I’ve seen a fair share of Tinder experiments come by, for instance, someone A/B-testing attractiveness with and without facial hair, but these new two posts on Medium are the best I’ve come across so far.
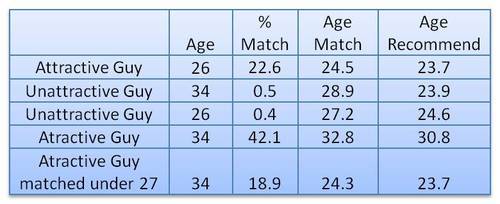
In his first experiment, this self-proclaimed worst online dater went catfishing. He made a Tinder account using stock photos of attractive and less attractive and old and young guys, looking and sampled some like ratio’s.
Basically, his conclusion was that “Tinder actually can work, but pretty much only if you are an attractive guy”
https://worst-online-dater.tumblr.com/post/99441021279/tinder-experiments
In the second experiment, the author decided to treat Tinder as an economy and study it as an (socio-)economist would:
The wealth of an economy is quantified in terms its currency. […] In Tinder the currency is “likes”. […] Wealth in Tinder is not distributed equally. Attractive guys have more wealth in the Tinder economy (get more “likes”) than unattractive guys do. […] An unequal wealth distribution is to be expected, but there is a more interesting question: What is the degree of this unequal wealth distribution and how does this inequality compare to other economies?
Original Medium Post by Worst Online Dater
The author notes some caveats of this analysis. First and foremost, the data was collected in quite an unethical way, by asking questions to 27 of the matches with the fake accounts the author set up. Moreover, self-report bias is quite likely, as it’s easy to lie on Tinder. Still, the results are quite amusing:
Basically, “the bottom 80% of men are fighting over the bottom 22% of women and the top 78% of women are fighting over the top 20% of men”

The Lorenz curve shows the proportion of wealth owned by the bottom x% of a population. If wealth was equally distributed the curve would be perfectly diagonal (a 45 degree slope). The steeper the slope, the less inequal an economy. The below shows the curve for a perfectly equal economy, the US economy, and the estimated Tinder economy:

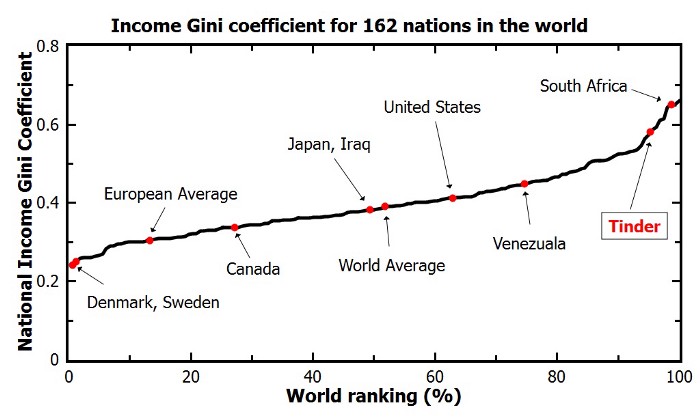
Similarly, the Gini coefficient can be used to represent the wealth equality of an economy. It ranges from 0 to 1, where 0 corresponds with perfect equality (everybody has the same wealth) and 1 corresponds with perfect inequality (one dictator with all the wealth). While most European countries, and even the US, score quite low on this Gini index, the Tinder economy is estimated to be much more towards the lower end.
Finally, based on the collected data, the author was able to reduce Tinder Male Attractiveness to a function of the number of likes received:

According to my last post, the most attractive men will be liked by only approximately 20% of all the females on Tinder. […] Unfortunately, this percentage decreases rapidly as you go down the attractiveness scale. According to this analysis a man of average attractiveness can only expect to be liked by slightly less than 1% of females (0.87%). This equates to 1 “like” for every 115 females.
The good news is that if you are only getting liked by a few girls on Tinder you shouldn’t take it personally. You aren’t necessarily unattractive. You can be of above average attractiveness and still only get liked by a few percent of women on Tinder. The bad news is that if you aren’t in the very upper echelons of Tinder wealth (i.e. attractiveness) you aren’t likely to have much success using Tinder. You would probably be better off just going to a bar or joining some coed recreational sports team.
Original Medium Post by Worst Online Dater