How do scurvy, astronomy, alchemy and data science relate to each other?
In this goto conference presentation, Lucas Vermeer — Director of Experimentation at Booking.com — uses some amazing storytelling to demonstrate how the value of data (science) is largely by organizations capability to gather the right data — the data they actually need.
It’s a definite recommendation to watch for data scientists and data science leaders out there.
Here are the slides, and they contain some great oneliners:
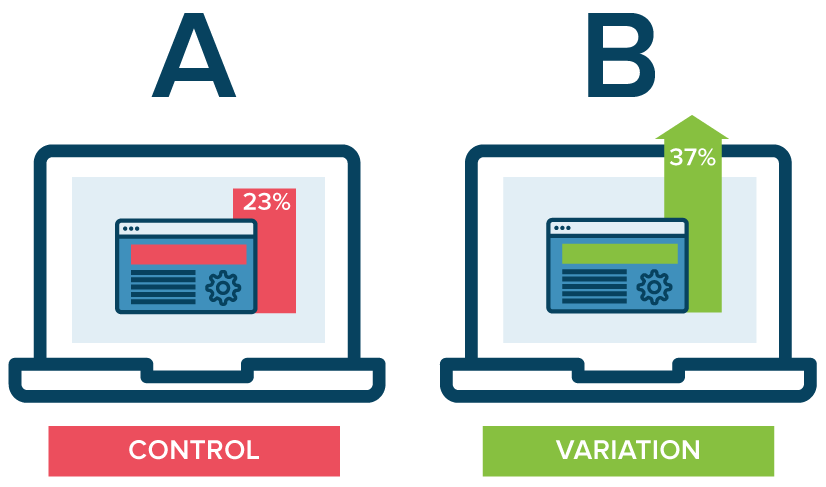
A/B testing is a method of comparing two versions of some thing against each other to determine which is better. A/B tests are often mentioned in e-commerce contexts, where the things we are comparing are web pages.
Business leaders and data scientists alike face a difficult trade-off when running A/B tests: How big should the A/B test be? Or in other words, After collecting how many data points, or running for how many days, should we make a decision whether A or B is the best way to go?
This is a tradeoff because the sample size of an A/B test determines its statistical power. This statistical power, in simple terms, determines the probability of a A/B test showing an effect if there is actually really an effect. In general, the more data you collect, the higher the odds of you finding the real effect and making the right decision.
By default, researchers often aim for 80% power, with a 5% significance cutoff. But is this general guideline really optimal for the tradeoff between costs and benefits in your specific business context? Chris thinks not.
Chris said wrote a great three-piece blog in which he explains how you can mathematically determine the optimal duration of A/B-testing in your own company setting:
Part I: General Overview. Starts with a mostly non-technical overview and ends with a section called “Three lessons for practitioners”.
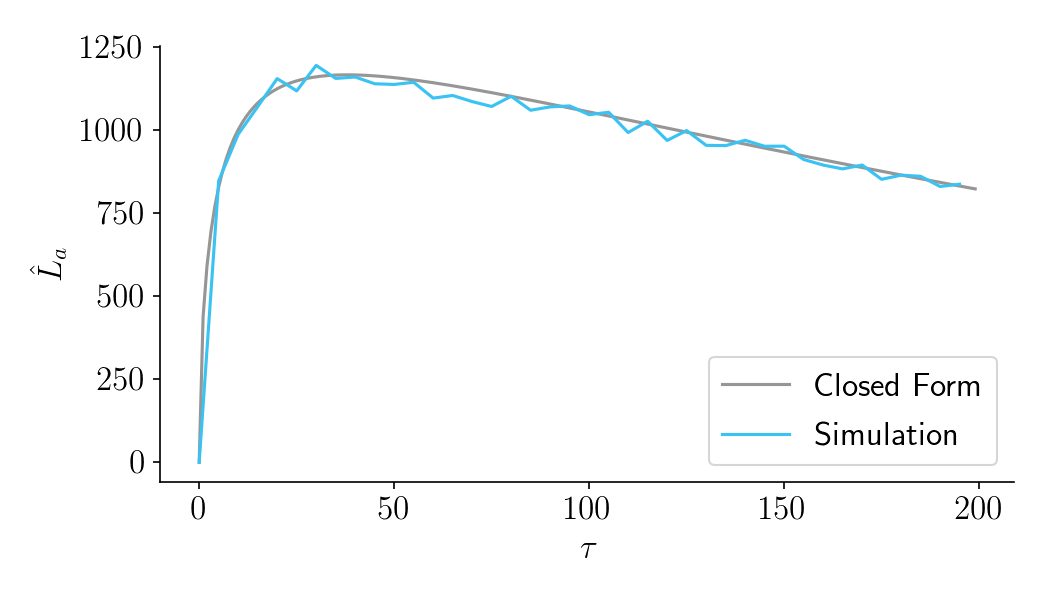
Part II: Expected lift. A more technical section that quantifies the benefits of experimentation as a function of sample size.
Part III: Aggregate time-discounted lift. A more technical section that quantifies the costs of experimentation as a function of sample size. It then combines costs and benefits into a closed-form expression that can be optimized. Ends with an FAQ.
These days, I am often programming in multiple different languages for my projects. I will do some data generation and machine learning in Python. The data exploration and some quick visualizations I prefer to do in R. And if I’m feeling adventureous, I might add some Processing or JavaScript visualizations.
Obviously, I want to track and store the versions of my programs and the changes between them. I probably don’t have to tell you that git is the tool to do so.
Normally, you’d have a .gitignore file in your project folder, and all files that are not listed (or have patterns listed) in the .gitignore file are backed up online.
However, when you are working in multiple languages simulatenously, it can become a hassle to assure that only the relevant files for each language are committed to Github.
Each language will have their own “by-files”. R projects come with .Rdata, .Rproj, .Rhistory and so on, whereas Python projects generate pycaches and what not. These you don’t want to commit preferably.
Here you simply enter the operating systems, IDEs, or Programming languages you are working with, and it will generate the appropriate .gitignore contents for you.
Let’s try it out
For my current project, I am working with Python and R in Visual Studio Code. So I enter:
And Voila, I get the perfect .gitignore including all specifics for these programs and languages:
# Created by https://www.gitignore.io/api/r,python,visualstudiocode
# Edit at https://www.gitignore.io/?templates=r,python,visualstudiocode
### Python ###
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
pip-wheel-metadata/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# pyenv
.python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# Mr Developer
.mr.developer.cfg
.project
.pydevproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
### R ###
# History files
.Rhistory
.Rapp.history
# Session Data files
.RData
.RDataTmp
# User-specific files
.Ruserdata
# Example code in package build process
*-Ex.R
# Output files from R CMD build
/*.tar.gz
# Output files from R CMD check
/*.Rcheck/
# RStudio files
.Rproj.user/
# produced vignettes
vignettes/*.html
vignettes/*.pdf
# OAuth2 token, see https://github.com/hadley/httr/releases/tag/v0.3
.httr-oauth
# knitr and R markdown default cache directories
*_cache/
/cache/
# Temporary files created by R markdown
*.utf8.md
*.knit.md
### R.Bookdown Stack ###
# R package: bookdown caching files
/*_files/
### VisualStudioCode ###
.vscode/*
!.vscode/settings.json
!.vscode/tasks.json
!.vscode/launch.json
!.vscode/extensions.json
### VisualStudioCode Patch ###
# Ignore all local history of files
.history
# End of https://www.gitignore.io/api/r,python,visualstudiocode
Version control is an essential tool for any software developer. Hence, any respectable data scientist has to make sure his/her analysis programs and machine learning pipelines are reproducible and maintainable through version control.
Often, we use git for version control. If you don’t know what git is yet, I advise you begin here. If you work in R, start here and here. If you work in Python, start here.
This blog is intended for those already familiar working with git, but who want to learn how to write better, more informative git commit messages. Actually, this blog is just a summary fragment of this original blog by Chris Beams, which I thought deserved a wider audience.
Summarize changes in around 50 characters or less
More detailed explanatory text, if necessary. Wrap it to about 72
characters or so. In some contexts, the first line is treated as the
subject of the commit and the rest of the text as the body. The
blank line separating the summary from the body is critical (unless
you omit the body entirely); various tools like `log`, `shortlog`
and `rebase` can get confused if you run the two together.
Explain the problem that this commit is solving. Focus on why you
are making this change as opposed to how (the code explains that).
Are there side effects or other unintuitive consequences of this
change? Here's the place to explain them.
Further paragraphs come after blank lines.
- Bullet points are okay, too
- Typically a hyphen or asterisk is used for the bullet, preceded
by a single space, with blank lines in between, but conventions
vary here
If you use an issue tracker, put references to them at the bottom,
like this:
Resolves: #123
See also: #456, #789
If you’re having a hard time summarizing your commits in a single line or message, you might be committing too many changes at once. Instead, you should try to aim for what’s called atomic commits.
The assumption that a Machine Learning (ML) project is done when a trained model is put into production is quite faulty. Neverthless, according to Alexandre Gonfalonieri — artificial intelligence (AI) strategist at Philips — this assumption is among the most common mistakes of companies taking their AI products to market.
Actually, in the real world, we see pretty much the opposite of this assumption. People like Alexandre therefore strongly recommend companies keep their best data scientists and engineers on a ML project, especially after it reaches production!
Why?
If you’ve ever productionized a model and really started using it, you know that, over time, your model will start performing worse.
In order to maintain the original accuracy of a ML model which is interacting with real world customers or processes, you will need to continuously monitor and/or tweak it!
In the best case, algorithms are retrained with each new data delivery. This offers a maintenance burden that is not fully automatable. According to Alexandre, tending to machine learning models demands the close scrutiny, critical thinking, and manual effort that only highly trained data scientists can provide.
This means that there’s a higher marginal cost to operating ML products compared to traditional software. Whereas the whole reason we are implementing these products is often to decrease (the) costs (of human labor)!
What causes this?
Your models’ accuracy will often be at its best when it just leaves the training grounds.
Building a model on relevant and available data and coming up with accurate predictions is a great start. However, for how long do you expect those data — that age by the day — continue to provide accurate predictions?
Chances are that each day, the model’s latent performance will go down.
This phenomenon is called concept drift, and is heavily studied in academia but less often considered in business settings. Concept drift means that the statistical properties of the target variable, which the model is trying to predict, change over time in unforeseen ways.
In simpler terms, your model is no longer modelling the outcome that it used to model. This causes problems because the predictions become less accurate as time passes.
Particularly, models of human behavior seem to suffer from this pitfall.
The key is that, unlike a simple calculator, your ML model interacts with the real world. And the data it generates and that reaches it is going to change over time. A key part of any ML project should be predicting how your data is going to change over time.
You need to create a monitoring strategy before reaching production!
According to Alexandre, as soon as you feel confident with your project after the proof-of-concept stage, you should start planning a strategy for keeping your models up to date.
How often will you check in?
On the whole model, or just some features?
What features?
In general, sensible model surveillance combined with a well thought out schedule of model checks is crucial to keeping a production model accurate. Prioritizing checks on the key variables and setting up warnings for when a change has taken place will ensure that you are never caught by a surprise by a change to the environment that robs your model of its efficacy.
Your strategy will strongly differ based on your model and your business context.
Moreover, there are many different types of concept drift that can affect your models, so it should be a key element to think of the right strategy for you specific case!
Once you observe degraded model performance, you will need to redesign your model (pipeline).
One solution is referred to as manual learning. Here, we provide the newly gathered datato our model and re-train and re-deploy it just like the first time we build the model. If you think this sounds time-consuming, you are right. Moreover, the tricky part is not refreshing and retraining a model, but rather thinking of new features that might deal with the concept drift.
A second solution could be to weight your data. Some algorithms allow for this very easily. For others you will need to custom build it in yourself. One recommended weighting schema is to use the inversely proportional age of the data. This way, more attention will be paid to the most recent data (higher weight) and less attention to the oldest of data (smaller weight) in your training set. In this sense, if there is drift, your model will pick it up and correct accordingly.
According to Alexandre and many others, the third and best solution is to build your productionized system in such a way that you continuously evaluate and retrain your models. The benefit of such a continuous learning system is that it can be automated to a large extent, thus reducing (the human labor) maintance costs.
Although Alexandre doesn’t expand on how to do these, he does formulate the three steps below:
In my personal experience, if you have your model retrained (automatically) every now and then, using a smart weighting schema, and keep monitoring the changes in the parameters and for several “unit-test” cases, you will come a long way.
If you’re feeling more adventureous, you could improve on matters by having your model perform some exploration (at random or rule-wise) of potential new relationships in your data (see for instance multi-armed bandits). This will definitely take you a long way!