Aleszu Bajak at Storybench.org published a great demonstration of the power of text mining. He used the R tidytext package to analyse 150,000 wine reviews which Zach Thoutt had scraped from Wine Enthusiast in November of 2017.
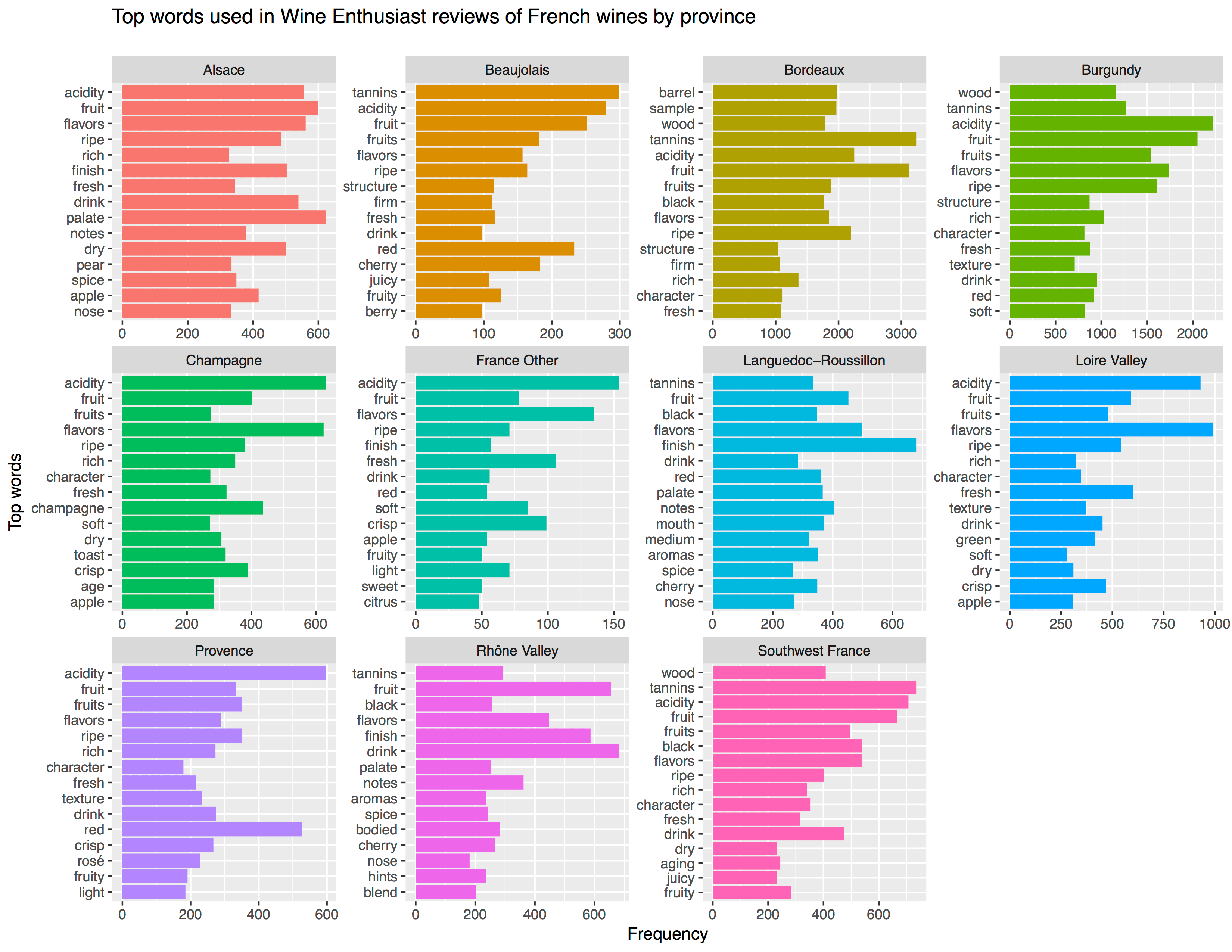
Aleszu started his analysis on only the French wines, with a simple word count per region:
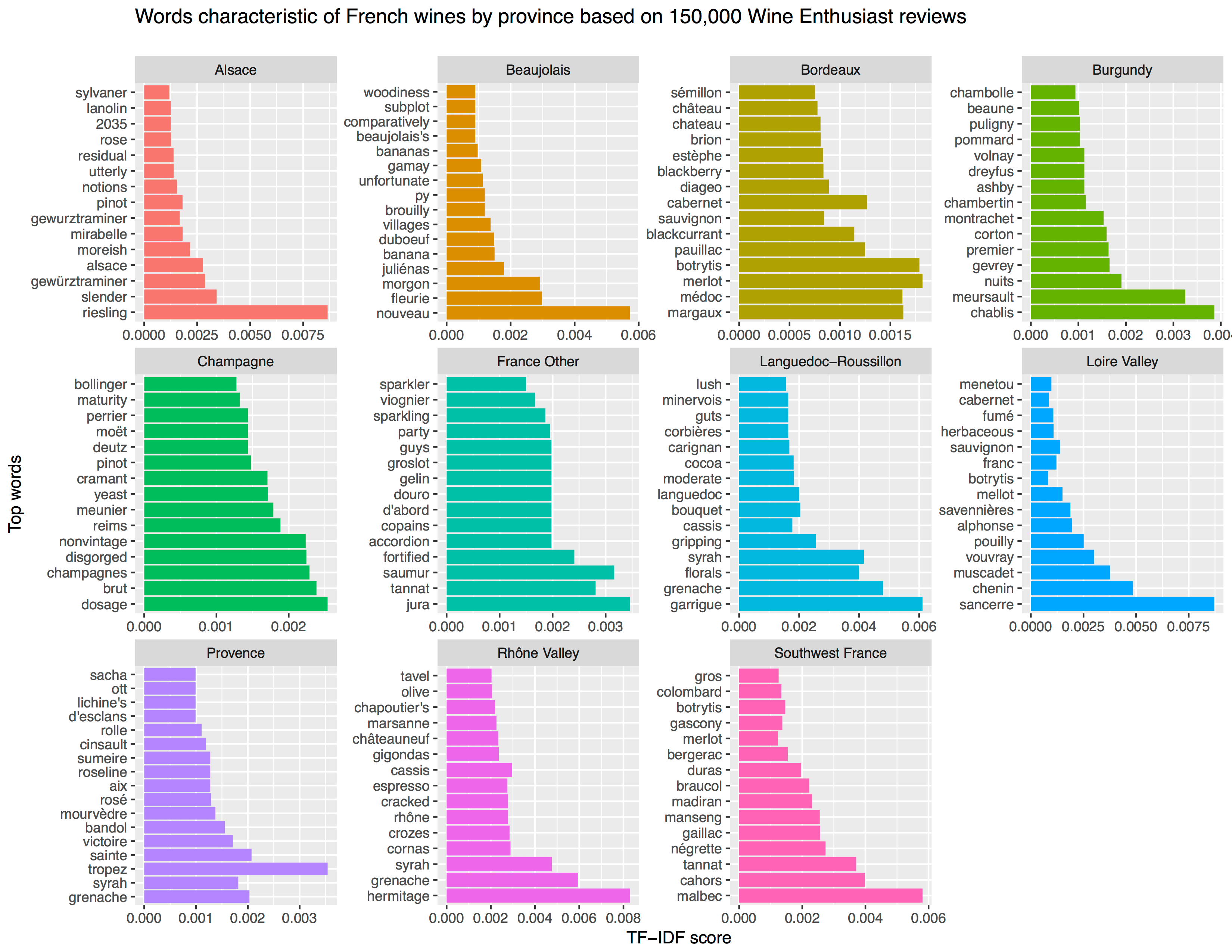
[orginal blog]Next, he applied TF-IDF to surface the words that are most characteristic for specific French wine regions — words used often in combination with that specific region, but not in relation to other regions.
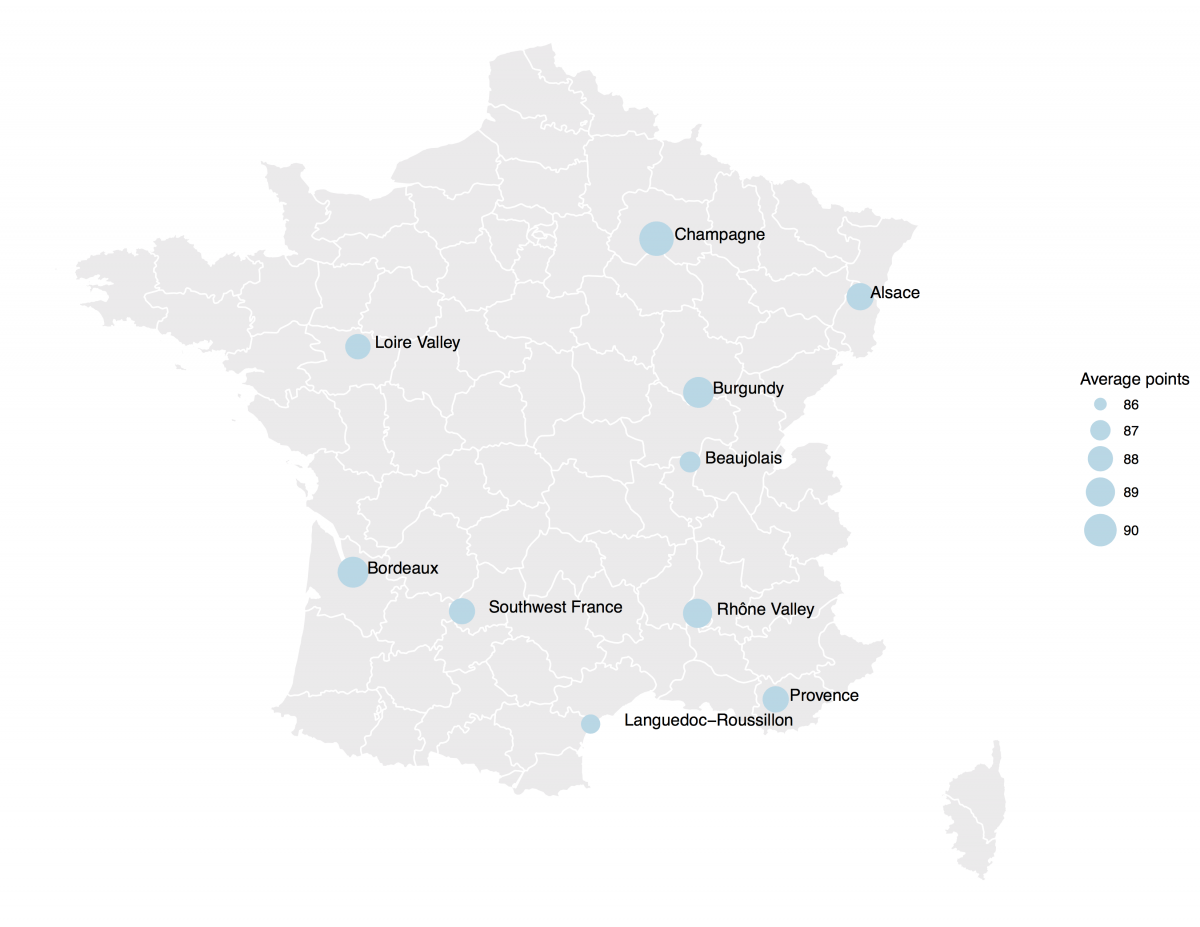
[orginal blog]The data also contained some price information, which Aleszu mapped France with ggplot2 and the maps package to demonstrate which French wine regions are generally more costly.
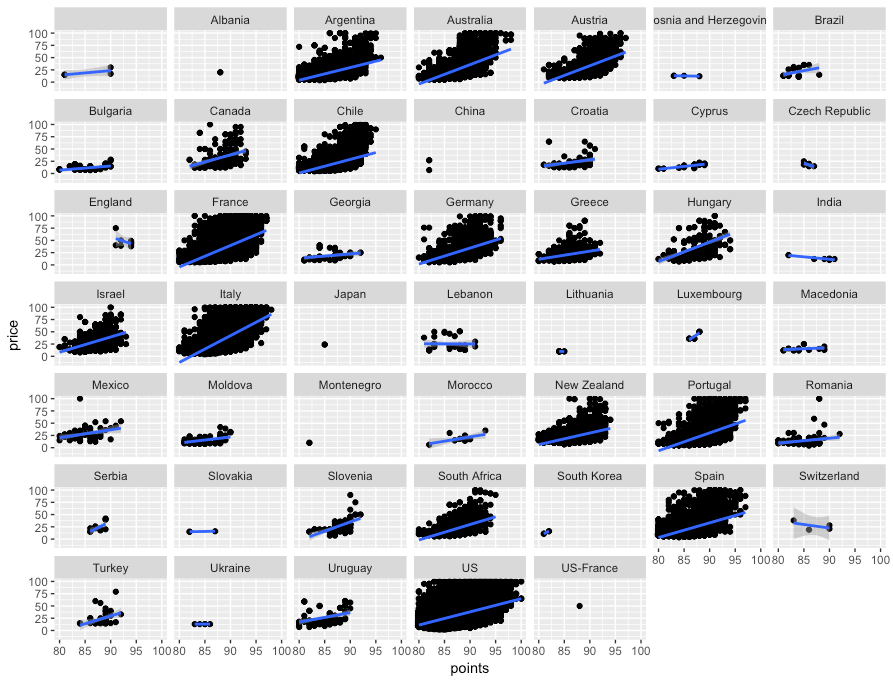
[orginal blog]On the full dataset, Alezsu also demonstrated that there is a strong relationship between price and points, meaning that, in general, more expensive wines seem to get better reviews:
Nothing beats a aesthetically-pleasing data visualization in the form of a map (see evidence here, here, here, or here).
Moreover, we’ve already witnessed some great R tutorials by Ilya Kashnitsky before (see Animated Snow in R).
These two come together in Ilya’s recent post on subplots in ggplot2 maps, with which he completely amazed me. The creation process is actually easier than the end result makes it look: make several visualizations and add them as ggplot2::annotation_custom() to your main ggplot2 map — the same as if you are adding a logo to your plot. Enjoy:
Disclaimer: This page contains one or more links to Amazon. Any purchases made through those links provide us with a small commission that helps to host this blog.
Useful base functions
str() – explore structure of R object
trimws() – trim trailing and/or leading whitespaces
dput() – dump an R object in form of R code
cut()– categorize values into intervals
intersect() – returns similar elements in two vectors
union() – find intersecting items in two vectors
setdiff() – returns different elements in two vectors
interaction() – computes a factor which represents the interaction of the given factors
formatC()can be used to round numbers and force trailing zero’s
formatC() and sprintf() can be used to add leading/trailing characters
expand.grid() – create a data frame from all combinations of the supplied vectors or factors
seq_along(myvec) – generates a vector of 1:length(myvec)
Generate distributions in ggplot2 using the stat_function function. Normal distributions, student t-distributions, beta distributions, anything. See also here.
The 2018 annual Society for Industrial and Organizational Psychology (SIOP) conference featured its first-ever machine learning competition. Teams competed for several months in predicting the enployee turnover (or churn) in a large US company. A more complete introduction as presented at the conference can be found here. All submissions had to be open source and the winning submissions have been posted in this GitHub repository. The winning teams consist of analysts working at WalMart, DDI, and HumRRO. They mostly built ensemble models, in Python and/or R, combining algorithms such as (light) gradient boosted trees, neural networks, and random forest analysis.
Timo Grossenbacher works as reporter/coder for SRF Data, the data journalism unit of Swiss Radio and TV. He analyzes and visualizes data and investigates data-driven stories. On his website, he hosts a growing list of cool projects. One of his recent blogs covers categorical spatial interpolation in R. The end result of that blog looks amazing:
This map was built with data Timo crowdsourced for one of his projects. With this data, Timo took the following steps, which are covered in his tutorial:
Read in the data, first the geometries (Germany political boundaries), then the point data upon which the interpolation will be based on.
Preprocess the data (simplify geometries, convert CSV point data into an sf object, reproject the geodata into the ETRS CRS, clip the point data to Germany, so data outside of Germany is discarded).
Then, a regular grid (a raster without “data”) is created. Each grid point in this raster will later be interpolated from the point data.
Run the spatial interpolation with the kknn package. Since this is quite computationally and memory intensive, the resulting raster is split up into 20 batches, and each batch is computed by a single CPU core in parallel.
Visualize the resulting raster with ggplot2.
All code for the above process can be accessed on Timo’s Github. The georeferenced points underlying the interpolation look like the below, where each point represents the location of a person who selected a certain pronunciation in an online survey. More details on the crowdsourced pronunciation project van be found here, .
Another of Timo’s R map, before he applied k-nearest neighbors on these crowdsourced data. [original]If you want to know more, please read the original blog or follow Timo’s new DataCamp course called Communicating with Data in the Tidyverse.
Past week, I came across two programming initiatives to uncover Twitter bots and one attempt to identify fake Instagram accounts.
Mike Kearney developed the R package botornot which applies machine learning to estimate the probability that a Twitter user is a bot. His default model is a gradient boosted model trained using both users-level (bio, location, number of followers and friends, etc.) and tweets-level information (number of hashtags, mentions, capital letters, etc.). This model is 93.53% accurate when classifying bots and 95.32% accurate when classifying non-bots. His faster model uses only the user-level data and is 91.78% accurate when classifying bots and 92.61% accurate when classifying non-bots. Unfortunately, the models did not classify my account correctly (see below), but you should definitely test yourself and your friends via this Shiny application.
Fun fact: botornot can be integrated with Mike’s rtweet package
Scraping Dirty Bots
At around the same time, I read this very interesting blog by Andy Patel. Annoyed by the fake Twitter accounts that kept liking and sharing his tweets, Andy wrote a Python script called pronbot_search. It’s an iterative search algorithm which Andy seeded with the dozen fake Twitter accounts that he identified originally. Subsequently, the program iterated over the friends and followers of each of these fake users, looking for other accounts displaying similar traits (e.g., similar description, including an URL to a sex-website called “Dirty Tinder”).
Whenever a new account was discovered, it was added to the query list, and the process continued. Because of the Twitter API restrictions, the whole crawling process took literal days before Andy manually terminated it. The results are just amazing:
After a day, the results looked like so. Notice the weird clusters of relationships in this network. [original]The full bot network uncovered by Andy included 22.000 fake Twitter accounts:
At the end of the weekend of March 10th, Andy had to stop the scraper after running for several days even though he had only processed 18% of the networks of the 22.000 included Twitter bots [original]The bot network on Twitter is probably enormous! Zooming in on the network, Andy notes that:
Pretty much the same pattern I’d seen after one day of crawling still existed after one week. Just a few of the clusters weren’t “flower” shaped.
Zoomed in to a specific part of the network you can see the separate clusters of bots doing little more than liking each others messages. [original]In his blog, Andy continues to look at all kind of data on these fake accounts. I found most striking that many of these account are years and years old already. Potentially, Twitter can use Mike Kearney’s botornot application to spot and remove them!
Most of the bots in the Dirty Tinder network found by Andy Patel were 3 to 8 years old already. [original]Andy was nice enough to share the data on these bot accounts here, for you to play with. His Python code is stored in the same github repo and more details around this project you can read in his original blog.
Fake Instagram Accounts
Finally, SRFdata (Timo Grossenbacher) attempted to uncover fake Instagram followers among the 7 million followers in the network of 115 important Swiss Instagram influencers in R. Magi Metrics was used to retrieve information for public Instagram accounts and rvest for private accounts. Next, clear fake accounts (e.g., little followers, following many, no posts, no profile picture, numbers in name) were labelled manually, and approximately 10% of the inspected 1000 accounts appeared fake. Finally, they trained a random forest model to classify fake accounts with a sensitivity (true negative) rate of 77.4% and an overall accuracy of around 94%.















{kind=link}