YouTube recommended I’d watch this recorded presentation by Raymond Hettinger at PyBay2019 last October. Quite a long presentation for what I’d normally watch, but what an eye-openers it contains!
Raymond Hettinger is a Python core developer and in this video he presents 10 programming strategies in these 60 minutes, all using live examples. Some are quite obvious, but the presentation and examples make them very clear. Raymond presents some serious programming truths, and I think they’ll stick.
First, Raymond discusses chunking and aliasing. He brings up the theory that the human mind can only handle/remember 7 pieces of information at a time, give or take 2. Anything above proves to much cognitive load, and causes discomfort as well as errors. Hence, in a programming context, we need to make sure programmers can use all 7 to improve the code, rather than having to decypher what’s in front of them. In a programming context, we do so by modularizing and standardizing through functions, modules, and packages. Raymond uses the Python random module to hightlight the importance of chunking and modular code. This part was quite long, but still interesting.
For the next two strategies, Raymond quotes the Feinmann method of solving problems: “(1) write down a clear problem specification; (2) think very, very hard; (3) write down a solution”. Using the example of a tree walker, Raymond shows how the strategies of incremental development and solving simpler programs can help you build programs that solve complex problems. This part only lasts a couple of minutes but really underlines the immense value of these strategies.

Next, Raymond touches on the DRY principle: Don’t Repeat Yourself. But in a context I haven’t seen it in yet, object oriented programming [OOP], classes, and inherintance.
Raymond continues to build his arsenal of programming strategies in the next 10 minutes, where he argues that programmers should repeat tasks manually until patterns emerge, before they starting moving code into functions. Even though I might not fully agree with him here, he does have some fun examples of file conversion that speak in his case.
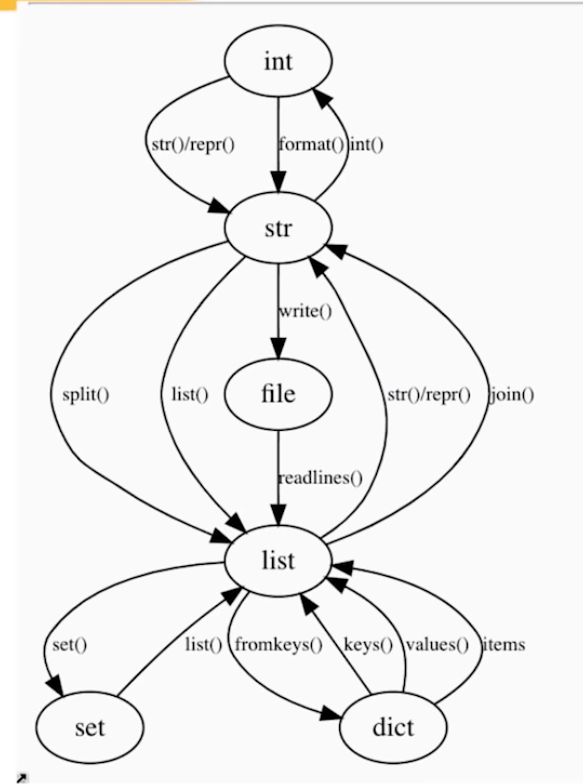
Lastly, Raymond uses the graph below to make the case that OOP is a graph traversal problem. According to Raymond, the Python ecosystem is so rich that there’s often no need to make new classes. You can simply look at the graph below. Look for the island you are currently on, check which island you need to get to, and just use the methods that are available, or write some new ones.
While there were several more strategies that Raymond wanted to discuss, he doesn’t make it to the end of his list of strategies as he spend to much time on the first, chunking bit. Super curious as to the rest? Contact Raymond on Twitter.