Cohen’s d (wiki) is a statistic used to indicate the standardised difference between two means. Resarchers often use it to compare the averages between groups, for instance to determine that there are higher outcomes values in a experimental group than in a control group.
Researchers often use general guidelines to determine the size of an effect. Looking at Cohen’s d, psychologists often consider effects to be small when Cohen’s d is between 0.2 or 0.3, medium effects (whatever that may mean) are assumed for values around 0.5, and values of Cohen’s d larger than 0.8 would depict large effects (e.g., University of Bath).
The two groups’ distributions belonging to small, medium, and large effects visualized
By the way, Kristoffer hosts many other interesting visualization tools (most made with JavaScript’s D3 library) on statistics and statistical phenomena on his website, have a look!
I really like generative art, or so-called algorithmic art. Basically, it means you take a pattern or a complex system of rules, and apply it to create something new following those patterns/rules.
When I finished my PhD, I got a beautiful poster of where the k-nearest neighbors algorithms was used to generate a set of connected points.
As we recently moved into our new house, I decided I wanted to have a brother for the knn-poster. So I did some research in algorithms I wanted to use to generate a painting. I found some very cool ones, of which I unforunately can’t recollect the artists anymore:
Note: these are NOT mine
However, I preferred to make one myself. So we again turned to the work of the author that made the knn-poster: Marcus Volz.
He has written (in R) many other algorithms. And we found that one specifically nicely matched the knn-poster. His metropolis – or generative city:
However, I wanted to make one myself, so I download Marcus code, and tweaked it a bit. Most importantly, I made it start in the center, made it fill up the whole space, and I made it run more efficient so I could generate a couple dozen large cities quickly, and pick the one I liked most. Here’s the end result:
I recently visited a data science meetup where one of the speakers — Harm Bodewes — spoke about playing out the Monty Hall problem with his kids.
TheMonty Hall problemis probability puzzle. Based on the American television game show Let’s Make a Deal and its host, named Monty Hall:
You’re given the choice of three doors.
Behind one door sits a prize: a shiny sports car.
Behind the others doors, something shitty, like goats.
You pick a door — say, door 1.
Now, the host, who knows what’s behind the doors, opens one of the other doors — say, door 2 — which reveals a goat.
The host then asks you: Do you want to stay with door 1, or would you like to switch to door 3?
The probability puzzle here is:
Is switching doors the smart thing to do?
Back to my meetup.
Harm — the presenter — had ran the Monty Hall experiment with his kids.
Twenty-five times, he had hidden candy under one of three plastic cups. His kids could then pick a cup, he’d remove one of the non-candy cups they had not picked, and then he’d proposed them to make the switch.
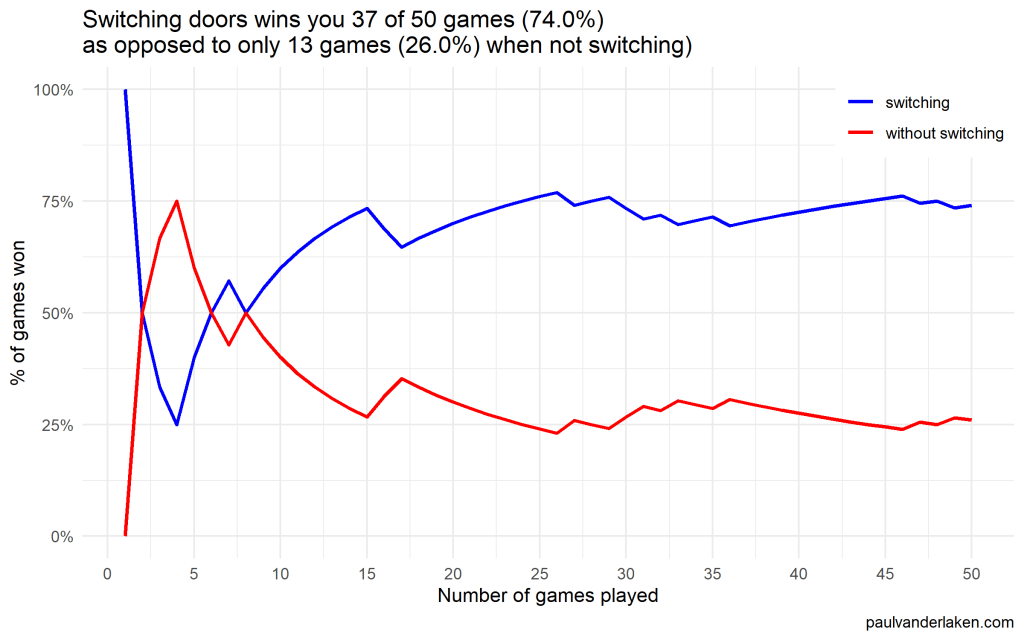
The results he had tracked, and visualized in a simple Excel graph. And here he was presenting these results to us, his Meetup audience.
People (also statisticans) had been arguing whether it is best to stay or switch doors for years. Yet, here, this random guy ran a play-experiment and provided very visual proof removing any doubts you might have yourself.
You really need to switch doors!
At about the same time, I came across this Github repo by Saghir, who had made some vectorised simulations of the problem in R. I thought it was a fun excercise to simulate and visualize matters in two different data science programming languages — Python & R — and see what I’d run in to.
So I’ll cut to the chase.
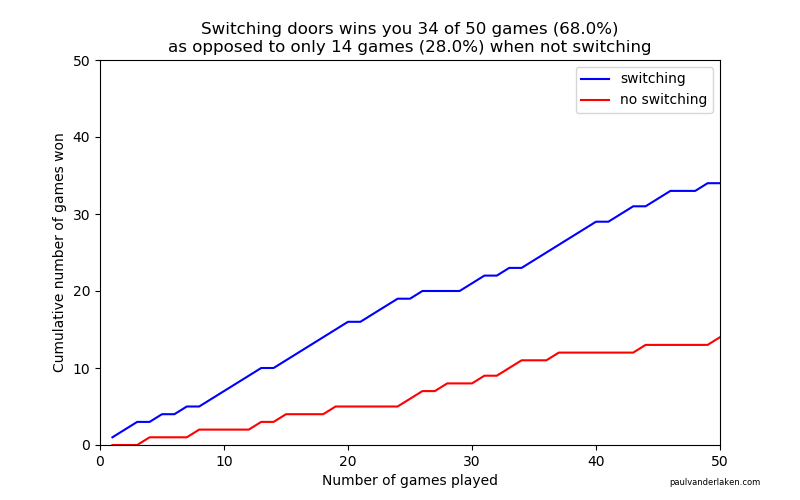
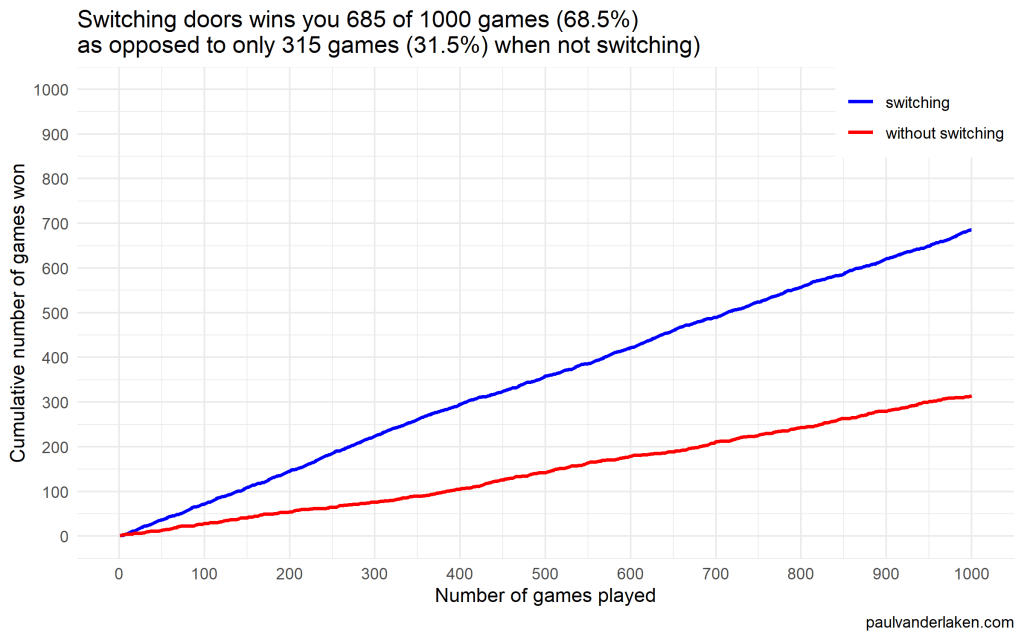
As we play more and more games against Monty Hall, it becomes very clear that you really, really, really need to switch doors in order to maximize the probability of winning a car.
Actually, the more games we play, the closer the probability of winning in our sample gets to the actual probability.
Even after 1000 games, the probabilities are still not at their actual values. But, ultimately…
If you stick to your door, you end up with the car in only 33% of the cases.
If you switch to the other door, you end up with the car 66% of the time!
Simulation Code
In both Python and R, I wrote two scripts. You can find the most recent version of the code on my Github. However, I pasted the versions of March 4th 2020 below.
The first script contains a function simulating a single game of Monty Hall. A second script runs this function an X amount of times, and visualizes the outcomes as we play more and more games.
Python
simulate_game.py
import random
def simulate_game(make_switch=False, n_doors=3, seed=None):
'''
Simulate a game of Monty Hall
For detailed information: https://en.wikipedia.org/wiki/Monty_Hall_problem
Basically, there are several closed doors and behind only one of them is a prize.
The player can choose one door at the start.
Next, the game master (Monty Hall) opens all the other doors, but one.
Now, the player can stick to his/her initial choice or switch to the remaining closed door.
If the prize is behind the player's final choice he/she wins.
Keyword arguments:
make_switch -- a boolean value whether the player switches after its initial choice and Monty Hall opening all other non-prize doors but one (default False)
n_doors -- an integer value > 2, for the number of doors behind which one prize and (n-1) non-prizes (e.g., goats) are hidden (default 3)
seed -- a seed to set (default None)
'''
# check the arguments
if type(make_switch) is not bool:
raise TypeError("`make_switch` must be boolean")
if type(n_doors) is float:
n_doors = int(n_doors)
raise Warning("float value provided for `n_doors`: forced to integer value of", n_doors)
if type(n_doors) is not int:
raise TypeError("`n_doors` needs to be a positive integer > 2")
if n_doors < 2:
raise ValueError("`n_doors` needs to be a positive integer > 2")
# if a seed was provided, set it
if seed is not None:
random.seed(seed)
# sample one index for the door to hide the car behind
prize_index = random.randint(0, n_doors - 1)
# sample one index for the door initially chosen by the player
choice_index = random.randint(0, n_doors - 1)
# we can test for the current result
current_result = prize_index == choice_index
# now Monty Hall opens all doors the player did not choose, except for one door
# next, he asks the player if he/she wants to make a switch
if (make_switch):
# if we do, we change to the one remaining door, which inverts our current choice
# if we had already picked the prize door, the one remaining closed door has a nonprize
# if we had not already picked the prize door, the one remaining closed door has the prize
return not current_result
else:
# the player sticks with his/her original door,
# which may or may not be the prize door
return current_result
visualize_game_results.py
from simulate_game import simulate_game
from random import seed
from numpy import mean, cumsum
from matplotlib import pyplot as plt
import os
# set the seed here
# do not set the `seed` parameter in `simulate_game()`,
# as this will make the function retun `n_games` times the same results
seed(1)
# pick number of games you want to simulate
n_games = 1000
# simulate the games and store the boolean results
results_with_switching = [simulate_game(make_switch=True) for _ in range(n_games)]
results_without_switching = [simulate_game(make_switch=False) for _ in range(n_games)]
# make a equal-length list showing, for each element in the results, the game to which it belongs
games = [i + 1 for i in range(n_games)]
# generate a title based on the results of the simulations
title = f'Switching doors wins you {sum(results_with_switching)} of {n_games} games ({mean(results_with_switching) * 100:.1f}%)' + \
'\n' + \
f'as opposed to only {sum(results_without_switching)} games ({mean(results_without_switching) * 100:.1f}%) when not switching'
# set some basic plotting parameters
w = 8
h = 5
# make a line plot of the cumulative wins with and without switching
plt.figure(figsize=(w, h))
plt.plot(games, cumsum(results_with_switching), color='blue', label='switching')
plt.plot(games, cumsum(results_without_switching), color='red', label='no switching')
plt.axis([0, n_games, 0, n_games])
plt.title(title)
plt.legend()
plt.xlabel('Number of games played')
plt.ylabel('Cumulative number of games won')
plt.figtext(0.95, 0.03, 'paulvanderlaken.com', wrap=True, horizontalalignment='right', fontsize=6)
# you can uncomment this to see the results directly,
# but then python will not save the result to your directory
# plt.show()
# plt.close()
# create a directory to store the plots in
# if this directory does not yet exist
try:
os.makedirs('output')
except OSError:
None
plt.savefig('output/monty-hall_' + str(n_games) + '_python.png')
Visualizations (matplotlib)
R
simulate-game.R
Note that I wrote a second function, simulate_n_games, which just runs simulate_game an N number of times.
#' Simulate a game of Monty Hall
#' For detailed information: https://en.wikipedia.org/wiki/Monty_Hall_problem
#' Basically, there are several closed doors and behind only one of them is a prize.
#' The player can choose one door at the start.
#' Next, the game master (Monty Hall) opens all the other doors, but one.
#' Now, the player can stick to his/her initial choice or switch to the remaining closed door.
#' If the prize is behind the player's final choice he/she wins.
#'
#' @param make_switch A boolean value whether the player switches after its initial choice and Monty Hall opening all other non-prize doors but one. Defaults to `FALSE`
#' @param n_doors An integer value > 2, for the number of doors behind which one prize and (n-1) non-prizes (e.g., goats) are hidden. Defaults to `3L`
#' @param seed A seed to set. Defaults to `NULL`
#'
#' @return A boolean value indicating whether the player won the prize
#'
#' @examples
#' simulate_game()
#' simulate_game(make_switch = TRUE)
#' simulate_game(make_switch = TRUE, n_doors = 5L, seed = 1)
simulate_game = function(make_switch = FALSE, n_doors = 3L, seed = NULL) {
# check the arguments
if (!is.logical(make_switch) | is.na(make_switch)) stop("`make_switch` needs to be TRUE or FALSE")
if (is.double(n_doors)) {
n_doors = as.integer(n_doors)
warning(paste("double value provided for `n_doors`: forced to integer value of", n_doors))
}
if (!is.integer(n_doors) | n_doors < 2) stop("`n_doors` needs to be a positive integer > 2")
# if a seed was provided, set it
if (!is.null(seed)) set.seed(seed)
# create a integer vector for the door indices
doors = seq_len(n_doors)
# create a boolean vector showing which doors are opened
# all doors are closed at the start of the game
isClosed = rep(TRUE, length = n_doors)
# sample one index for the door to hide the car behind
prize_index = sample(doors, size = 1)
# sample one index for the door initially chosen by the player
# this can be the same door as the prize door
choice_index = sample(doors, size = 1)
# now Monty Hall opens all doors the player did not choose
# except for one door
# if we have already picked the prize door, the one remaining closed door has a nonprize
# if we have not picked the prize door, the one remaining closed door has the prize
if (prize_index == choice_index) {
# if we have the prize, Monty Hall can open all but two doors:
# ours, which we remove from the options to sample from and open
# and one goat-conceiling door, which we do not open
isClosed[sample(doors[-prize_index], size = n_doors - 2)] = FALSE
} else {
# else, Monty Hall can also open all but two doors:
# ours
# and the prize-conceiling door
isClosed[-c(prize_index, choice_index)] = FALSE
}
# now Monty Hall asks us whether we want to make a switch
if (make_switch) {
# if we decide to make a switch, we can pick the closed door that is not our door
choice_index = doors[isClosed][doors[isClosed] != choice_index]
}
# we return a boolean value showing whether the player choice is the prize door
return(choice_index == prize_index)
}
#' Simulate N games of Monty Hall
#' Calls the `simulate_game()` function `n` times and returns a boolean vector representing the games won
#'
#' @param n An integer value for the number of times to call the `simulate_game()` function
#' @param seed A seed to set in the outer loop. Defaults to `NULL`
#' @param ... Any parameters to be passed to the `simulate_game()` function.
#' No seed can be passed to the simulate_game function as that would result in `n` times the same result
#'
#' @return A boolean vector indicating for each of the games whether the player won the prize
#'
#' @examples
#' simulate_n_games(n = 100)
#' simulate_n_games(n = 500, make_switch = TRUE)
#' simulate_n_games(n = 1000, seed = 123, make_switch = TRUE, n_doors = 5L)
simulate_n_games = function(n, seed = NULL, make_switch = FALSE, ...) {
# round the number of iterations to an integer value
if (is.double(n)) {
n = as.integer(n)
}
if (!is.integer(n) | n < 1) stop("`n_games` needs to be a positive integer > 1")
# if a seed was provided, set it
if (!is.null(seed)) set.seed(seed)
return(vapply(rep(make_switch, n), simulate_game, logical(1), ...))
}
visualize-game-results.R
Note that we source in the simulate-game.R file to get access to the simulate_game and simulate_n_games functions.
Also note that I make a second plot here, to show the probabilities of winning converging to their real-world probability as we play more and more games.
source('R/simulate-game.R')
# install.packages('ggplot2')
library(ggplot2)
# set the seed here
# do not set the `seed` parameter in `simulate_game()`,
# as this will make the function return `n_games` times the same results
seed = 1
# pick number of games you want to simulate
n_games = 1000
# simulate the games and store the boolean results
results_without_switching = simulate_n_games(n = n_games, seed = seed, make_switch = FALSE)
results_with_switching = simulate_n_games(n = n_games, seed = seed, make_switch = TRUE)
# store the cumulative wins in a dataframe
results = data.frame(
game = seq_len(n_games),
cumulative_wins_without_switching = cumsum(results_without_switching),
cumulative_wins_with_switching = cumsum(results_with_switching)
)
# function that turns values into nice percentages
format_percentage = function(values, digits = 1) {
return(paste0(formatC(values * 100, digits = digits, format = 'f'), '%'))
}
# generate a title based on the results of the simulations
title = paste(
paste0('Switching doors wins you ', sum(results_with_switching), ' of ', n_games, ' games (', format_percentage(mean(results_with_switching)), ')'),
paste0('as opposed to only ', sum(results_without_switching), ' games (', format_percentage(mean(results_without_switching)), ') when not switching)'),
sep = '\n'
)
# set some basic plotting parameters
linesize = 1 # size of the plotted lines
x_breaks = y_breaks = seq(from = 0, to = n_games, length.out = 10 + 1) # breaks of the axes
y_limits = c(0, n_games) # limits of the y axis - makes y limits match x limits
w = 8 # width for saving plot
h = 5 # height for saving plot
palette = setNames(c('blue', 'red'), nm = c('switching', 'without switching')) # make a named color scheme
# make a line plot of the cumulative wins with and without switching
ggplot(data = results) +
geom_line(aes(x = game, y = cumulative_wins_with_switching, col = names(palette[1])), size = linesize) +
geom_line(aes(x = game, y = cumulative_wins_without_switching, col = names(palette[2])), size = linesize) +
scale_x_continuous(breaks = x_breaks) +
scale_y_continuous(breaks = y_breaks, limits = y_limits) +
scale_color_manual(values = palette) +
theme_minimal() +
theme(legend.position = c(1, 1), legend.justification = c(1, 1), legend.background = element_rect(fill = 'white', color = 'transparent')) +
labs(x = 'Number of games played') +
labs(y = 'Cumulative number of games won') +
labs(col = NULL) +
labs(caption = 'paulvanderlaken.com') +
labs(title = title)
# save the plot in the output folder
# create the output folder if it does not exist yet
if (!file.exists('output')) dir.create('output', showWarnings = FALSE)
ggsave(paste0('output/monty-hall_', n_games, '_r.png'), width = w, height = h)
# make a line plot of the rolling % win chance with and without switching
ggplot(data = results) +
geom_line(aes(x = game, y = cumulative_wins_with_switching / game, col = names(palette[1])), size = linesize) +
geom_line(aes(x = game, y = cumulative_wins_without_switching / game, col = names(palette[2])), size = linesize) +
scale_x_continuous(breaks = x_breaks) +
scale_y_continuous(labels = function(x) format_percentage(x, digits = 0)) +
scale_color_manual(values = palette) +
theme_minimal() +
theme(legend.position = c(1, 1), legend.justification = c(1, 1), legend.background = element_rect(fill = 'white', color = 'transparent')) +
labs(x = 'Number of games played') +
labs(y = '% of games won') +
labs(col = NULL) +
labs(caption = 'paulvanderlaken.com') +
labs(title = title)
# save the plot in the output folder
# create the output folder if it does not exist yet
if (!file.exists('output')) dir.create('output', showWarnings = FALSE)
ggsave(paste0('output/monty-hall_perc_', n_games, '_r.png'), width = w, height = h)
Visualizations (ggplot2)
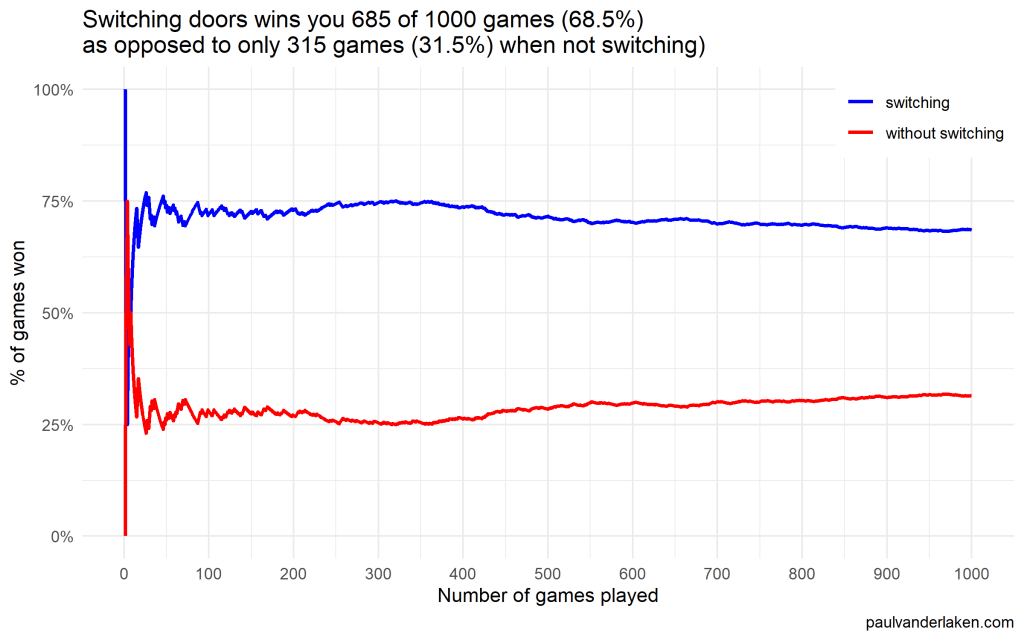
I specifically picked a seed (the second one I tried) in which not switching looked like it was better during the first few games played.
In R, I made an additional plot that shows the probabilities converging.
As we play more and more games, our results move to the actual probabilities of winning:
After the first four games, you could have erroneously concluded that not switching would result in better chances of you winning a sports car. However, in the long run, that is definitely not true.
I was actually suprised to see that these lines look to be mirroring each other. But actually, that’s quite logical maybe… We already had the car with our initial door guess in those games. If we would have sticked to that initial choice of a door, we would have won, whereas all the cases where we switched, we lost.
Keep me posted!
I hope you enjoyed these simulations and visualizations, and am curious to see what you come up with yourself!
For instance, you could increase the number of doors in the game, or the number of goat-doors Monty Hall opens. When does it become a disadvantage to switch?
Grant McDermott developed this new R package I wish I had thought of: parttree
parttree includes a set of simple functions for visualizing decision tree partitions in R with ggplot2. The package is not yet on CRAN, but can be installed from GitHub using:
Using the familiar ggplot2 syntax, we can simply add decision tree boundaries to a plot of our data.
In this example from his Github page, Grant trains a decision tree on the famous Titanic data using the parsnip package. And then visualizes the resulting partition / decision boundaries using the simple function geom_parttree()
library(parsnip)
library(titanic) ## Just for a different data set
set.seed(123) ## For consistent jitter
titanic_train$Survived = as.factor(titanic_train$Survived)
## Build our tree using parsnip (but with rpart as the model engine)
ti_tree =
decision_tree() %>%
set_engine("rpart") %>%
set_mode("classification") %>%
fit(Survived ~ Pclass + Age, data = titanic_train)
## Plot the data and model partitions
titanic_train %>%
ggplot(aes(x=Pclass, y=Age)) +
geom_jitter(aes(col=Survived), alpha=0.7) +
geom_parttree(data = ti_tree, aes(fill=Survived), alpha = 0.1) +
theme_minimal()
Super awesome!
This visualization precisely shows where the trained decision tree thinks it should predict that the passengers of the Titanic would have survived (blue regions) or not (red), based on their age and passenger class (Pclass).
This will be super helpful if you need to explain to yourself, your team, or your stakeholders how you model works. Currently, only rpart decision trees are supported, but I am very much hoping that Grant continues building this functionality!
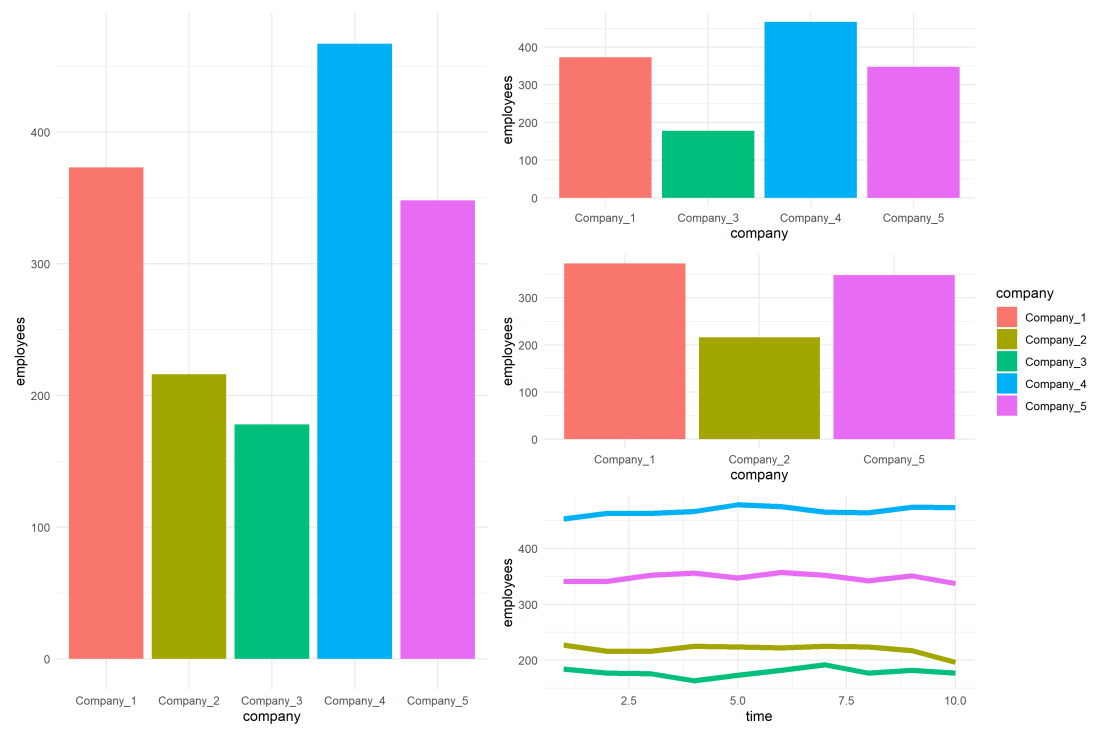
For instance, if you’re making multiple plots of the dataset — say a group of 5 companies — you want to have each company have the same, consistent coloring across all these plots.
R has some great data visualization capabilities. Particularly the ggplot2 package makes it so easy to spin up a good-looking visualization quickly.
The default in R is to look at the number of groups in your data, and pick “evenly spaced” colors across a hue color wheel. This looks great straight out of the box:
# install.packages('ggplot2')
library(ggplot2)
theme_set(new = theme_minimal()) # sets a default theme
set.seed(1) # ensure reproducibility
# generate some data
n_companies = 5
df1 = data.frame(
company = paste('Company', seq_len(n_companies), sep = '_'),
employees = sample(50:500, n_companies),
stringsAsFactors = FALSE
)
# make a simple column/bar plot
ggplot(data = df1) +
geom_col(aes(x = company, y = employees, fill = company))
However, it can be challenging is to make coloring consistent across plots.
For instance, suppose we want to visualize a subset of these data points.
index_subset1 = c(1, 3, 4, 5) # specify a subset
# make a plot using the subsetted dataframe
ggplot(data = df1[index_subset1, ]) +
geom_col(aes(x = company, y = employees, fill = company))
As you can see the color scheme has now changed. With one less group / company, R now picks 4 new colors evenly spaced around the color wheel. All but the first are different to the original colors we had for the companies.
One way to deal with this in R and ggplot2, is to add a scale_* layer to the plot.
Here we manually set Hex color values in the scale_fill_manual function. These hex values I provided I know to be the default R values for four groups.
# install.packages('scales')
# the hue_pal function from the scales package looks up a number of evenly spaced colors
# which we can save as a vector of character hex values
default_palette = scales::hue_pal()(5)
# these colors we can then use in a scale_* function to manually override the color schema
ggplot(data = df1[index_subset1, ]) +
geom_col(aes(x = company, y = employees, fill = company)) +
scale_fill_manual(values = default_palette[-2]) # we remove the element that belonged to company 2
As you can see, the colors are now aligned with the previous schema. Only Company 2 is dropped, but all other companies retained their color.
However, this was very much hard-coded into our program. We had to specify which company to drop using the default_palette[-2].
If the subset changes, which often happens in real life, our solution will break as the values in the palette no longer align with the groups R encounters:
index_subset2 = c(1, 2, 5) # but the subset might change
# and all manually-set colors will immediately misalign
ggplot(data = df1[index_subset2, ]) +
geom_col(aes(x = company, y = employees, fill = company)) +
scale_fill_manual(values = default_palette[-2])
Fortunately, R is a smart language, and you can work your way around this!
All we need to do is created, what I call, a named-color palette!
It’s as simple as specifying a vector of hex color values! Alternatively, you can use the grDevices::rainbow or grDevices::colors() functions, or one of the many functions included in the scales package
# you can hard-code a palette using color strings
c('red', 'blue', 'green')
# or you can use the rainbow or colors functions of the grDevices package
rainbow(n_companies)
colors()[seq_len(n_companies)]
# or you can use the scales::hue_pal() function
palette1 = scales::hue_pal()(n_companies)
print(palette1)
Now we need to assign names to this vector of hex color values. And these names have to correspond to the labels of the groups that we want to colorize.
With this named color vector and the scale_*_manual functions we can now manually override the fill and color schemes in a flexible way. This results in the same plot we had without using the scale_*_manual function:
ggplot(data = df1) +
geom_col(aes(x = company, y = employees, fill = company)) +
scale_fill_manual(values = palette1_named)
However, now it does not matter if the dataframe is subsetted, as we specifically tell R which colors to use for which group labels by means of the named color palette:
# the colors remain the same if some groups are not found
ggplot(data = df1[index_subset1, ]) +
geom_col(aes(x = company, y = employees, fill = company)) +
scale_fill_manual(values = palette1_named)
# and also if other groups are not found
ggplot(data = df1[index_subset2, ]) +
geom_col(aes(x = company, y = employees, fill = company)) +
scale_fill_manual(values = palette1_named)
Once you are aware of these superpowers, you can do so much more with them!
How about highlighting a specific group?
Just set all the other colors to ‘grey’…
# lets create an all grey color palette vector
palette2 = rep('grey', times = n_companies)
palette2_named = setNames(object = palette2, nm = df1$company)
print(palette2_named)
# this looks terrible in a plot
ggplot(data = df1) +
geom_col(aes(x = company, y = employees, fill = company)) +
scale_fill_manual(values = palette2_named)
… and assign one of the company’s colors to be a different color
# override one of the 'grey' elements using an index by name
palette2_named['Company_2'] = 'red'
print(palette2_named)
# and our plot is professionally highlighting a certain group
ggplot(data = df1) +
geom_col(aes(x = company, y = employees, fill = company)) +
scale_fill_manual(values = palette2_named)
We can apply these principles to other types of data and plots.
For instance, let’s generate some time series data…
timepoints = 10
df2 = data.frame(
company = rep(df1$company, each = timepoints),
employees = rep(df1$employees, each = timepoints) + round(rnorm(n = nrow(df1) * timepoints, mean = 0, sd = 10)),
time = rep(seq_len(timepoints), times = n_companies),
stringsAsFactors = FALSE
)
… and visualize these using a line plot, adding the color palette in the same way as before:
ggplot(data = df2) +
geom_line(aes(x = time, y = employees, col = company), size = 2) +
scale_color_manual(values = palette1_named)
If we miss one of the companies — let’s skip Company 2 — the palette makes sure the others remained colored as specified:
ggplot(data = df2[df2$company %in% df1$company[index_subset1], ]) +
geom_line(aes(x = time, y = employees, col = company), size = 2) +
scale_color_manual(values = palette1_named)
Also the highlighted color palete we used before will still work like a charm!
ggplot(data = df2) +
geom_line(aes(x = time, y = employees, col = company), size = 2) +
scale_color_manual(values = palette2_named)
Now, let’s scale up the problem! Pretend we have not 5, but 20 companies.
The code will work all the same!
set.seed(1) # ensure reproducibility
# generate new data for more companies
n_companies = 20
df1 = data.frame(
company = paste('Company', seq_len(n_companies), sep = '_'),
employees = sample(50:500, n_companies),
stringsAsFactors = FALSE
)
# lets create an all grey color palette vector
palette2 = rep('grey', times = n_companies)
palette2_named = setNames(object = palette2, nm = df1$company)
# highlight one company in a different color
palette2_named['Company_2'] = 'red'
print(palette2_named)
# make a bar plot
ggplot(data = df1) +
geom_col(aes(x = company, y = employees, fill = company)) +
scale_fill_manual(values = palette2_named) +
theme(axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1)) # rotate and align the x labels
Also for the time series line plot:
timepoints = 10
df2 = data.frame(
company = rep(df1$company, each = timepoints),
employees = rep(df1$employees, each = timepoints) + round(rnorm(n = nrow(df1) * timepoints, mean = 0, sd = 10)),
time = rep(seq_len(timepoints), times = n_companies),
stringsAsFactors = FALSE
)
ggplot(data = df2) +
geom_line(aes(x = time, y = employees, col = company), size = 2) +
scale_color_manual(values = palette2_named)
The possibilities are endless; the power is now yours!
Just think at the efficiency gain if you would make a custom color palette, with for instance your company’s brand colors!
For more R tricks to up your programming productivity and effectiveness, visit the R tips and tricks page!
However, paletteer is by far my favorite package for customizing your colors in R!
The paletteer package offers direct access to 1759 color palettes, from 50 different packages!
After installing and loading the package, paletteer works as easy as just adding one additional line of code to your ggplot:
install.packages("paletteer") library(paletteer)
install.packages("ggplot2") library(ggplot2)
ggplot(iris, aes(Sepal.Length, Sepal.Width, color = Species)) + geom_point() + scale_color_paletteer_d("nord::aurora")
paletteer offers a combined collection of hundreds of other color palettes offered in the R programming environment, so you are sure you will find a palette that you like! Here’s the list copied below, but this github repo provides more detailed information about the package contents.