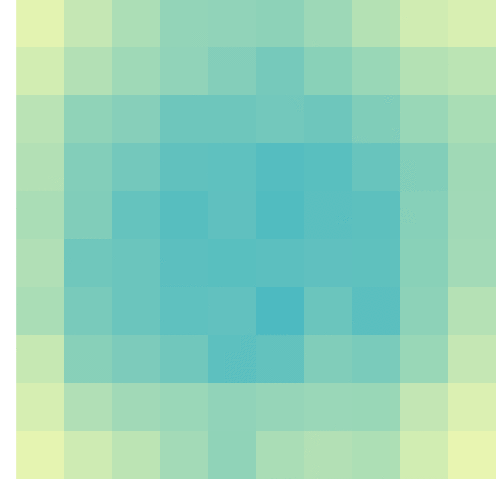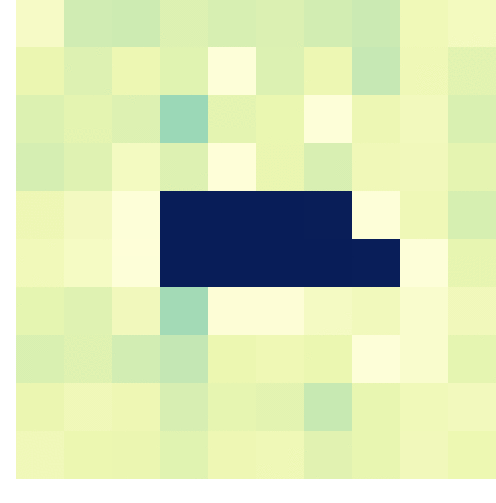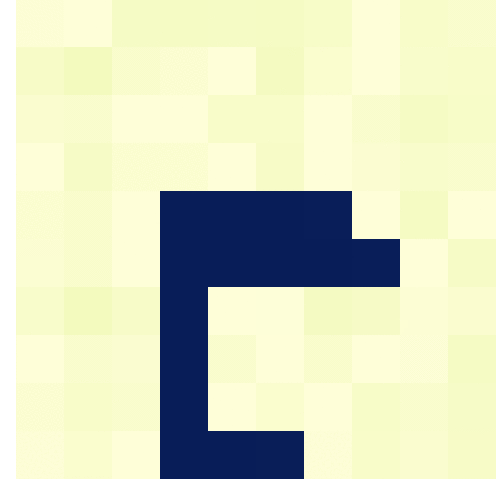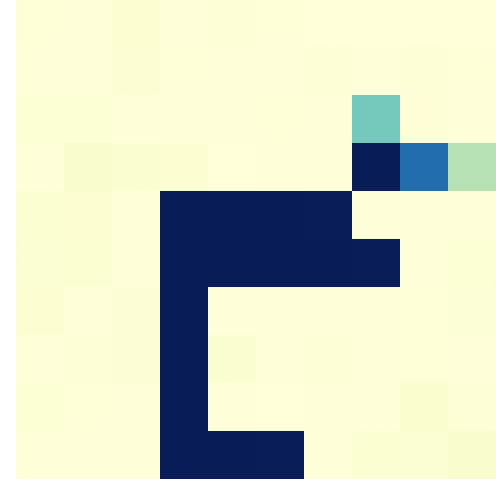Came across this awesome Youtube video that blew my mind. Definitely a handy resource if you want to explain the inner workings of neural networks. Have a look!
Past days, I discovered this series of blogs on how to win the classic game of Battleships (gameplay explanation) using different algorithmic approaches. I thought they might amuse you as well : )
The story starts with this 2012 Datagenetics blog where Nick Berry constrasts four algorithms’ performance in the game of Battleships. The resulting levels of artificial intelligence (AI) seem to compare respectively to a distracted baby, two sensible adults, and a mathematical progidy.
The first, stupidest approach is to just take Random shots. The AI resulting from such an algorithm would just pick a random tile to shoot at each turn. Nick simulated 100 million games with this random apporach and computed that the algorithm would require 96 turns to win 50% of games, given that it would not be defeated before that time. At best, the expertise level of this AI would be comparable to that of a distracted baby. Basically, it would lose from the average toddler, given that the toddler would survive the boredom of playing such a stupid AI.
A first major improvement results in what is dubbed the Hunt algorithm. This improved algorithm includes an instruction to explore nearby spaces whenever a prior shot hit. Every human who has every played Battleships will do this intuitively. A great improvement indeed as Nick’s simulations demonstrated that this Hunt algorithm completes 50% of games within ~65 turns, as long as it is not defeated beforehand. Your little toddler nephew will certainly lose, and you might experience some difficulty as well from time to time.
A visual representation of the “Hunting” of the algorithm on a hit [via]
Another minor improvement comes from adding the so-called Parity principle to this Hunt algorithm (i.e., Nick’s Hunt + Parity algorithm). This principle instructs the algorithm to take into account that ships will always cover odd as well as even numbered tiles on the board. This information can be taken into account to provide for some more sensible shooting options. For instance, in the below visual, you should avoid shooting the upper left white tile when you have already shot its blue neighbors. You might have intuitively applied this tactic yourself in the past, shooting tiles in a “checkboard” formation. With the parity principle incorporated, the median completion rate of our algorithm improves to ~62 turns, Nick’s simulations showed.
Now, Nick’s final proposed algorithm is much more computationally intensive. It makes use of Probability Density Functions. At the start of every turn, it works out all possible locations that every remaining ship could fit in. As you can imagine, many different combinations are possible with five ships. These different combinations are all added up, and every tile on the board is thus assigned a probability that it includes a ship part, based on the tiles that are already uncovered.
Computing the probability that a tile contains a ship based on all possible board layouts [via]
At the start of the game, no tiles are uncovered, so all spaces will have about the same likelihood to contain a ship. However, as more and more shots are fired, some locations become less likely, some become impossible, and some become near certain to contain a ship. For instance, the below visual reflects seven misses by the X’s and the darker tiles which thus have a relatively high probability of containing a ship part.
An example distribution with seven misses on the grid. [via]
Nick simulated 100 million games of Battleship for this probabilistic apporach as well as the prior algorithms. The below graph summarizes the results, and highlight that this new probabilistic algorithm greatly outperforms the simpler approaches. It completes 50% of games within ~42 turns! This algorithm will have you crying at the boardgame table.
Relative performance of the algorithms in the Datagenetics blog, where “New Algorithm” refers to the probabilistic approach and “No Parity” refers to the original “Hunt” approach.
Reddit user /u/DataSnaek reworked this probablistic algorithm in Python and turned its inner calculations into a neat GIF. Below, on the left, you see the probability of each square containing a ship part. The brighter the color (white <- yellow <- red <- black), the more likely a ship resides at that location. It takes into account that ships occupy multiple consecutive spots. On the right, every turn the algorithm shoots the space with the highest probability. Blue is unknown, misses are in red, sunk ships in brownish, hit “unsunk” ships in light blue (sorry, I am terribly color blind).
The probability matrix as a heatmap for every square after each move in the game. [via]
This latter attempt by DataSnaek was inspired by Jonathan Landy‘s attempt to train a reinforcement learning (RL) algorithm to win at Battleships. Although the associated GitHub repository doesn’t go into much detail, the approach is elaborately explained in this blog. However, it seems that this specific code concerns the training of a neural network to perform well on a very small Battleships board, seemingly containing only a single ship of size 3 on a board with only a single row of 10 tiles.
Fortunately, Sue He wrote about her reinforcement learning approach to Battleships in 2017. Building on the open source phoenix-battleship project, she created a Battleship app on Heroku, and asked co-workers to play. This produced data on 83 real, two-person games, showing, for instance, that Sue’s coworkers often tried to hide their size 2 ships in the corners of the Battleships board.
Probability heatmaps of ship placement in Sue He’s reinforcement learning Battleships project [via]
Next, Sue scripted a reinforcement learning agent in PyTorch to train and learn where to shoot effectively on the 10 by 10 board. It became effective quite quickly, requiring only 52 turns (on average over the past 25 games) to win, after training for only a couple hundreds games.
The performance of the RL agent at Battleships during the training process [via]
However, as Sue herself notes in her blog, disappointly, this RL agent still does not outperform the probabilistic approach presented earlier in this current blog.
Reddit user /u/christawful faced similar issues. Christ (I presume he is called) trained a convolutional neural network (CNN) with the below architecture on a dataset of Battleships boards. Based on the current board state (10 tiles * 10 tiles * 3 options [miss/hit/unknown]) as input data, the intermediate convolutional layers result in a final output layer containing 100 values (10 * 10) depicting the probabilities for each tile to result in a hit. Again, the algorithm can simply shoot the tile with the highest probability.
Christ’s convolutional neural network architecture for Battleships [via]
Christ was nice enough to include GIFs of the process as well [via]. The first GIF shows the current state of the board as it is input in the CNN — purple represents unknown tiles, black a hit, and white a miss (i.e., sea). The next GIF represent the calculated probabilities for each tile to contain a ship part — the darker the color the more likely it contains a ship. Finally, the third picture reflects the actual board, with ship pieces in black and sea (i.e., miss) as white.
As cool as this novel approach was, Chris ran into the same issue as Sue, his approach did not perform better than the purely probablistic one. The below graph demonstrates that while Christ’s CNN (“My Algorithm”) performed quite well — finishing a simulated 9000 games in a median of 52 turns — it did not outperform the original probabilistic approach of Nick Berry — which came in at 42 turns. Nevertheless, Chris claims to have programmed this CNN in a couple of hours, so very well done still.
The performance of Christ’s Battleship CNN compared to Nick Berry’s original algorithms [via]
Interested by all the above, I searched the web quite a while for any potential improvement or other algorithmic approaches. Unfortunately, in vain, as I did not find a better attempt than that early 2012 Datagenics probability algorithm by Nick.
Surely, with today’s mass cloud computing power, someone must be able to train a deep reinforcement learner to become the Battleship master? It’s not all probability right, there must be some patterns in generic playing styles, like Sue found among her colleagues. Or maybe even the ability of an algorithm to adapt to the opponent’s playin style, as we see in Libratus, the poker AI. Maybe the guys at AlphaGo could give it a shot?
For starters, Christ’s provided some interesting improvements on his CNN approach. Moreover, while the probabilistic approach seems the best performing, it might not the most computationally efficient. All in all, I am curious to see whether this story will continue.
Adam Geitgey likes to write about computers and machine learning. He explains machine learning as “generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.” (Part 1)
Adam’s visual explanation of two machine learning applications (original from Part 1)
In the fourth part of his series on machine learning Adam touches on Facial Recognition. Facebook is one of the companies using such algorithms in real-time, allowing them to recognize your friends’ faces after you’ve tagged them only a few times. Facebook reports they recognize faces with 97% accuracy, which is comparable to our own, human facial recognition abilities!
Facebook’s algorithms recognizing and automatically tagging Adam’s family. Helpful or creepy? (original from Part 4)
Adam decided to put up a challenge: would a facial recognition algorithm be able to distinguish Will Ferrell (famous actor) from Chad Smith (famous rock musician)? Indeed, these two celebrities look very much alike:
If you want to train such an algorithm, Adam explain, you need to overcome a series of related problems:
First, look at a picture and find all the faces in it
Second, focus on each face and be able to understand that even if a face is turned in a weird direction or in bad lighting, it is still the same person.
Third, be able to pick out unique features of the face that you can use to tell it apart from other people— like how big the eyes are, how long the face is, etc.
Finally, compare the unique features of that face to all the people you already know to determine the person’s name.
How the facial recognition algorithm steps might work (original from Part 4)
To detect the faces, Adam used Histograms of Oriented Gradients (HOG). All input pictures were converted to black and white (because color is not needed) and then every single pixel in our image is examined, one at a time. Moreover, for every pixel, the algorithm examined the pixels directly surrounding it:
Illustration of the algorithm as it would take in a black and white photo of Will Ferrel (original from Part 4)
The algorithm then checks, for every pixel, in which direction the picture is getting darker and draws an arrow (a gradient) in that direction.
Illustration of how algorithm would reduce a black and white photo of Will Ferrel to gradients (original from Part 4)
However, to do this for every single pixel would require too much processing power, so Adam broke up pictures in 16 by 16 pixel squares. The result is a very simple representation that does capture the basic structure of the original face, based on which we can now spot faces in pictures. Moreover, because we used gradients, the result will be similar regardless of the lighting of the picture.
The original image turned into a HOG representation (original from Part 4)
Now that the computer can spot faces, we need to make sure that it knows that two perspectives of the same face represent the same person. Adam uses landmarks for this: 68 specific points that exist on every face. An algorithm can then be trained to find these points on any face:
The 68 points on the image of Will Ferrell (original from Part 4)
Now the computer knows where the chin, the mouth and the eyes are, the image can be scaled and rotated to center it as best as possible:
The image of Will Ferrell transformed (original from Part 4)
Adam trained a Deep Convolutional Neural Network to generate 128 measurements for each face that best distinguish it from faces of other people. This network needs to train for several hours, going through thousands and thousands of face pictures. If you want to try this step yourself, Adam explains how to run OpenFace’s lua script. This study at Google provides more details, but it basically looks like this:
The training process visualized (original from Part 4)
After hours of training, the neural net will output 128 numbers accurately representing the specific face put in. Now, all you need to do is check which face in your database is most closely resembled by those 128 numbers, and you have your match! Many algorithms can do this final check, and Adam trained a simple linear SVM classifier on twenty pictures of Chad Smith, Will Ferrel, and Jimmy Falon (the host of a talkshow they both visited).
In the end, Adam’s machine had learned to distinguish these three people – two of whom are nearly indistinguishable with the human eye – in real-time:
Adam Geitgey’s facial recognition algorithm in action: providing real time classifications of the faces of lookalikes Chad Smith and Will Ferrel at Jimmy Falon’s talk show (original from Part 4)
The Deep Learning textbook helps students and practitioners enter the field of machine learning in general and deep learning in particular. Its online version is available online for free whereas a hardcover copy can be ordered here on Amazon. You can click on the topics below to be redirected to the book chapter:
Aaron Jackson, Adrian Bulat, Vasileios Argyriou and Georgios Tzimiropoulos
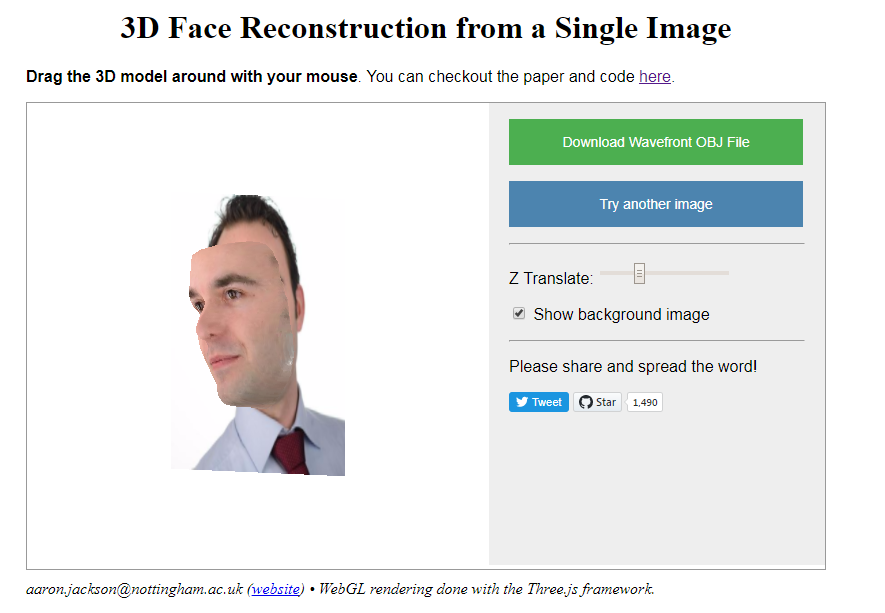
of the Computer Vision Laboratory of the University of Nottingham built a neural network that generates a full 3D image of a single portrait photograph. They turn a photograph like this…
… into an accurately creepy 3D image like this.
You can try it with your own or other photographs here. I found that images with white background get the best results. On their project website you can read more about the underlying convolutional neural network.
Update 21-10-2017: One of my favorite YouTube channels explains how the models were trained and the data used:
Keras is a high-level neural networks API that was developed to enabling fast experimentation with Deep Learning in both Python and R. According to its author Taylor Arnold: Being able to go from idea to result with the least possible delay is key to doing good research. The ideas behind deep learning are simple, so why should their implementation be painful?
Keras comes with the following key features:
Allows the same code to run on CPU or on GPU, seamlessly.
User-friendly API which makes it easy to quickly prototype deep learning models.
Built-in support for convolutional networks (for computer vision), recurrent networks (for sequence processing), and any combination of both.
Supports arbitrary network architectures: multi-input or multi-output models, layer sharing, model sharing, etc. This means that Keras is appropriate for building essentially any deep learning model, from a memory network to a neural Turing machine
Fast implementation of dense neural networks, convolution neural networks (CNN) and recurrent neural networks (RNN) in R or Python, on top of TensorFlow or Theano.
R
R: Installation
The R interface to Keras uses TensorFlow™ as it’s underlying computation engine. First, you have to install the keras R package from GitHub:
This will provide you with a default installation of TensorFlow suitable for use with the keras R package. See the article on TensorFlow installation to learn about more advanced options, including installing a version of TensorFlow that takes advantage of Nvidia GPUs if you have the correct CUDA libraries installed.
R: Getting started in 30 seconds
Keras uses models to organize layers. Sequential models are the simplest structure, simply stacking layers. More complex architectures require the Keras functional API, which allows to build arbitrary graphs of layers.
Here is an example of a sequential model (hosted on this website):
Similarly, generating predictions on new data is easily done:
classes %>% predict(x_test, batch_size =128)
Building more complex models, for example, to answer questions or classify images, is just as fast.
Python
A step-by-step implementation of several Neural Network architectures with Keras in Python can be found on DataCamp. Similarly, one may use this quick cheatsheet to deploy the most basic models.