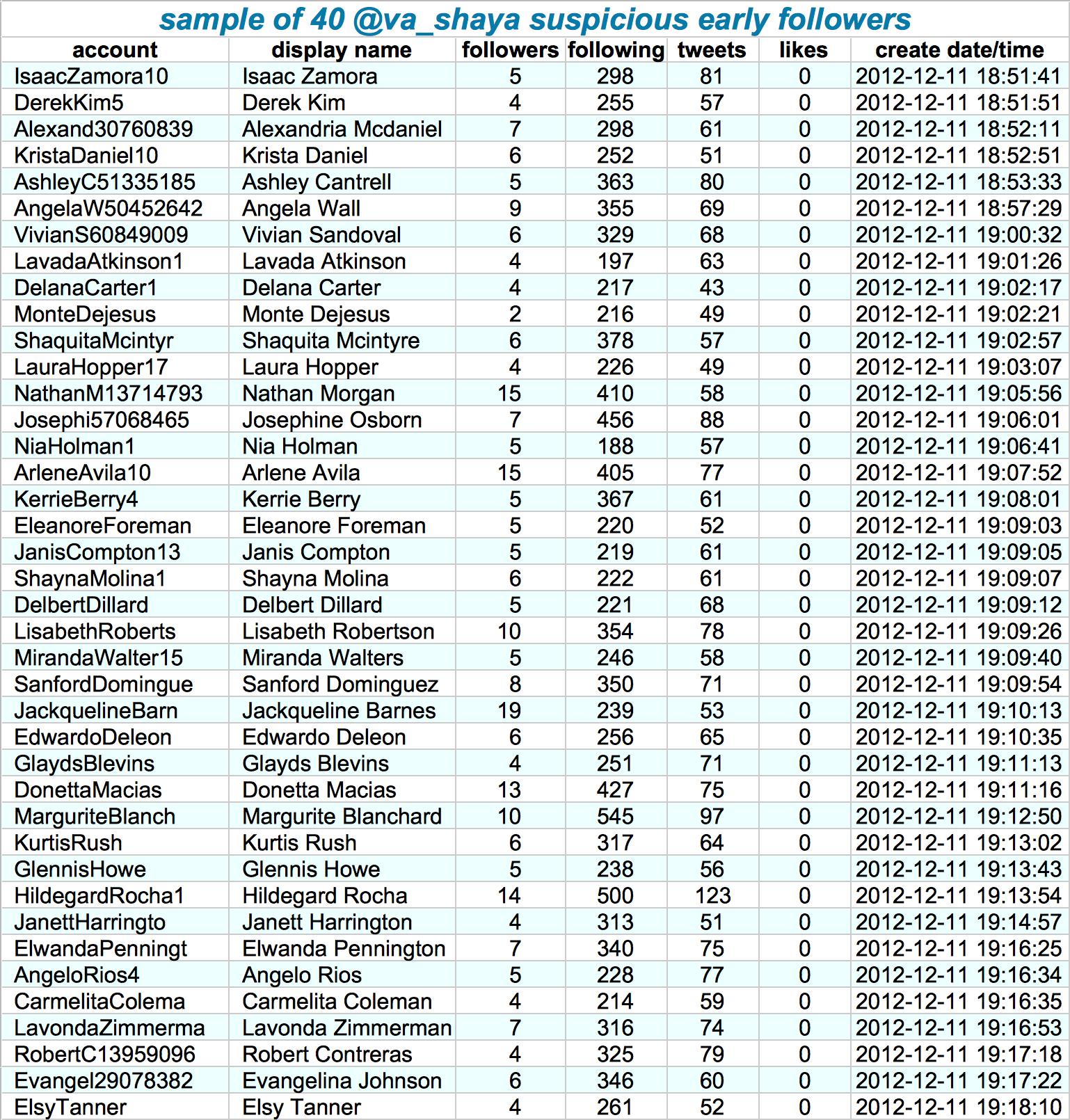
Looking at those followers in more detail, other suspicious patterns emerge. Their names follow a same pattern, they have an about equal amount of followers, followings, tweets, and (no) likes. Moreover, they were created only seconds apart. Many of them seem to follow each other as well.
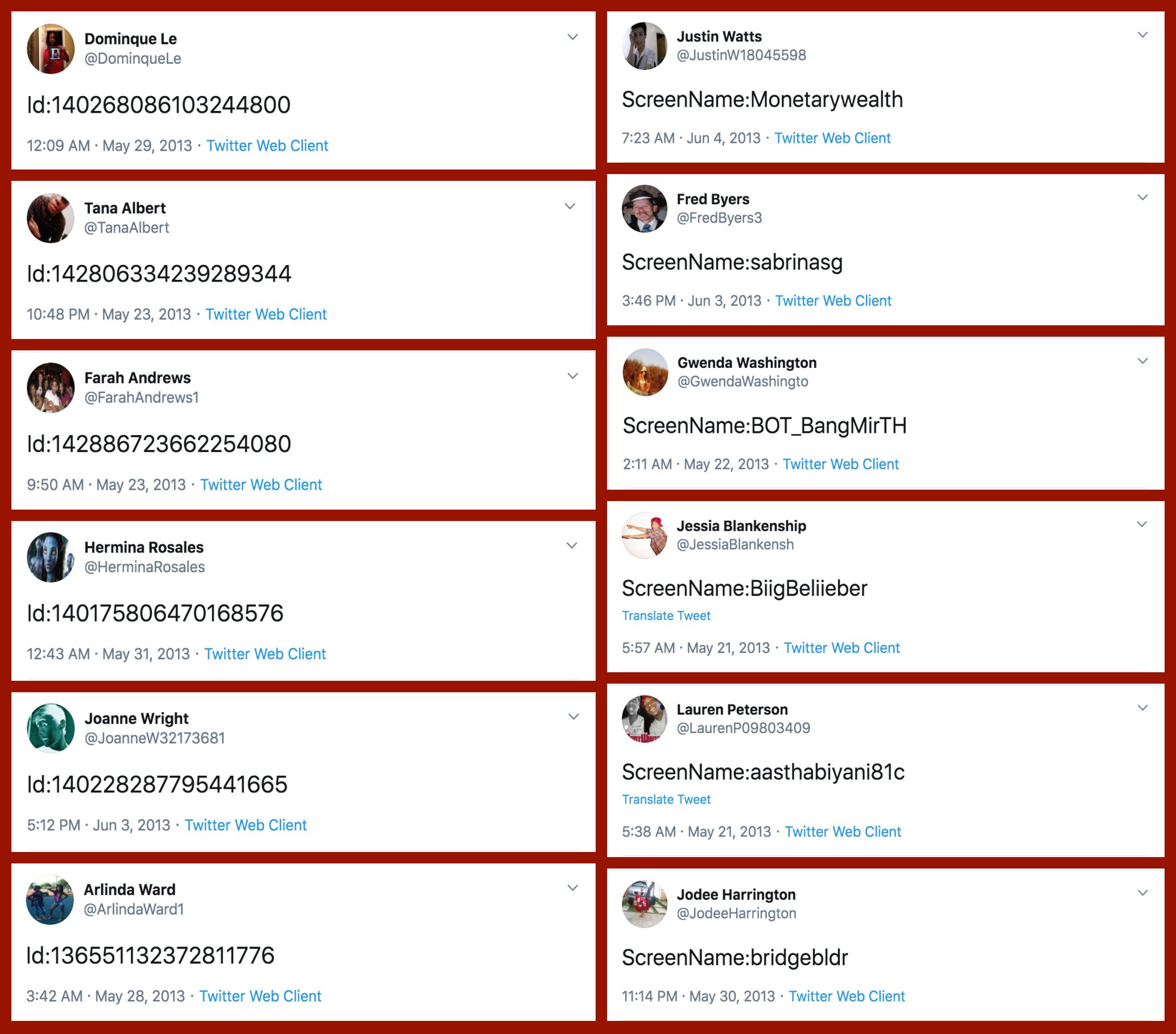
If that wasn’t enough proof of something’s off, here’s a variety of their tweets… Not really what everyday folks would tweet right? Plus similar patterns again across acounts.
At first, I thought, so what? This Shiva guy probably just set up some automated (Python?) scripts to make Twitter account and follow him. Good for him. It worked out, as his most recent 10k followers followed him organically.
However, it becomes more scary if you notice this Shiva guy is (succesfully) promoting the firing of people working for the government:
Anyways, wanted to share this simple though cool approach to finding bots & fake news networks on social media. I hope you liked it, and would love to hear your thoughts in the comments!