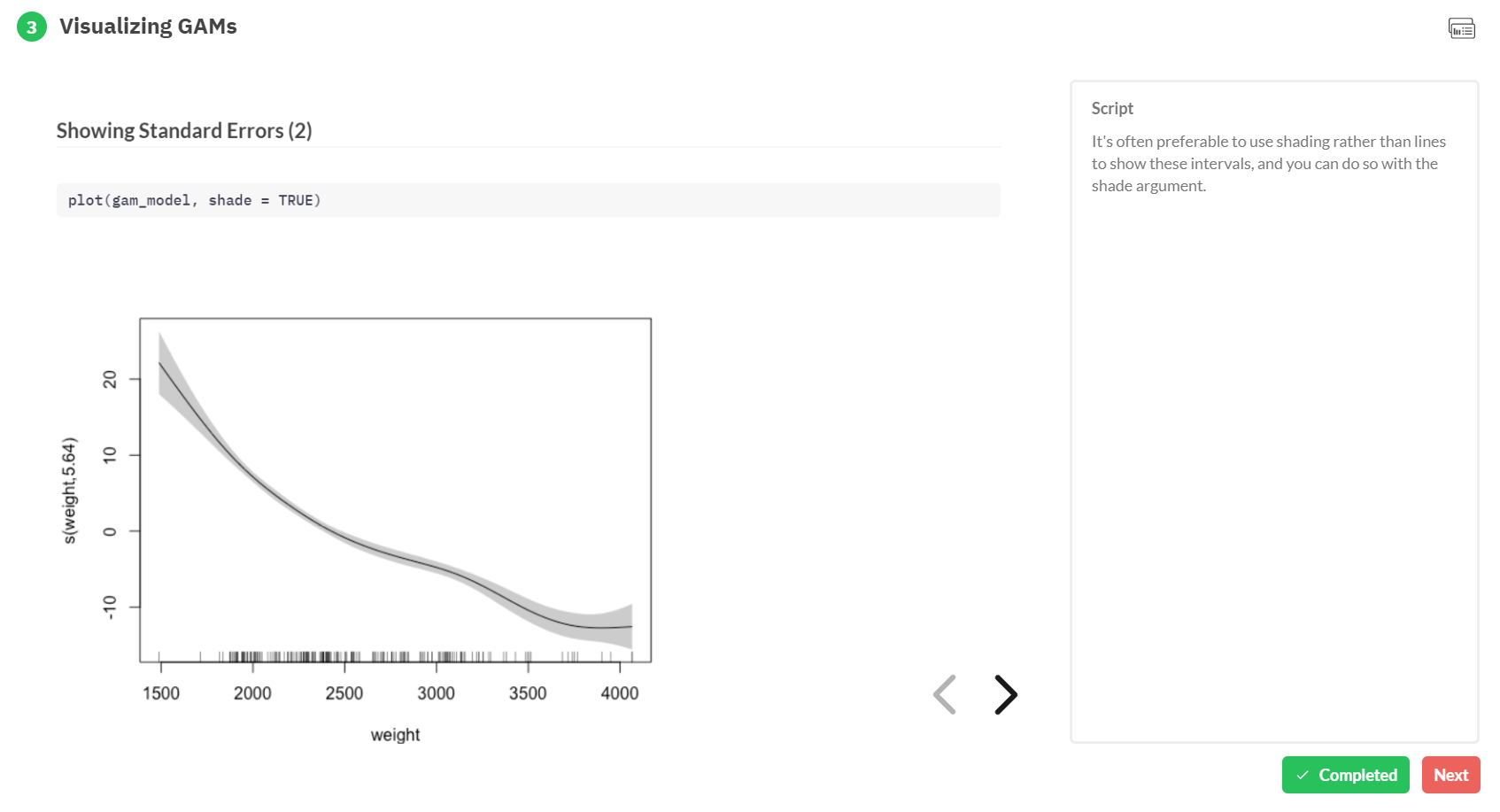
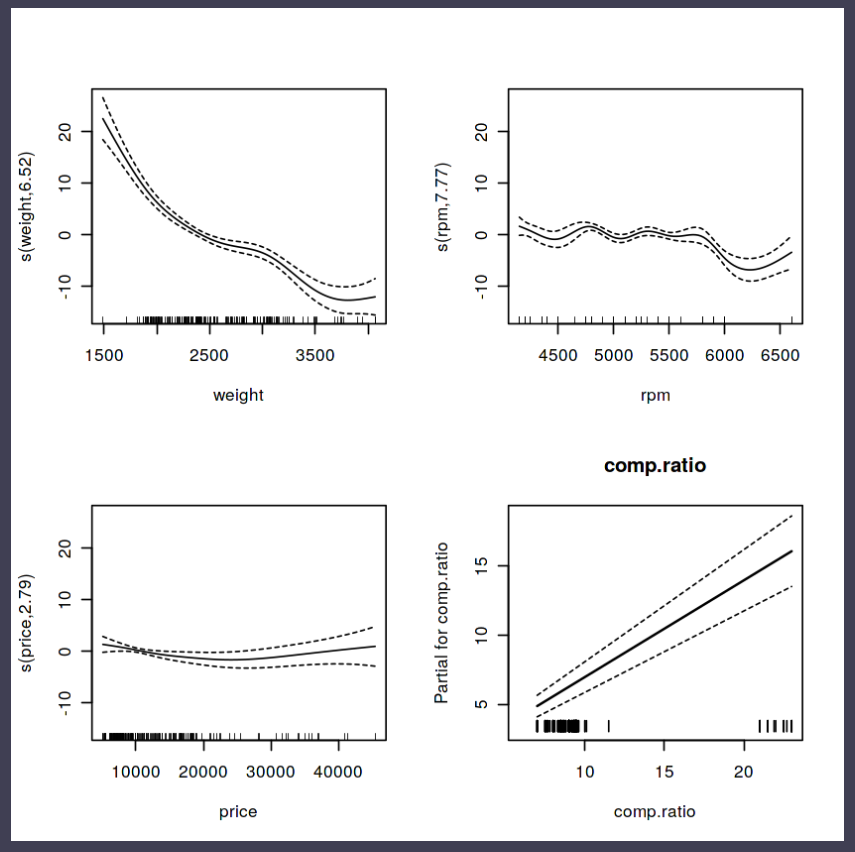
Generalized Additive Models — or GAMs in short — have been somewhat of a mystery to me. I’ve known about them, but didn’t know exactly what they did, or when they’re useful. That came to an end when I found out about this tutorial by Noam Ross.
In this beautiful, online, interactive course, Noam allows you to program several GAMs yourself (in R) and to progressively learn about the different functions and features. I am currently halfway through, but already very much enjoy it.
If you’re already familiar with linear models and want to learn something new, I strongly recommend this course!
Recently, I came across a social science paper that had used linear probability regression. I had never heard of linear probability models (LPM), but it seems just an application of ordinary least squares regression but to a binomial dependent variable.
According to some, LPM is a commonly used alternative for logistic regression, which is what I was learned to use when the outcome is binary.
Potentially because of my own social science background (HRM), using linear regression without a link transformation on binary data just seems very unintuitive and error-prone to me. Hence, I sought for more information.
I particularly liked this article by Jake Westfall, which he dubbed “Logistic regression is not fucked”, following a series of blogs in which he talks about methods that are fucked and not useful.
Jake explains the classification problem and both methods inner workings in a very straightforward way, using great visual aids. He shows how LMP would differ from logistic models, and why its proposed benefits are actually not so beneficial. Maybe I’m in my bubble, but Jake’s arguments resonated.
Here’s the summary: Arguments against the use of logistic regression due to problems with “unobserved heterogeneity” proceed from two distinct sets of premises. The first argument points out that if the binary outcome arises from a latent continuous outcome and a threshold, then observed effects also reflect latent heteroskedasticity. This is true, but only relevant in cases where we actually care about an underlying continuous variable, which is not usually the case. The second argument points out that logistic regression coefficients are not collapsible over uncorrelated covariates, and claims that this precludes any substantive interpretation. On the contrary, we can interpret logistic regression coefficients perfectly well in the face of non-collapsibility by thinking clearly about the conditional probabilities they refer to.
This overview is curated in the sense that all resources are rated by CourseDuck’s users. These ratings seem quite reliable, at least, I personally enjoyed their top-3 resources sometime the past years:
Note that all these courses, as well as the curated overview, come free of charge! A great resource for starting data scientists or upcoming pythonistas!
Kunststube wrote this great introduction to text encoding. Ever wondered why your Word document sometimes starts with ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ? Well, encoding‘s why. Kunststube introduces you to the wonderful world of ASCII, WLatin, Mac Latin, and UTF-8, -16 and -32.
Ever wondered what it is like to program computer games?
Or even better, what it is like to program programs that program your computer games for you? Then welcome to the wonderful world of procedural game design, such as Spore, Borderlands, and No Man’s Sky.
Recently, I have been watching and greatly enjoying this Youtube playlist of the South-African Sebastian Lague. In a series of nine videos, Sebastian programs a procedural cave generator from scratch. The program generates a pseudo-random cave, following some sensible constraints, everytime its triggered.
The following is Sebastian’s first video in the series labeled: Learn how to create procedurally generated caverns/dungeons for your games using cellular automata and marching squares.
More in line with my blog’s main topics, Sebastian also hosts a series on neural networks, which I will most probably watch and report on over the course of the coming weeks:
Josh Starmer is assistant professor at the genetics department of the University of North Carolina at Chapel Hill.
But more importantly: Josh is the mastermind behind StatQuest!
StatQuest is a Youtube channel (and website) dedicated to explaining complex statistical concepts — like data distributions, probability, or novel machine learning algorithms — in simple terms.
Once you watch one of Josh’s “Stat-Quests”, you immediately recognize the effort he put into this project. Using great visuals, a just-about-right pace, and relateable examples, Josh makes statistics accessible to everyone. For instance, take this series on logistic regression:
And do you really know what happens under the hood when you run a principal component analysis? After this video you will:
Or are you more interested in learning the fundamental concepts behind machine learning, then Josh has some videos for you, for instance on bias and variance or gradient descent:
With nearly 200 videos and counting, StatQuest is truly an amazing resource for students ‘and teachers on topics related to statistics and data analytics. For some of the concepts, Josh even posted videos running you through the analysis steps and results interpretation in the R language.
StatQuest started out as an attempt to explain statistics to my co-workers – who are all genetics researchers at UNC-Chapel Hill. They did these amazing experiments, but they didn’t always know what to do with the data they generated. That was my job. But I wanted them to understand that what I do isn’t magic – it’s actually quite simple. It only seems hard because it’s all wrapped up in confusing terminology and typically communicated using equations. I found that if I stripped away the terminology and communicated the concepts using pictures, it became easy to understand.
Over time I made more and more StatQuests and now it’s my passion on YouTube.