Great tutorial on how to conduct simple market basket analysis on your laptop either with association rules through the arules package or with frequent pattern mining (FPGrowth) in Spark via sparklyr!
Market Basket Analysis or association rules mining can be a very useful technique to gain insights in transactional data sets, and it can be useful for product recommendation. The classical example is data in a supermarket. For each customer we know what the individual products (items) are that he has bought. With association rules mining we can identify items that are frequently bought together. Other use cases for MBA could be web click data, log files, and even questionnaires.
In R there is a package arules to calculate association rules, it makes use of the so-called Apriori algorithm. For data sets that are not too big, calculating rules with arules in R (on a laptop) is not a problem. But when you have very huge data sets, you need to do something else, you can:
use more computing power (or cluster of computing nodes).
Adam Geitgey likes to write about computers and machine learning. He explains machine learning as “generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.” (Part 1)
Adam’s visual explanation of two machine learning applications (original from Part 1)
In the fourth part of his series on machine learning Adam touches on Facial Recognition. Facebook is one of the companies using such algorithms in real-time, allowing them to recognize your friends’ faces after you’ve tagged them only a few times. Facebook reports they recognize faces with 97% accuracy, which is comparable to our own, human facial recognition abilities!
Facebook’s algorithms recognizing and automatically tagging Adam’s family. Helpful or creepy? (original from Part 4)
Adam decided to put up a challenge: would a facial recognition algorithm be able to distinguish Will Ferrell (famous actor) from Chad Smith (famous rock musician)? Indeed, these two celebrities look very much alike:
If you want to train such an algorithm, Adam explain, you need to overcome a series of related problems:
First, look at a picture and find all the faces in it
Second, focus on each face and be able to understand that even if a face is turned in a weird direction or in bad lighting, it is still the same person.
Third, be able to pick out unique features of the face that you can use to tell it apart from other people— like how big the eyes are, how long the face is, etc.
Finally, compare the unique features of that face to all the people you already know to determine the person’s name.
How the facial recognition algorithm steps might work (original from Part 4)
To detect the faces, Adam used Histograms of Oriented Gradients (HOG). All input pictures were converted to black and white (because color is not needed) and then every single pixel in our image is examined, one at a time. Moreover, for every pixel, the algorithm examined the pixels directly surrounding it:
Illustration of the algorithm as it would take in a black and white photo of Will Ferrel (original from Part 4)
The algorithm then checks, for every pixel, in which direction the picture is getting darker and draws an arrow (a gradient) in that direction.
Illustration of how algorithm would reduce a black and white photo of Will Ferrel to gradients (original from Part 4)
However, to do this for every single pixel would require too much processing power, so Adam broke up pictures in 16 by 16 pixel squares. The result is a very simple representation that does capture the basic structure of the original face, based on which we can now spot faces in pictures. Moreover, because we used gradients, the result will be similar regardless of the lighting of the picture.
The original image turned into a HOG representation (original from Part 4)
Now that the computer can spot faces, we need to make sure that it knows that two perspectives of the same face represent the same person. Adam uses landmarks for this: 68 specific points that exist on every face. An algorithm can then be trained to find these points on any face:
The 68 points on the image of Will Ferrell (original from Part 4)
Now the computer knows where the chin, the mouth and the eyes are, the image can be scaled and rotated to center it as best as possible:
The image of Will Ferrell transformed (original from Part 4)
Adam trained a Deep Convolutional Neural Network to generate 128 measurements for each face that best distinguish it from faces of other people. This network needs to train for several hours, going through thousands and thousands of face pictures. If you want to try this step yourself, Adam explains how to run OpenFace’s lua script. This study at Google provides more details, but it basically looks like this:
The training process visualized (original from Part 4)
After hours of training, the neural net will output 128 numbers accurately representing the specific face put in. Now, all you need to do is check which face in your database is most closely resembled by those 128 numbers, and you have your match! Many algorithms can do this final check, and Adam trained a simple linear SVM classifier on twenty pictures of Chad Smith, Will Ferrel, and Jimmy Falon (the host of a talkshow they both visited).
In the end, Adam’s machine had learned to distinguish these three people – two of whom are nearly indistinguishable with the human eye – in real-time:
Adam Geitgey’s facial recognition algorithm in action: providing real time classifications of the faces of lookalikes Chad Smith and Will Ferrel at Jimmy Falon’s talk show (original from Part 4)
A Generative Adversarial Network, GAN in short, is a machine learning architecture where two neural networks compete against each other. One of them functions as a discriminator, seeking to optimize its classification of data (i.e., determine whether or not there is a cat in a picture). The other one functions as a generator, seeking to best generate new data to fool the discriminator (i.e., create realistic fake images of cats). Over time, the generator network will become increasingly good at simulating realistic data and being able to mimic real-life.
The concept of GAN was introduced by Ian Goodfellow in 2014, whom we know from the Machine Learning & Deep Learning book. Although GANs are computationally heavy and still undergoing major development, their potential implications are widespread. We can see these architectures taking over all sort of creative work, where generating new “data” is the main task. Think for instance of designing clothes, creating video footage, writing novels, animating movies, or even whole video games. One of my favorite Youtube channels discusses multiple of its recent applications, and here are a few of my favorites:
If you want to try out these GANs yourself but do not have the programming experience: Reiichiro Nakano made a GAN playground in (what seems) JavaScript, where you can play around with the discriminator and the generator to create an adversarial network that identifies and generates images of numbers.
Sorting is one of the central topic in most Computer Science degrees. In general, sorting refers to the process of rearranging data according to a defined pattern with the end goal of transforming the original unsorted sequence into a sorted sequence. It lies at the heart of successful businesses ventures — such as Google and Amazon — but is also present in many applications we use daily — such as Excel or Facebook.
Many different algorithms have been developed to sort data. Wikipedia lists as many as 45 and there are probably many more. Some work by exchanging data points in a sequence, others insert and/or merge parts of the sequence. More importantly, some algorithms are quite effective in terms of the time they take to sort data — taking only time to sort datapoints — whereas others are very slow — taking as much as . Moreover, some algorithms are stable — in the sense that they always take the same amount of time to process datapoints — whereas others may fluctuate in terms of processing time based on the original order of the data.
I really enjoyed this video by TED-Ed on how to best sort your book collection. It provides a very intuitive introduction into sorting strategies (i.e., algorithms). Moreover, Algorithms to Live By (Christian & Griffiths, 2016) provided the amazing suggestion to get friends and pizza in whenever you need to sort something, next to the great explanation of various algorithms and their computational demand.
The main reason for this blog is that I stumbled across some nice video’s and GIFs of sorting algorithms in action. These visualizations are not only wonderfully intriguing to look at, but also help so much in understanding how the sorting algorithms process the data under the hood. You might want to start with the 4-minute YouTube video below, demonstrating how nine different sorting algorithms (Selection Sort, Shell Sort, Insertion Sort, Merge Sort, Quick Sort, Heap Sort, Bubble Sort, Comb Sort, & Cocktail Sort) process a variety of datasets.
This interactive website toptal.com allows you to play around with the most well-known sorting algorithms, putting them to work on different datasets. For the grande finale, I found these GIFs and short video’s of several sorting algorithms on imgur. In the visualizations below, each row of the image represents an independent list being sorted. You can see that Bubble Sort is quite slow:
Cocktail Shaker Sort already seems somewhat faster, but still takes quite a while.
For some algorithms, the visualization clearly shows that the settings you pick matter. For instance, Heap Sort is much quicker if you choose to shift down instead of up.
In contrast, for Merge Sort it doesn’t matter whether you sort by breadth first or depth first.
The imgur overview includes many more visualized sorting algorithms but I don’t want to overload WordPress or your computer, so I’ll leave you with two types of Radix Sort, the rest you can look up yourself!
A few weeks ago, Magic Sudoku was released for iOS11. This app by a company named Hatchlings automatically solves sudoku puzzles using a combination of Computer Vision, Machine Learning, and Augmented Reality. The app works on iPad Pro’s and iPhone 6s or above and can be downloaded from the App Store.
Magic Sudoku gives a magical experience when users point their phone at a Sudoku puzzle: the puzzle is instantaneously solved and displayed on their screen. In several seconds, the following occurs behind the scenes:
“One of the original reasons I chose a Sudoku solver as our first AR app was that I knew classifying digits is basically the “hello world” of Machine Learning. I wanted to dip my toe in the water of Machine Learning while working on a real-world problem. This seemed like a realistic app to tackle.” – Brad Dwyer, Founder at Hatchlings
Particularly the training process of the app interested me. In his blog, Brad explains how they bought out the entire stock of Sudoku books of a specific bookstore and, with the help of his team, ripped each book apart to scan each small square with a number and upload in to a server. In the end, this server contained about 600,000 images, but all were completely unlabeled. Via a simple game, they asked Hatchlings users to classify these images by pressing the number keys on their keyboard. Within 24 hours, all 600,000 images were classified!
Nevertheless, some users had misunderstood the task (or just plainly ignored it) and as a consequence there were still a significant number of misidentified images. So Brad created a second tool that displayed 100 images of a single class to users, who where consequently asked to click the ones that didn’t match. These were subsequently thrown back into the first tool to be reclassified.
Quickly, the developers had enough verified data to add an automatic accuracy checker into both tools for future data runs. Funnily enough, they programmed it in such a way that users were periodically shown already known/classified images in order to check the validity of their inputs and determine how much to trust their answers going forward. This whole process reminds me on a blog I wrote recently, regarding human-computer interactions in reinforcement learning.
For several more weeks, users classified more scanned data so that, by the time the app was launched, it had been trained on over a million images of Sudoku squares. The results were amazing as the application had a 98.6% accuracy on launch (currently above 99% accuracy). One minor deficit was that the app was trained on paper Sudoku’s. However, when it aired, many users wanted to quickly test it and searched for Sudoku images on Google, which the app wouldn’t process that well.
“Problem number one was that our machine learning model was only trained on paper puzzles; it didn’t know what to think about pixels on a screen. I pulled an all nighter that first week and re-trained our model with puzzles on computer screens.
Problem number two was that ARKit only supports horizontal planes like tables and floors (not vertical planes like computer monitors). Solving this was a trickier problem but I did come up with a hacky workaround. I used a combination of some heuristics and FeaturePoint detection to place puzzles on non-horizontal planes.” – Brad Dwyer, Founder at Hatchlings
A regular expression (regex or regexp for short) is a special text string for describing a search pattern. You can think of regular expressions as wildcards on steroids. You are probably familiar with wildcard notations such as *.txt to find all text files in a file manager. The regex equivalent is .*\.txt$.
Last week I posted a first tutorial on Regular Expressions in R and I am working its sequels. You may find additional resources on Regular Expressions in the learning overviews (R, Python, Data Science).
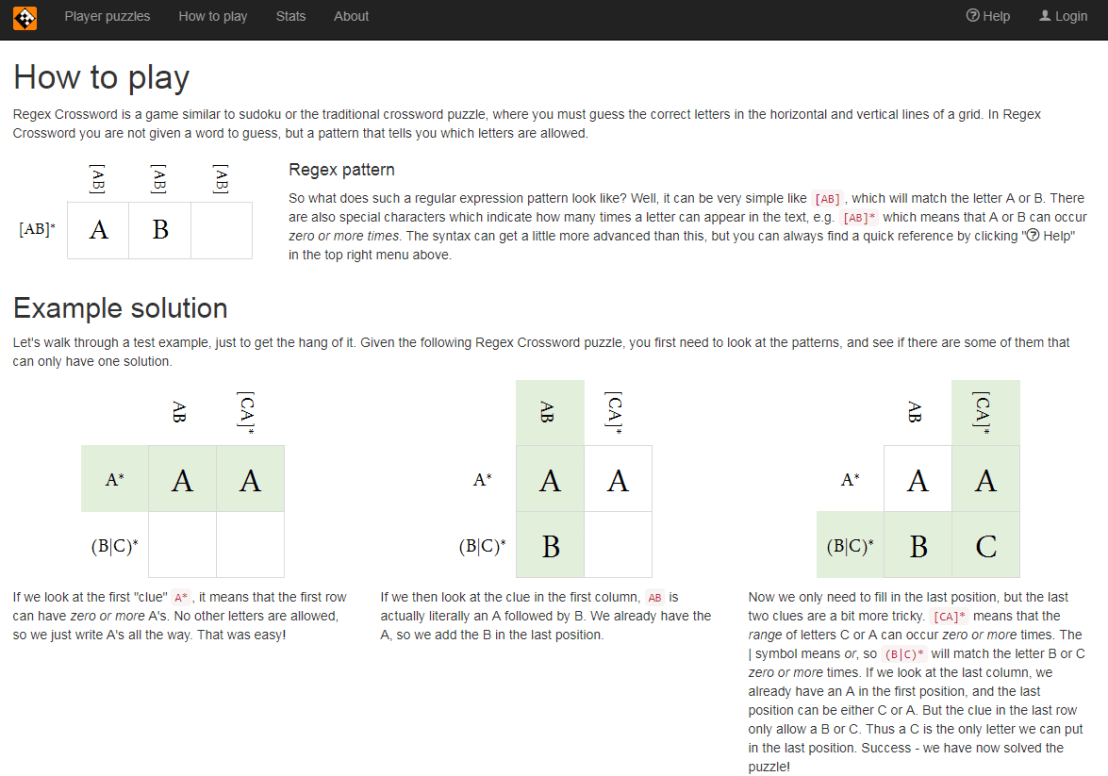
Today I came across this website of Regular Expression Crosswords, which proves a great resource to playfully master regular expression. All puzzles are validated live using the JavaScript regex engine. The figure below explains how it works
Via the links below you can jump puzzles that matches your expertise level:

















 time to sort
time to sort  . Moreover, some algorithms are stable — in the sense that they always take the same amount of time to process
. Moreover, some algorithms are stable — in the sense that they always take the same amount of time to process