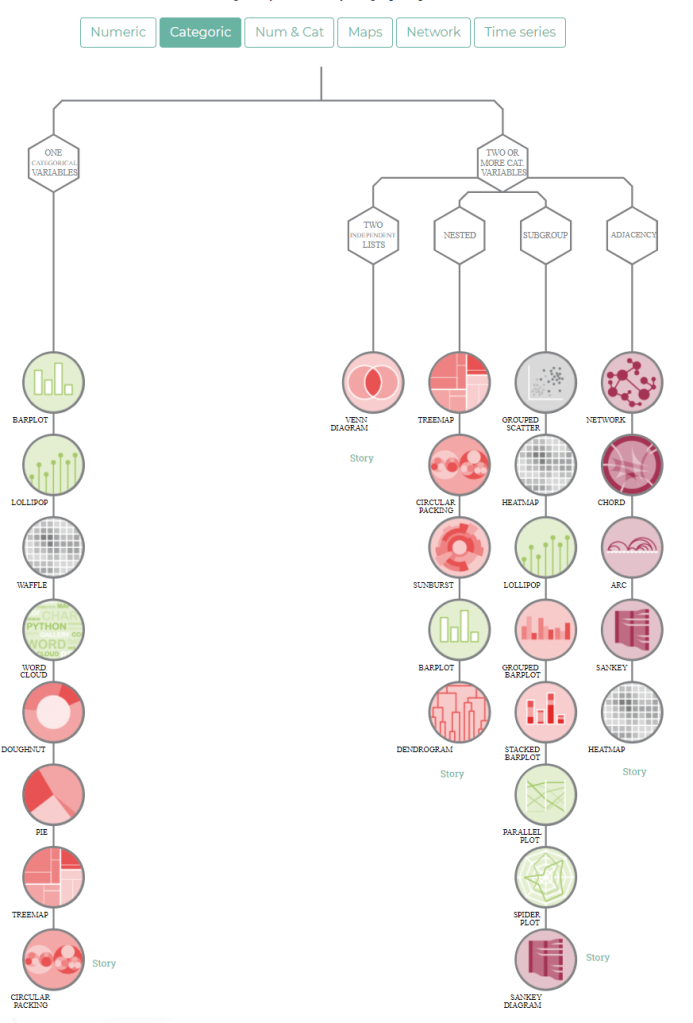
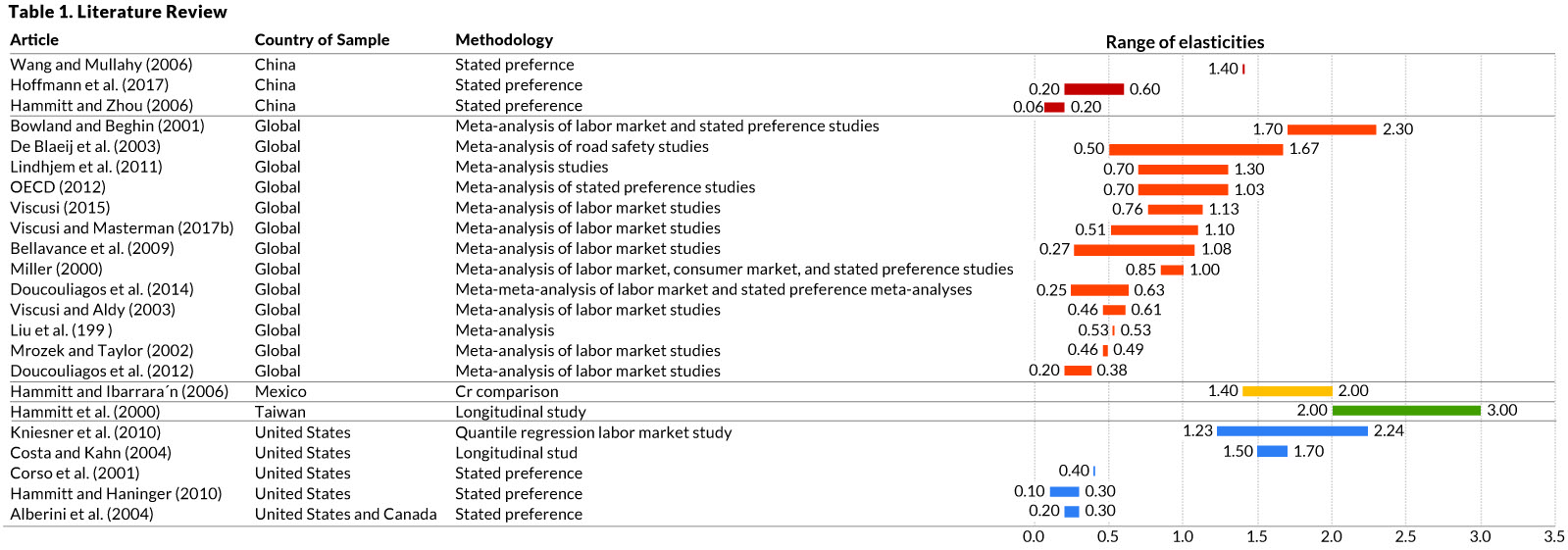
A flowchart is a picture of the separate steps of a process in sequential order. It it super useful to organize and interpret business processes, IT systems, or computer algorithms.
I draw flowcharts and process diagrams all the time in my daily work as a data scientist!
Drawing out the business process is often a first step in any project, in order to really understand the underlying business workflow and problems. I feel doing so greatly facilitates opportunity finding.
Moreover, when designing a machine learning or data science architecture — with data coming from different sources, being manipulated using different workflows, and ending up in models feeding multiple business processes — drawing the whole she-bang out really helps me personally to keep overview.
There are licensed software programs such as Microsoft Visio that allow you to create flowcharts. But there are also numerous free applications that can help you draw up a flow chart.

Draw.io or app.diagrams.net is my favorite free online application.
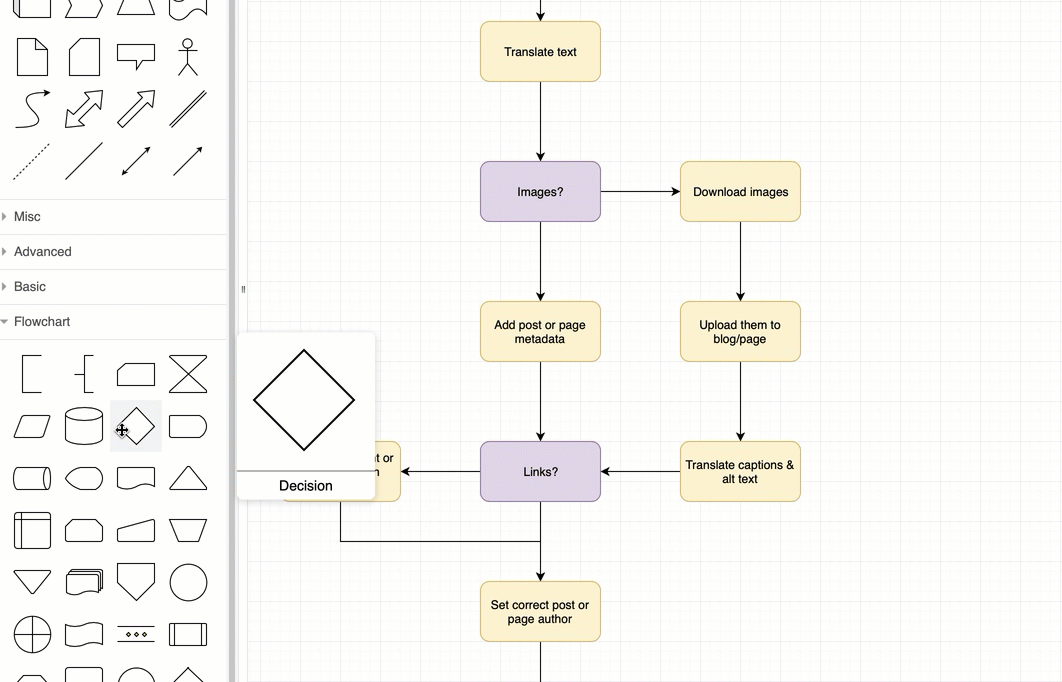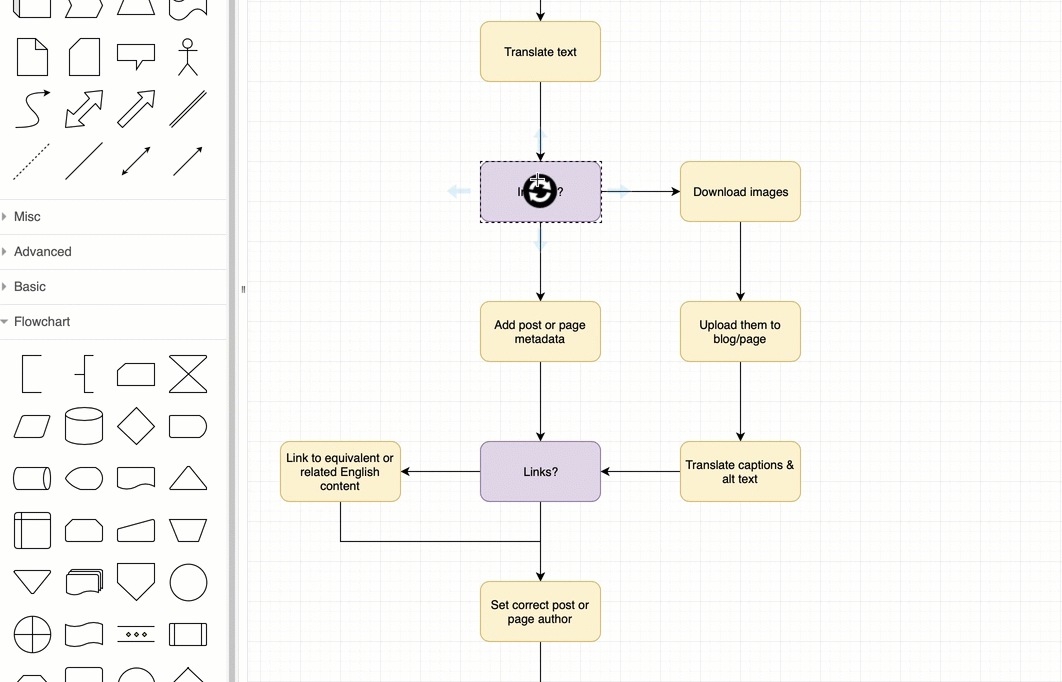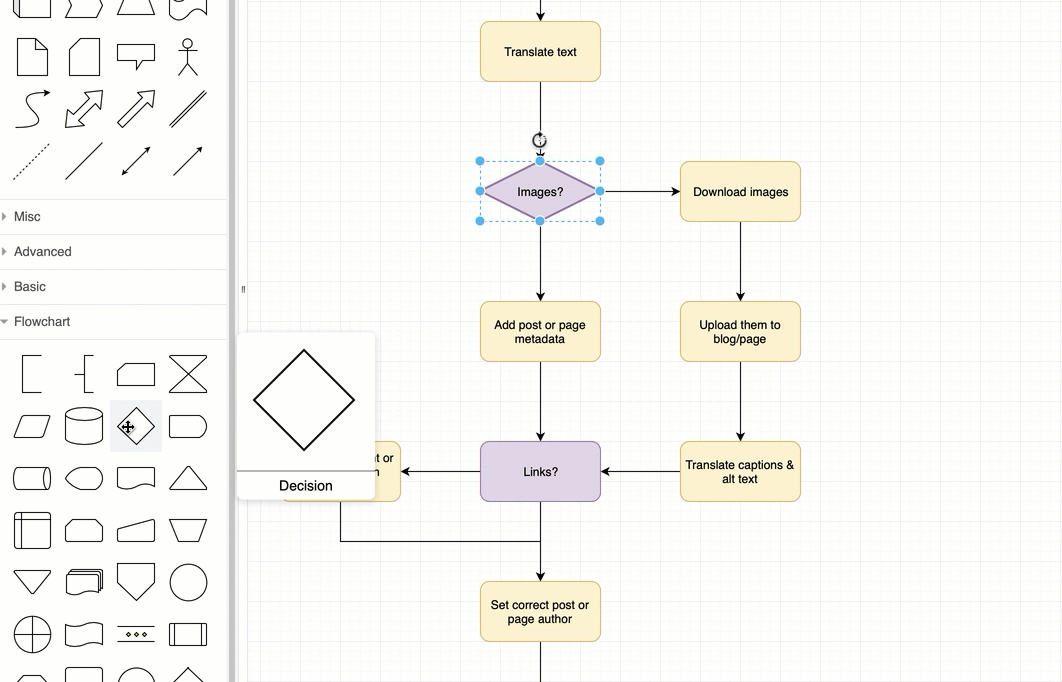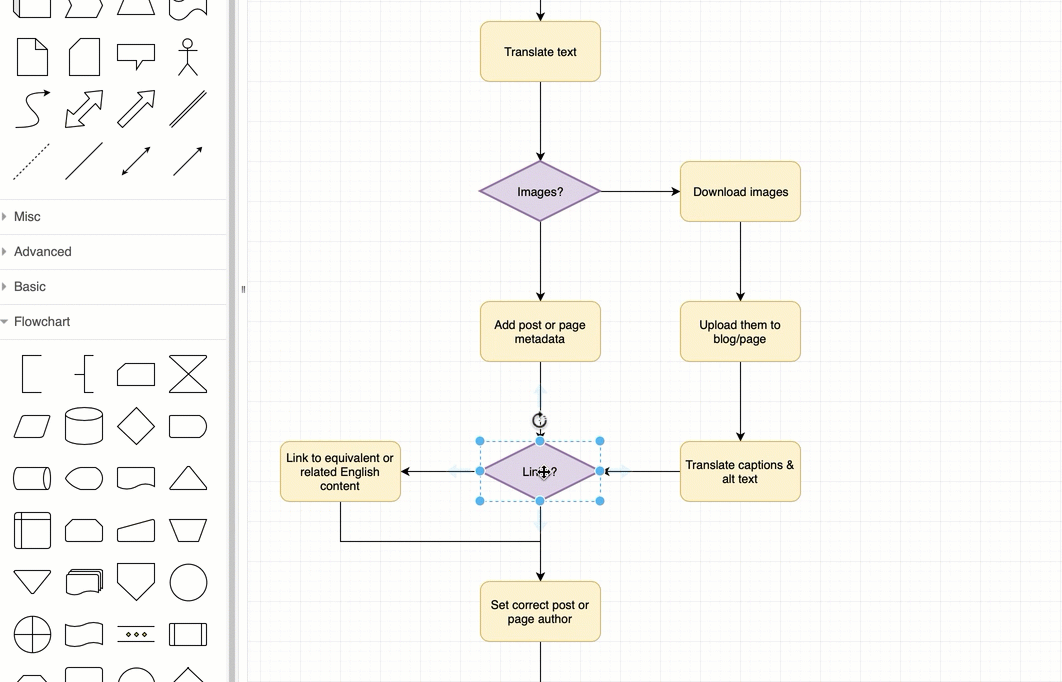
It allows the easy creation of beatiful flowcharts and process diagrams.
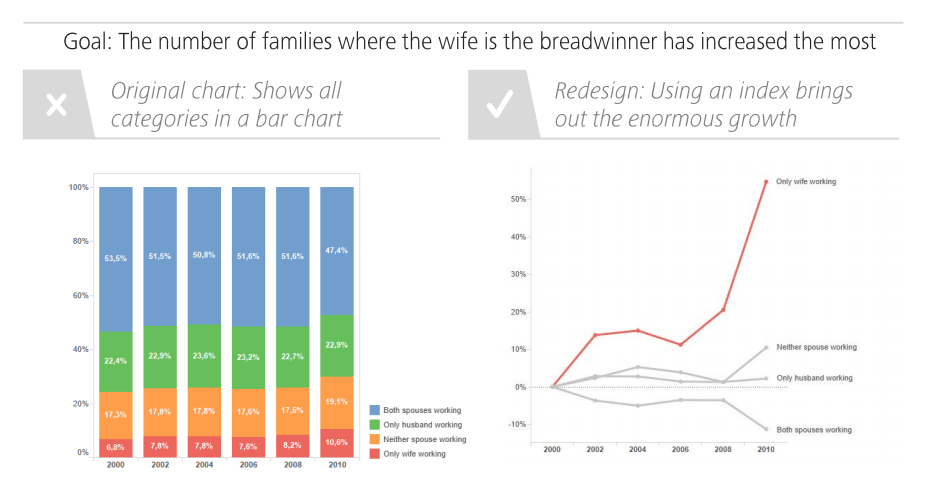
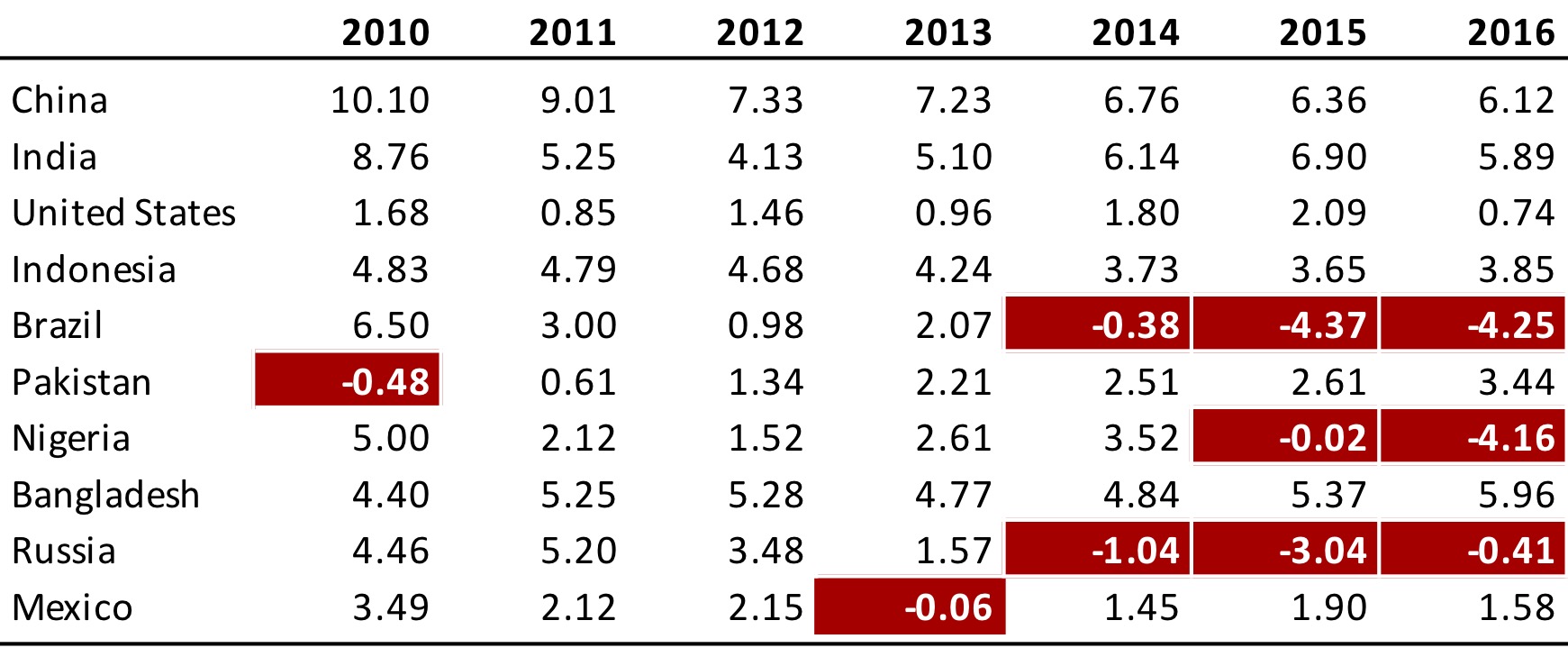
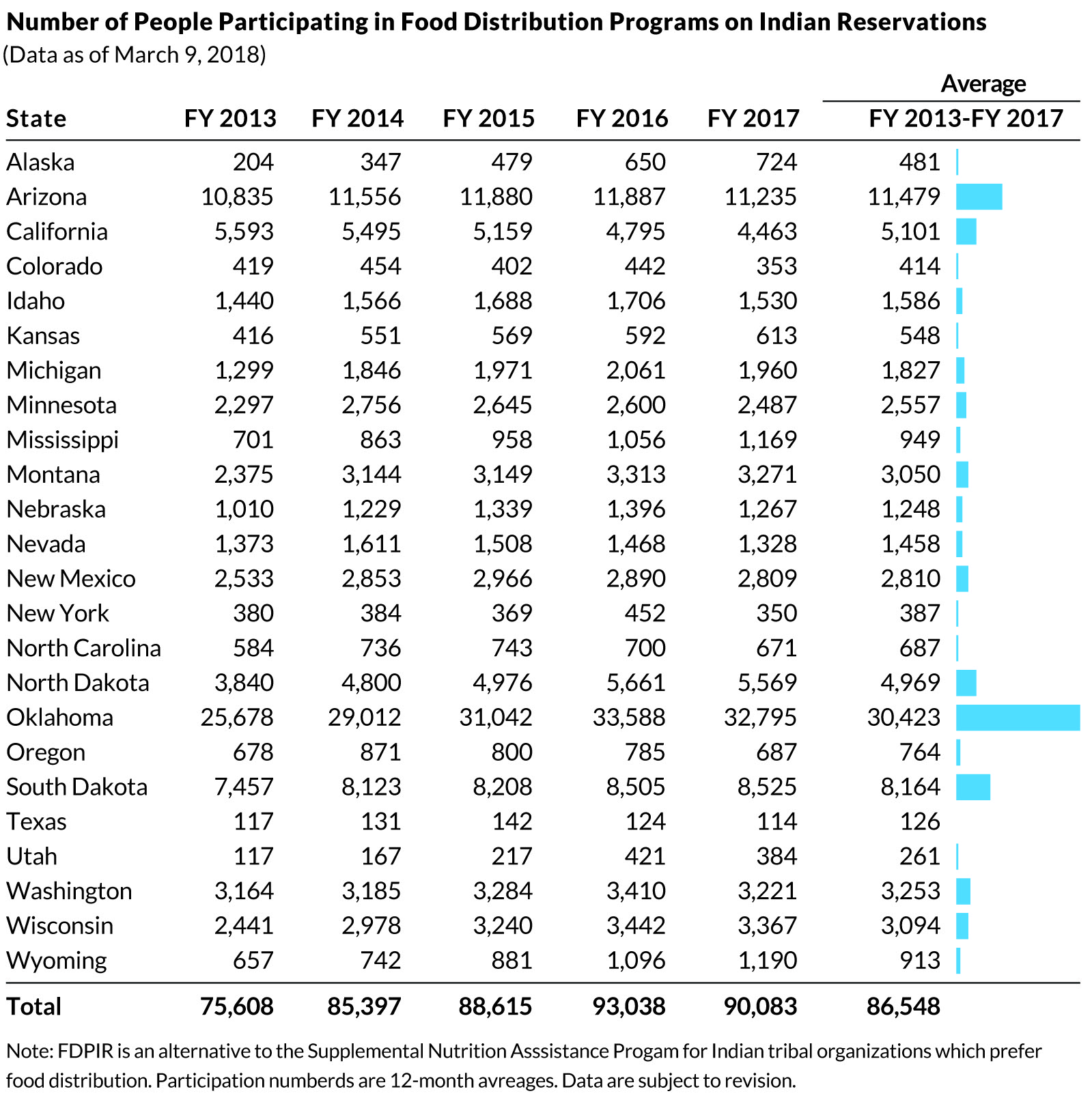
Here’s another great static example:

Moreover, Draw.io easily integrates with other suites, like google drive, one drive, et cetera.

Now, some fellow geek out there — Henning Dieterichs — actually built an unofficial draw.io plugin for Visual Studio Code.
I’ve recently transitioned to VS Code for all my Python programming, so I really welcome this cool feature. It integrates all the flow chart functionality of draw.io right there in your IDE. Incredible!
Here’s a demo:

Here’s another demo, but with a light theme, showing how easy it is to export your diagrams to a shareable png file.

Moreover, due to VS Code’s amazing “LiveShare” feature, you can even collaborate with colleagues and build a flow chart together, simulatenously:

Now there are many more features to this plugin. You can write and change the JavaScript code behind the objects to tailor it completely to your theme and tastes. Or if you prefer working with XML, you can just alter that code. Everything seems to work as a charm.
Have a look at the plugin yourself: https://github.com/hediet/vscode-drawio
Note:
I am in no way affiliated with Draw.io, Microsoft, Visual Studio Code, or the author of this plugin.
I just get enthusiastic : )