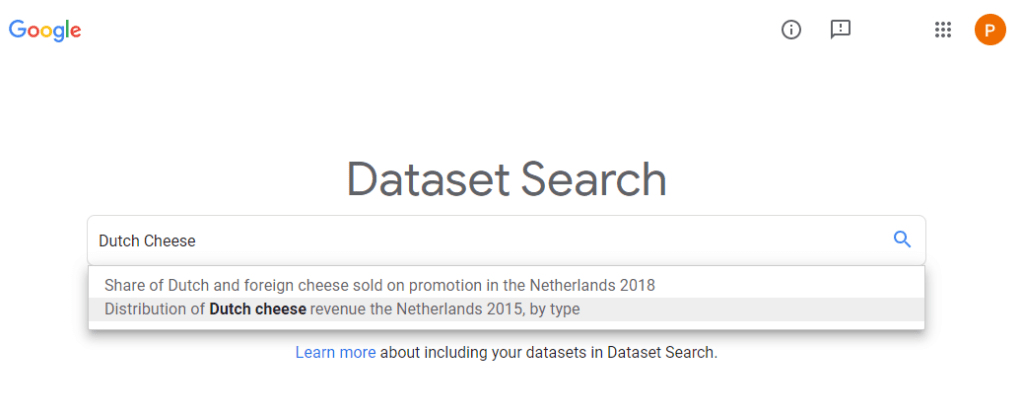
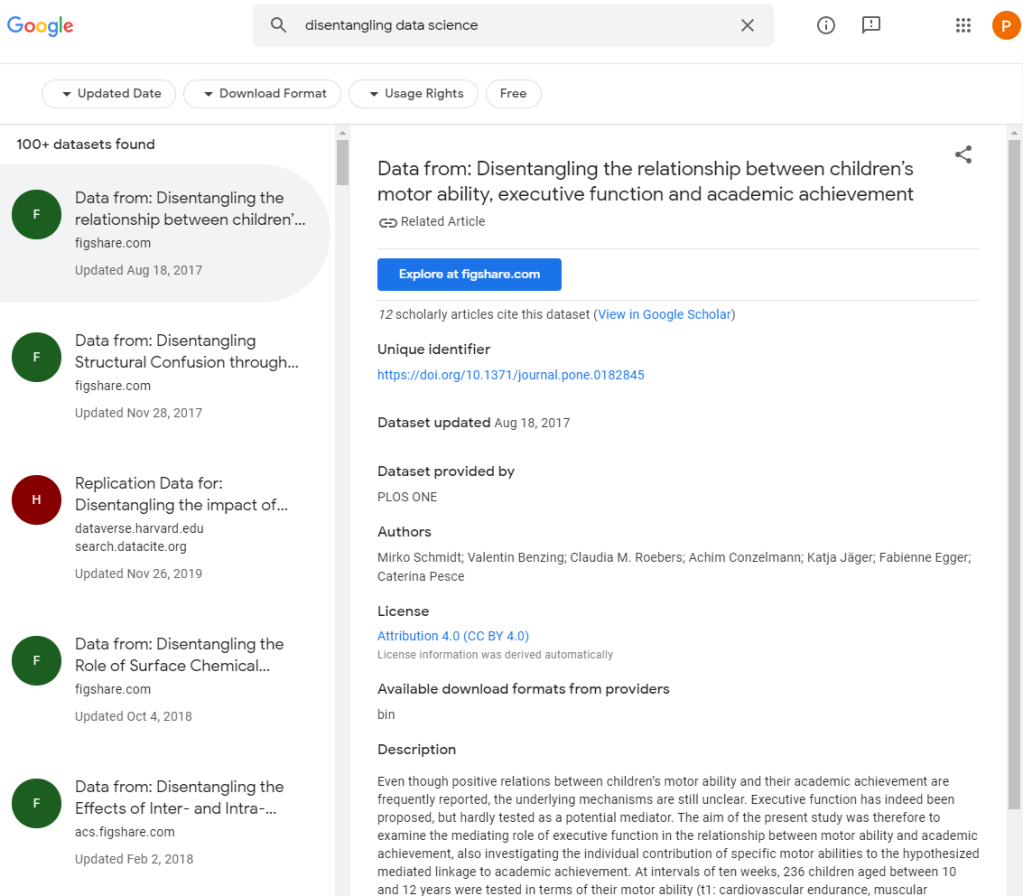
The “world wide web” hosts millions of datasets, on nearly any topic you can think of. Google’s Dataset Search has indexed almost 25 million of these datasets, giving you a single entry point to search for datasets online. After a year of testing, Dataset Search is now officially out of beta.
After alpha testing, Dataset Search now includes filter based on the types of dataset that you want (e.g., tables, images, text), on whether the dataset is open source/access. For dataset on geographic area’s, you can see the map. The quality of dataset’s descriptions has improved greatly, and the tool now has a mobile version.
Ryan Holbrook made awesome animated GIFs in R of several classifiers learning a decision rule boundary between two classes. Basically, what you see is a machine learning model in action, learning how to distinguish data of two classes, say cats and dogs, using some X and Y variables.
These visuals can be great to understand these algorithms, the models, and their learning process a bit better.
Here’s the original tweet, with the logistic regression animation. If you follow it, you will find a whole thread of classifier GIFs. These I extracted, pasted, and explained below.
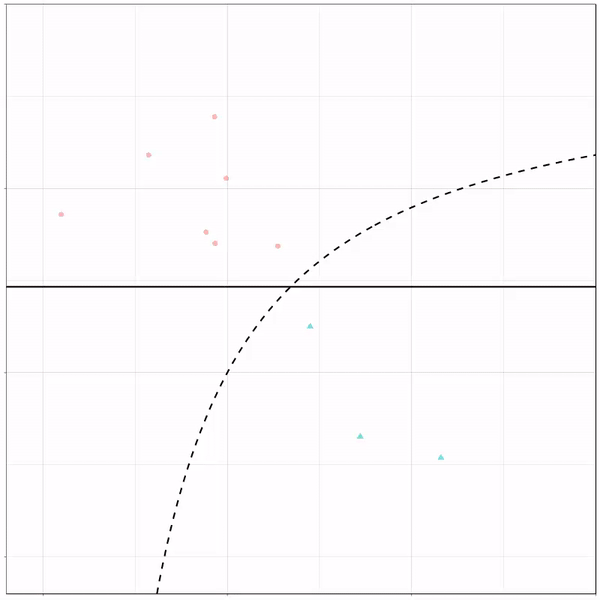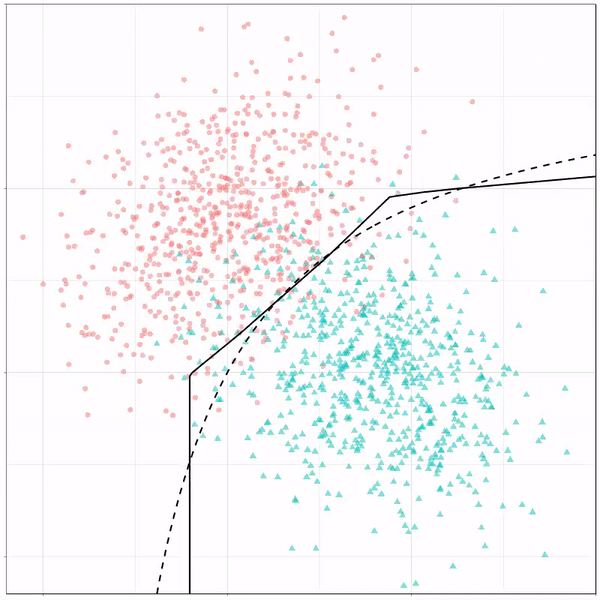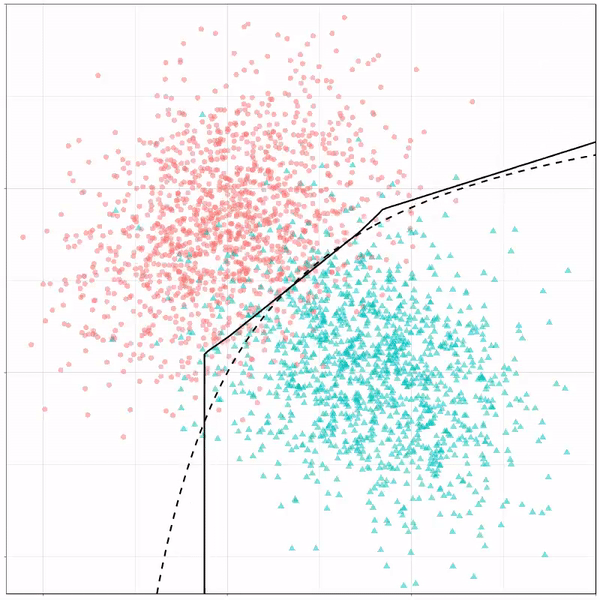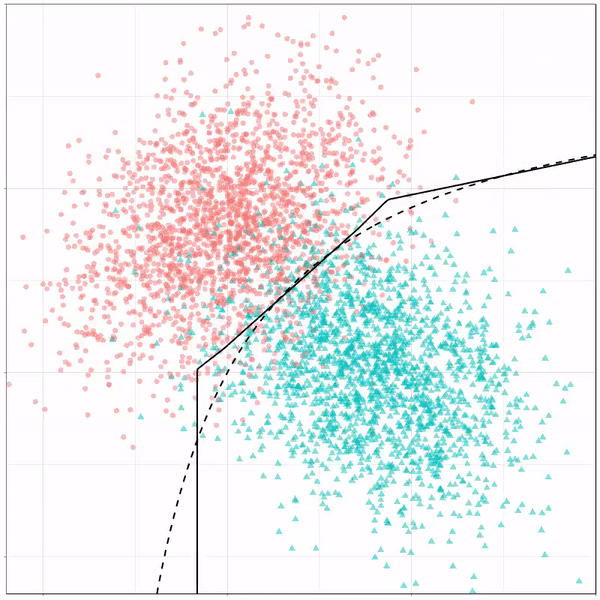
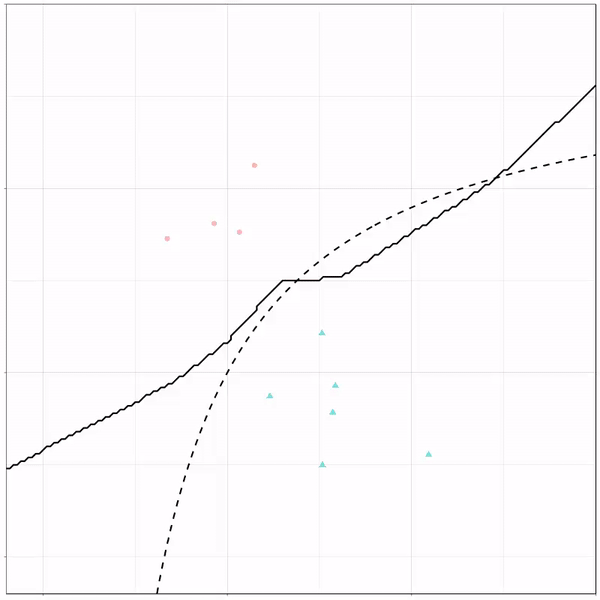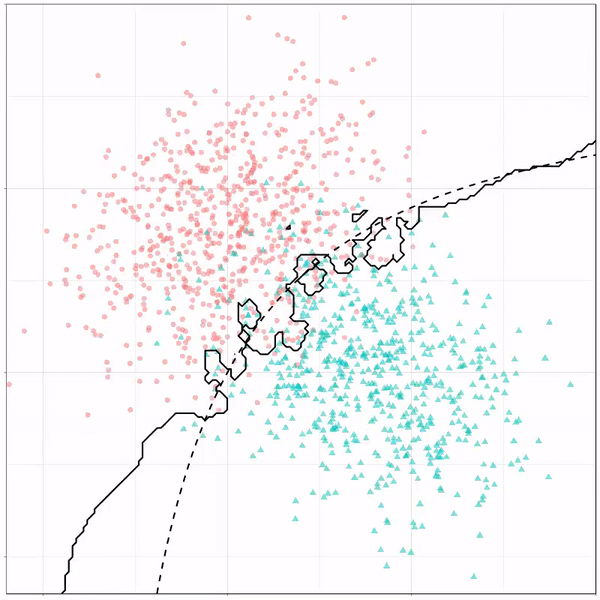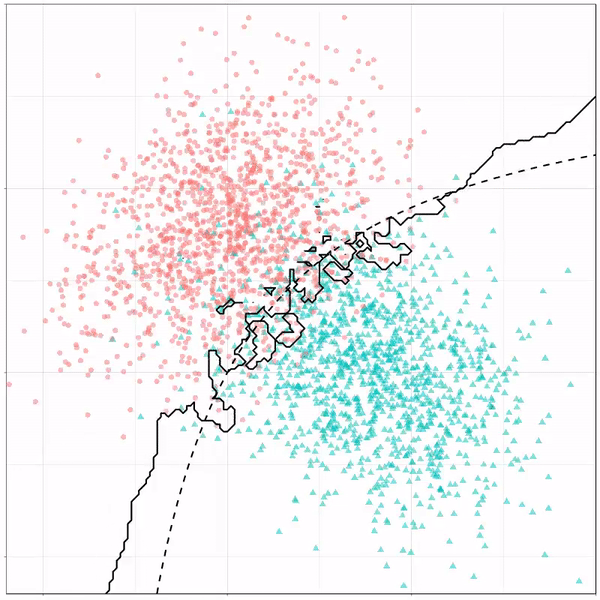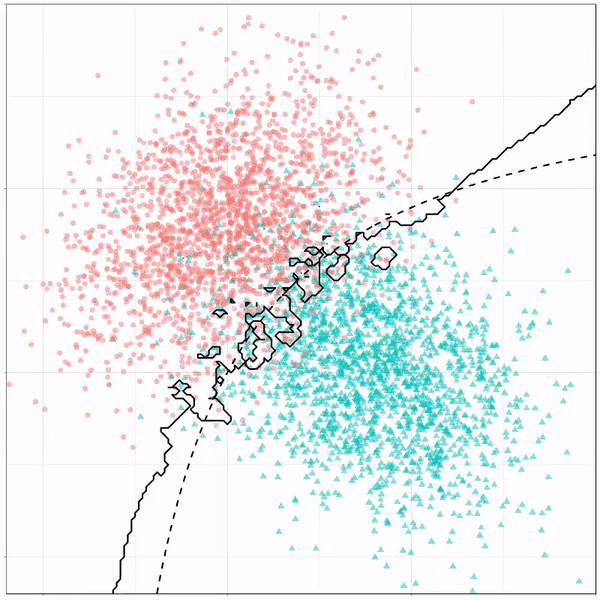
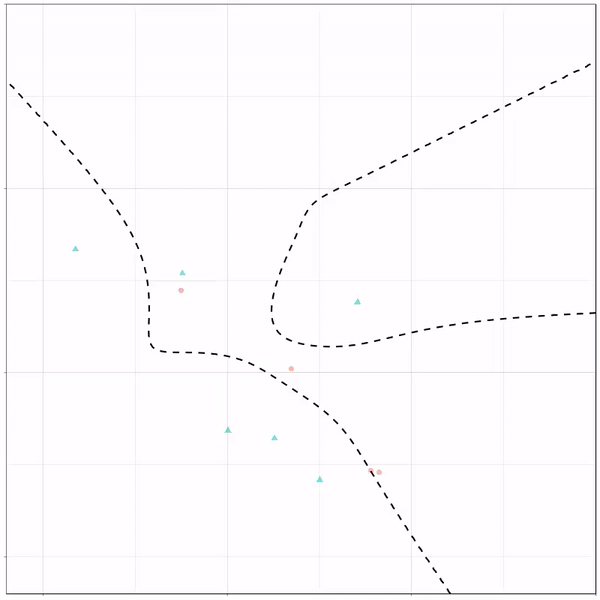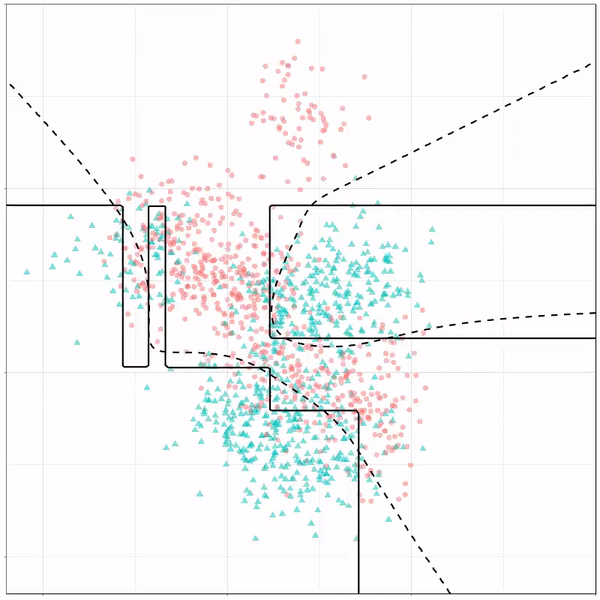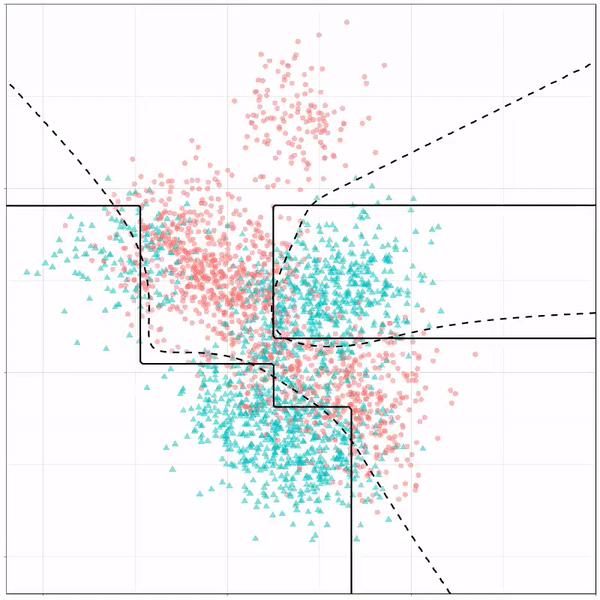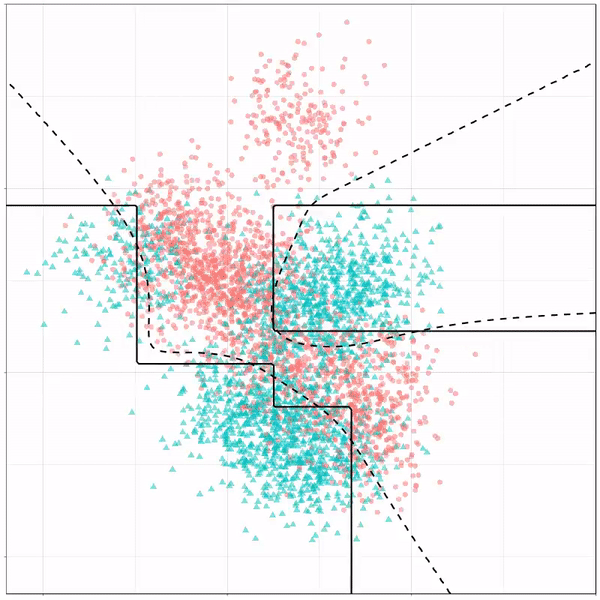
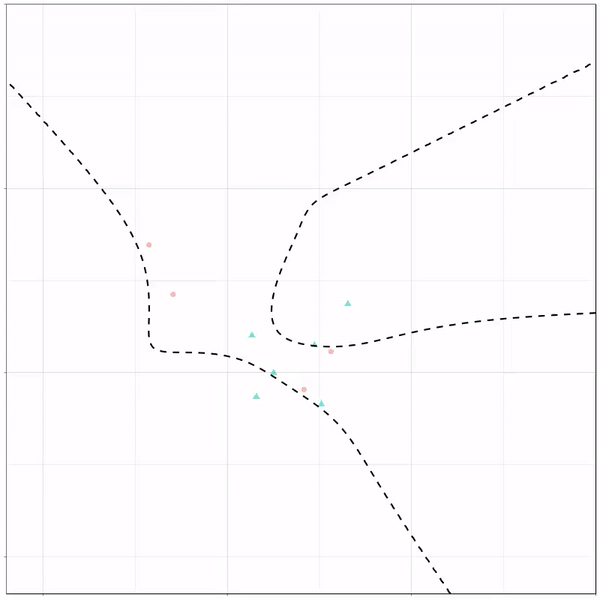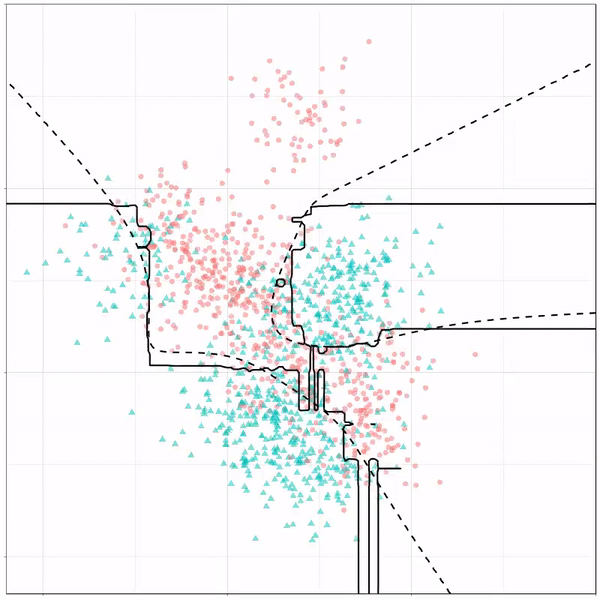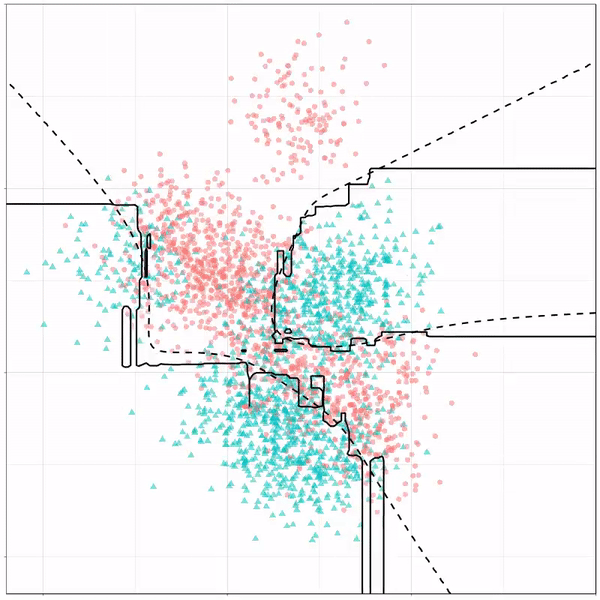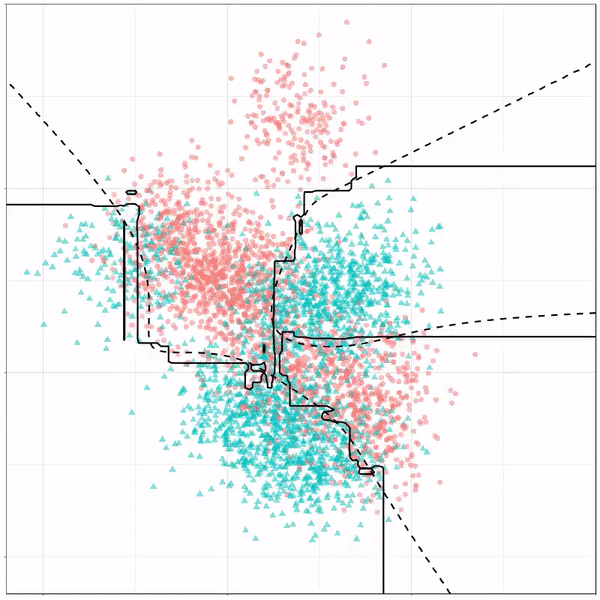
A thread of classifiers learning a decision rule. Dashed line is optimal boundary. Animations with #gganimate by @thomasp85 and @drob. #rstats
Logistic regression {stats::glm} with each class having normally distributed features. (1/n) pic.twitter.com/kKmqdO2zGy
Below is the GIF which I extracted using EZgif.com.
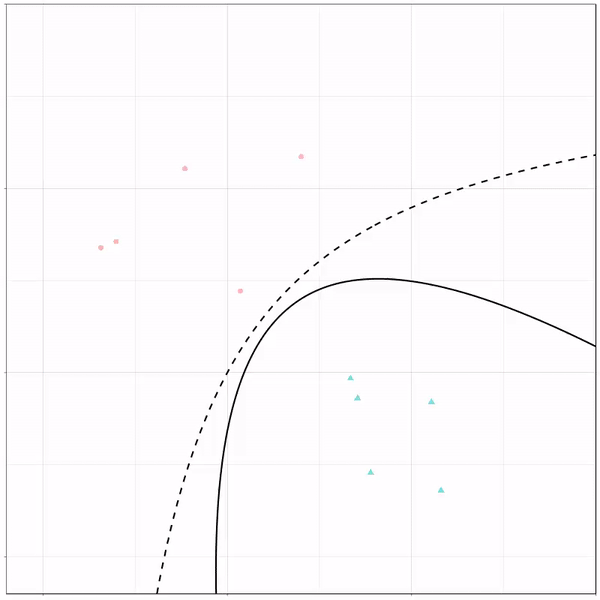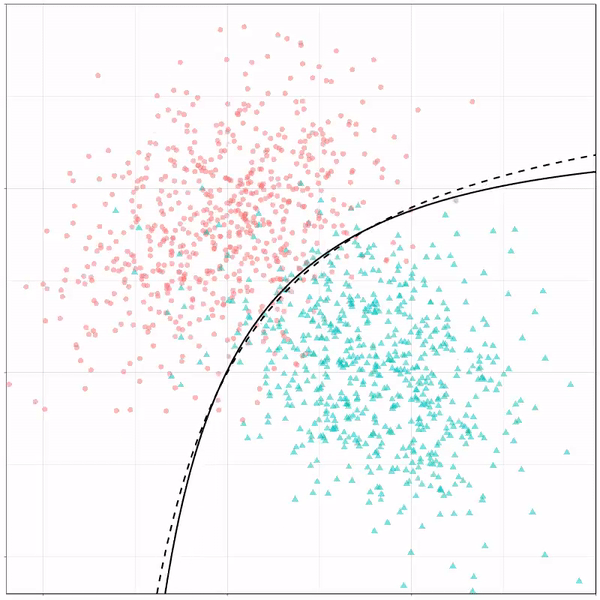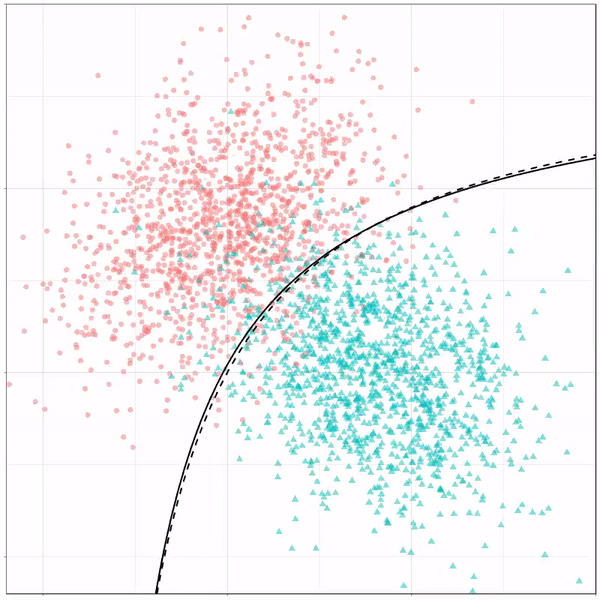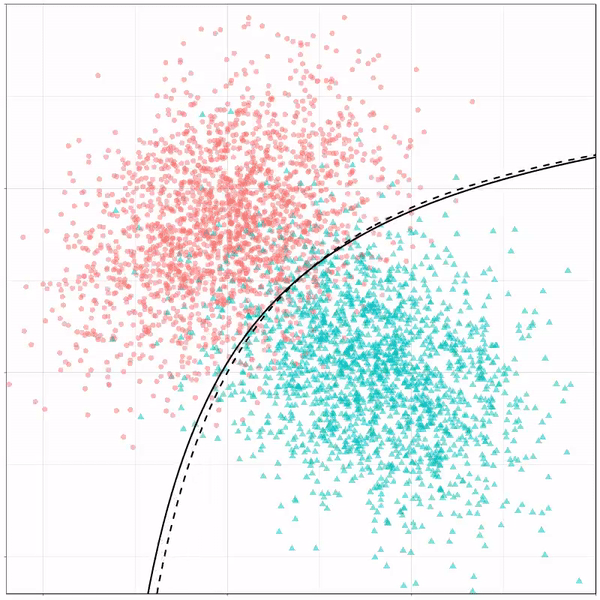
What you see is observations from two classes, say cats and dogs, each represented using colored dots. The dots are placed along X and Y axes, which represent variables about the observations. Their tail lengths and their hairyness, for instance.
Now there’s an optimal way to seperate these classes, which is the dashed line. That line best seperates the cats from the dogs based on these two variables X and Y. As this is an optimal boundary given this data, it is stable, it does not change.
However, there’s also a solid black line, which does change. This line represents the learned boundary by the machine learning model, in this case using logistic regression. As the model is shown more data, it learns, and the boundary is updated. This learned boundary represents the best line with which the model has learned to seperate cats from dogs.
Anything above the boundary is predicted to be class 1, a dog. Everything below predicted to be class 2, a cat. As logistic regression results in a linear model, the seperation boundary is very much linear/straight.
Logistic regression gif by Ryan Holbrook
These animations are great to get a sense of how the models come to their boundaries in the back-end.
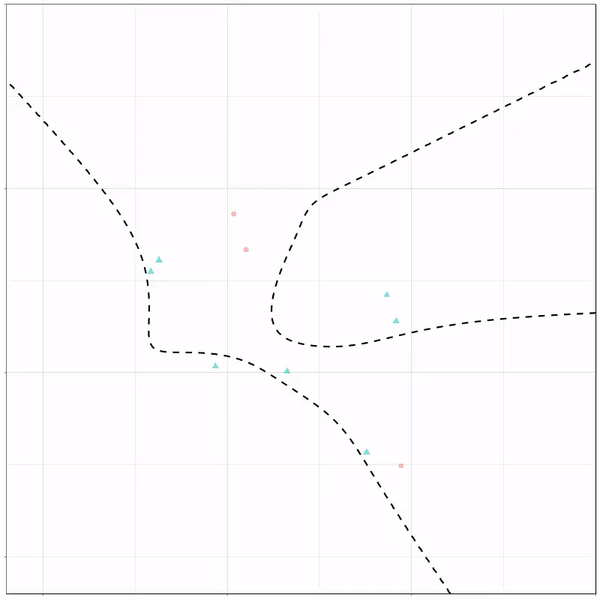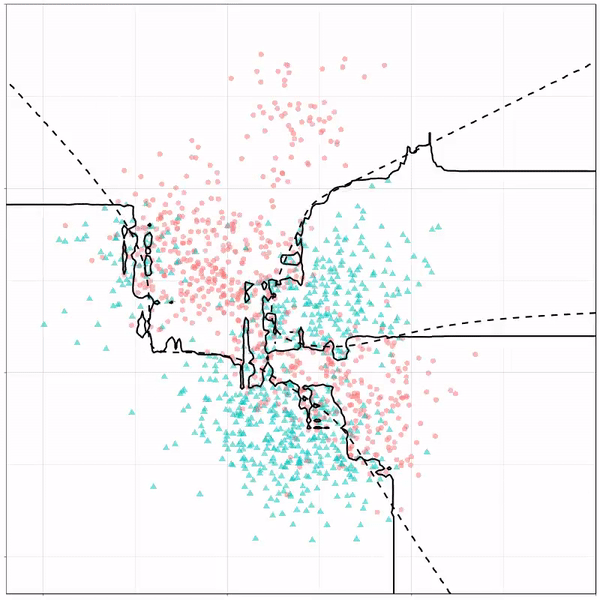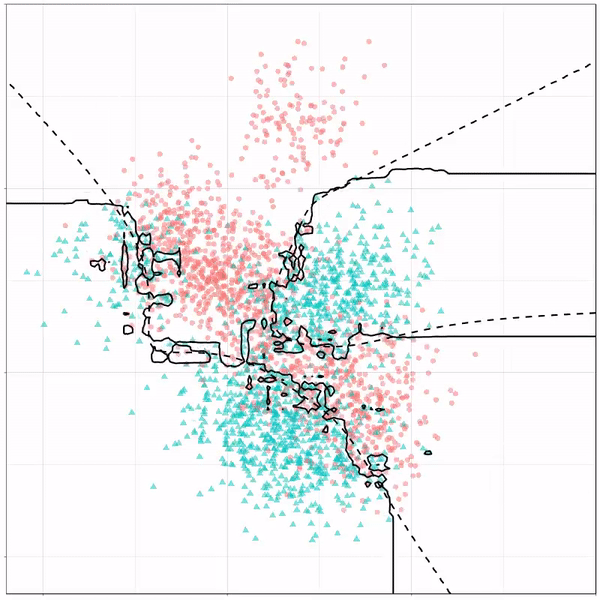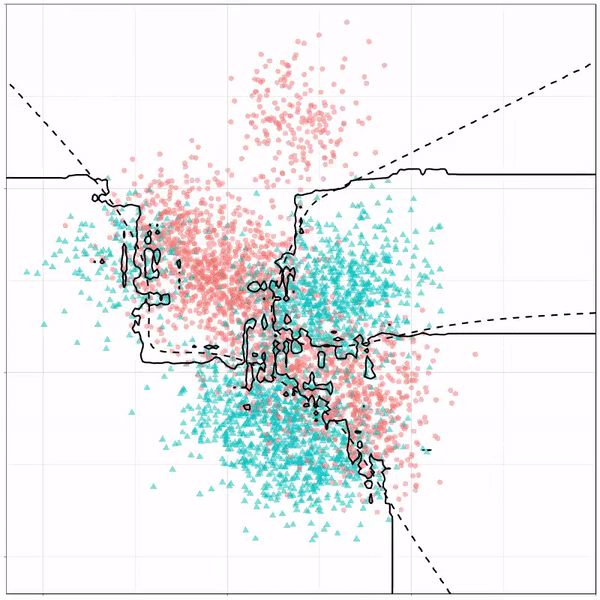
For instance, other machine learning models are able to use non-linear boundaries to dinstinguish classes, such as this quadratic discriminant analysis (qda). This “learned” boundary is much closer to the optimal boundary:
Quadratic discriminant analysis gif by Ryan Holbrook
Multivariate adaptive regression splines gif by Ryan Holbrook
Next, we have the k-nearest neighbors algorithm, which predicts for each point (animal) the class (cat/dog) based on the “k” points closest to it. As you see, this results in a highly fluctuating, localized boundary.
K-nearest neighbors gif by Ryan Holbrook
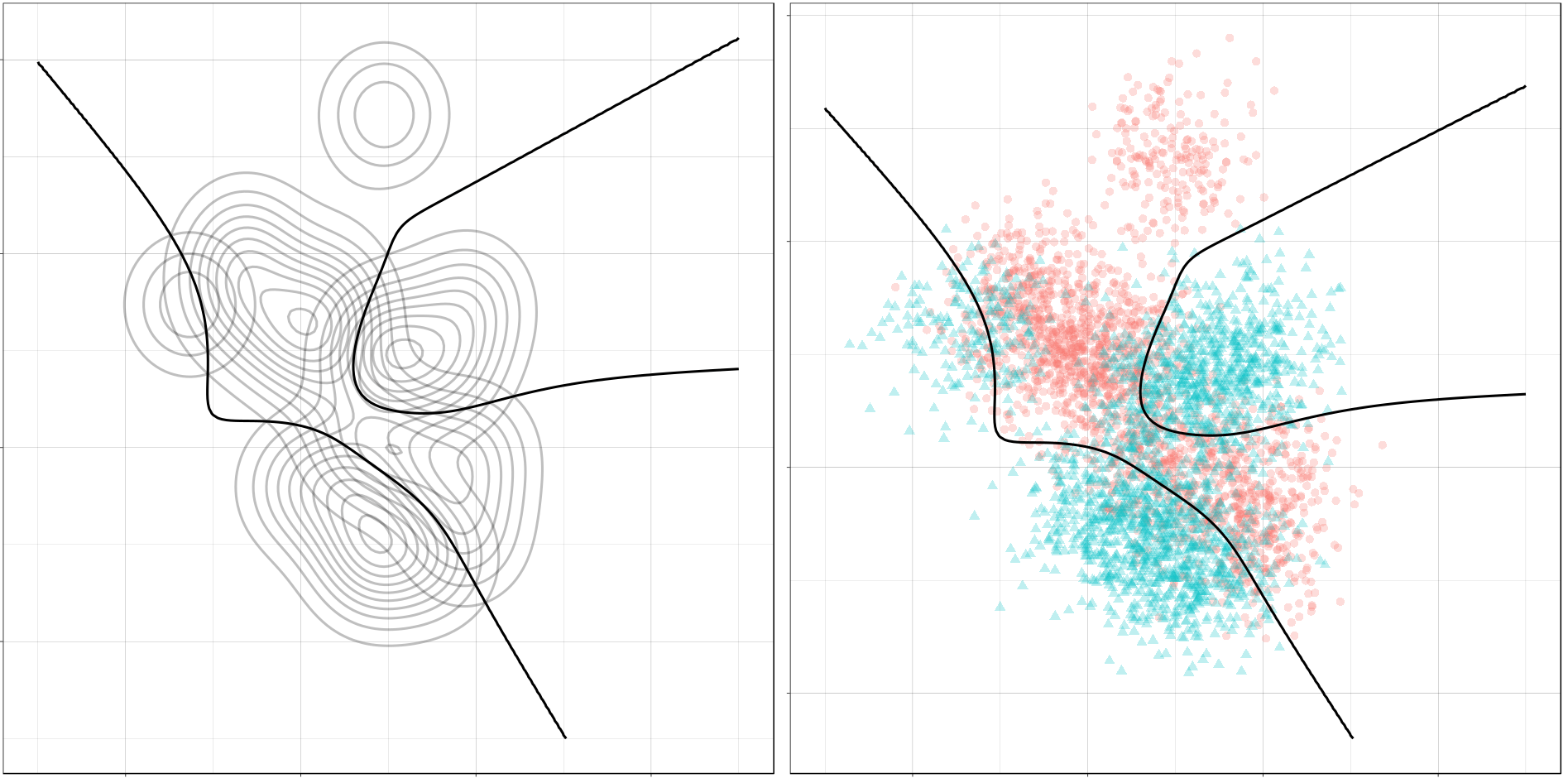
Now, Ryan decided to push the challenge, and simulate new data for two classes with a more difficult decision boundary. The new data and optimal boundaries look like this:
On these data, Ryan put a whole range of non-linear models to work.
Like this support-vector machine, which tries to create optimal boundaries built of support vectors around all the cats and all the dohs (this is definitely not a technical, error-free explanation of what’s happening here).
Let’s jump into some tree-based algorithms and the resulting models. A decision tree classifies data based on multiple, sequential, binary splits. Here, Ryan trained a simple decision tree:
Decision tree gif by Ryan Holbrook
As well as it’s big brother, a random forest, which uses hundreds of trees in the back end and thus results in a more flexible boundary:
Random forest gif by Ryan Holbrook
Extreme gradient boosting is also a tree-based algorithm, which leverages many machine learning techniques to optimize the bias-variance tradeoff. Here’s an earlier blog on how to get started with Xgboost in Python or R:
Case.law seems like a very interesting data source for a machine learning or text mining project:
The Caselaw Access Project (“CAP”) expands public access to U.S. law. Our goal is to make all published U.S. court decisions freely available to the public online, in a consistent format, digitized from the collection of the Harvard Law Library.
The capstone of the Caselaw Access Project is a robust set of tools which facilitate access to the cases and their associated metadata. We currently offer five ways to access the data: API, bulk downloads, search, browse, and a historical trends viewer.
Our open-source API is the best option for anybody interested in programmatically accessing our metadata, full-text search, or individual cases.
If you need a large collection of cases, you will probably be best served by our bulk data downloads. Bulk downloads for Illinois and Arkansas are available without a login, and unlimited bulk files are available to research scholars.
Case metadata, such as the case name, citation, court, date, etc., is freely and openly accessible without limitation. Full case text can be freely viewed or downloaded but you must register for an account to do so, and currently you may view or download no more than 500 cases per day. In addition, research scholars can qualify for bulk data access by agreeing to certain use and redistribution restrictions. You can request a bulk access agreement by creating an account and then visiting your account page.
Access limitations on full text and bulk data are a component of Harvard’s collaboration agreement with Ravel Law, Inc. (now part of Lexis-Nexis). These limitations will end, at the latest, in March of 2024. In addition, these limitations apply only to cases from jurisdictions that continue to publish their official case law in print form. Once a jurisdiction transitions from print-first publishing to digital-first publishing, these limitations cease. Thus far, Illinois and Arkansas have made this important and positive shift and, as a result, all historical cases from these jurisdictions are freely available to the public without restriction. We hope many other jurisdictions will follow their example soon.
A different project altogether is helping the team behind Caselaw improve its data quality:
Our data inevitably includes countless errors as part of the digitization process. The public launch of this project is only the start of discovering errors, and we hope you will help us in finding and fixing them.
Some parts of our data are higher quality than others. Case metadata, such as the party names, docket number, citation, and date, has received human review. Case text and general head matter has been generated by machine OCR and has not received human review.
You can report errors of all kinds at our Github issue tracker, where you can also see currently known issues. We particularly welcome metadata corrections, feature requests, and suggestions for large-scale algorithmic changes. We are not currently able to process individual OCR corrections, but welcome general suggestions on the OCR correction process.
Atrebas created this extremely helpful overview page showing how to program standard data manipulation and data transformation routines in R’s famous packages dplyr and data.table.
The document has been been inspired by this stackoverflow question and by the data.table cheat sheet published by Karlijn Willems.
Resources for data.table can be found on the data.table wiki, in the data.table vignettes, and in the package documentation. Reference documents for dplyr include the dplyr cheat sheet, the dplyr vignettes, and the package documentation.
Having trouble understanding how to interpret distribution plots? Or struggling with Q-Q plots? Sven Halvorson penned down a visual tutorial explaining distributions using visualisations of their quantiles.
Because each slice of the distribution is 5% of the total area and the height of the graph is changing, the slices have different widths. It’s like we’re trying to cut a strange shaped cake into 20 equal pieces using parallel cuts. The slices at the center must be thinner since the distribution is denser (taller) than on the edges.
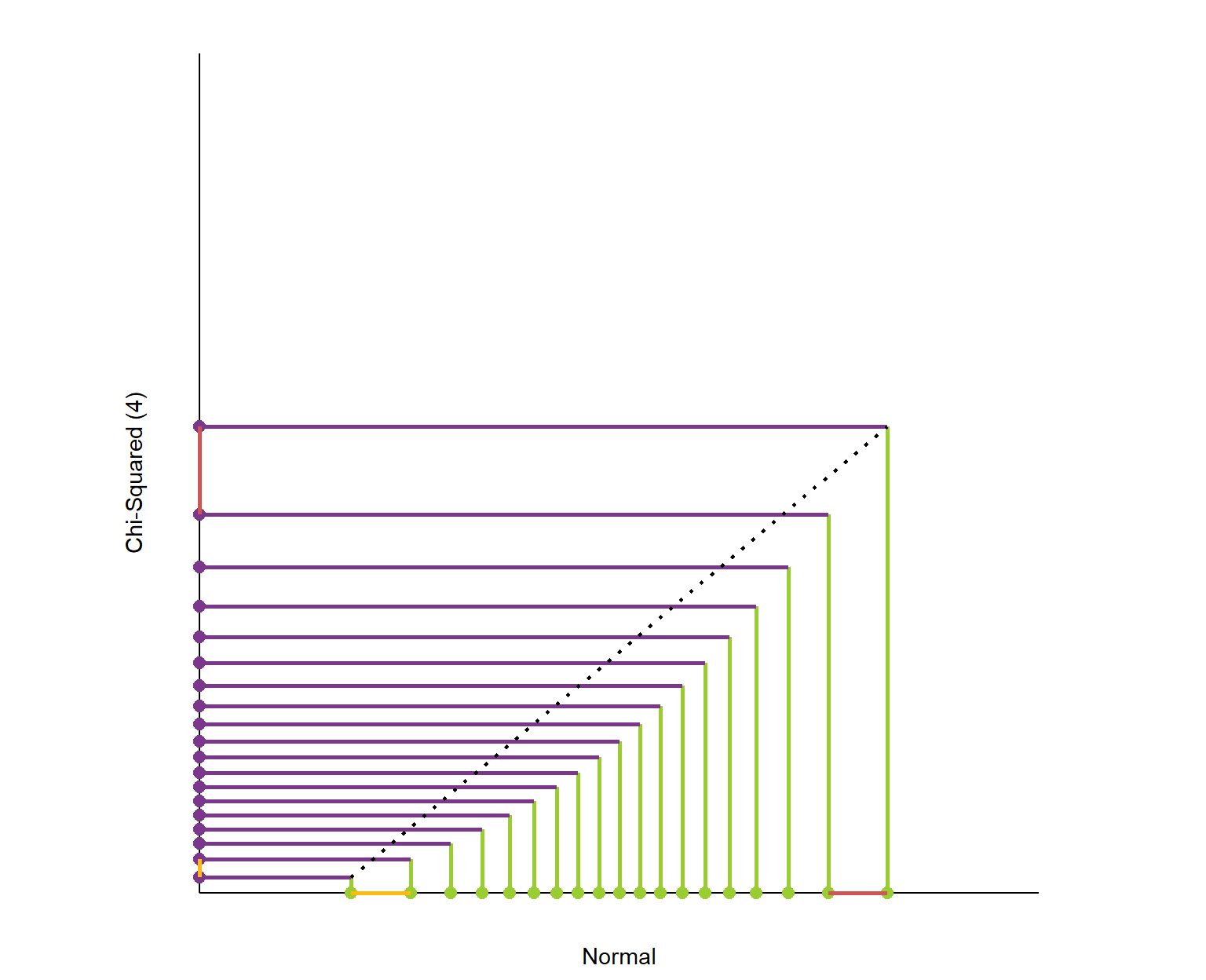
Here is the plot of matching the quantiles of the chi-squared(4) and normal distributions. I’ve again plotted these quantiles over 98% of each distribution’s range. The chi-squared distribution is skewed so its quantiles are packed into a smaller portion of its axis.
What is this graph telling us? It shows that the exchange rate between the quantiles of the two distributions is not constant.