The 2018 annual Society for Industrial and Organizational Psychology (SIOP) conference featured its first-ever machine learning competition. Teams competed for several months in predicting the enployee turnover (or churn) in a large US company. A more complete introduction as presented at the conference can be found here. All submissions had to be open source and the winning submissions have been posted in this GitHub repository. The winning teams consist of analysts working at WalMart, DDI, and HumRRO. They mostly built ensemble models, in Python and/or R, combining algorithms such as (light) gradient boosted trees, neural networks, and random forest analysis.
Tag: peopleanalytics
13 Data-Driven Insights to Improve Your Job Search
Talent.Works is back, elaborating on the applicant characteristics that relate to landing an interview. While the majority of applicants has a meager ~2% chance of getting invited to an interview, some applicants do way better! What accounts for their success?

Analyzing 4000+ applicants, Talent.Works found 13 factors that related to getting an interview.
There are some things outside of the applicants’ control:
- Young applicants have higher chances (+25%).
- Women applicants have better chances (+48%).
- Applicants with a second degree have better chances (+22%).
Fortunately, applicants can boost their interview invitation rate using the following tricks:
- Apply on Monday (+46%), between 6 AM and 10 AM (+89%), and within the first four days (+65%).
- Start sentences with action-related verbs (+140%).
- Use numbers to demonstrate impact (+40%).
- Use occasional buzzwords / jargon (+29%) and skills (+59%).
- Use leadership-related words (+51%) and avoid overusing words related to teamwork and collaboration (-51%) or personal pronouns (-55%).
Here are some of these effects visualized:



Predictive HR Analytics
Tilburg University has set up a masterclass Predictive HR Analytics. In 3 days, the Professional Learning program will teach you all you need to know to implement predictive analytics and take HR to the next level. More information can be found here.
What makes this program unique?
- The masterclass Predictive HR Analytics goes beyond HR analytics and focuses on transformational people predictions. You learn how to embed predictive HR analytics into your HR Strategy and how to use your findings to convince others.
- The masterclass is developed at the prestigious Human Resources department at Tilburg University, which has obtained international recognition with its high-quality academic research in the HRM field.
- The mix of professors in conjunction with leading HR professionals leads to a strong academic program with a practical approach.
- Your peer participants will make sure that the class opens up a high-quality network of HR specialists. The diversity of leading companies from different sectors in the classroom creates new insights for all the participants.
- The program is like a 3-day pressure cooker. By combining online and offline components, we can create more in-depth discussions in the classroom.
- You will experience a high impact on your daily practice, since the program is focused on direct implementation.
Your profile
This course is ideal for anyone in HR seeking to become more adept in using quantitative data for decision making. Typical participants are (future) HR analysts, HR managers, HR business partners, HR consultants and (financial) business analysts with a strong link on people resources. Participants are from various sectors, such as financial services, healthcare institutions, government agencies and business services.

HR Analytics: Een 7e zintuig voor de moderne HR-professional
Wat gebeurt er in Nederland op het gebied van HR Analytics? Dit nieuwe boek laat zien wat enkele Nederlandse organisaties de afgelopen jaren daadwerkelijk hebben ondernomen. De verschillende auteurs, waaronder ik mij mag scharen, geven een kijkje in de praktijkwereld van het onderbouwen van HR-beslissingen aan de hand van diverse databronnen en analysetechnieken. Ze verklaren daarmee HR Analytics niet heilig, maar wie als HR- professional waarde wil toevoegen aan de business, kan er veel aan hebben. Het credo is dan: weet wat je moet doen, wees alert op de valkuilen en beschouw HR Analytics als een zevende zintuig naast je andere zintuigen. Met dit extra zintuig kun je als HR- professional scherper waarnemen wat het echte HR-probleem is, en wat mogelijk de oplossing is.
Het boek ‘HR Analytics’ is voor de moderne HR-professional die nieuwsgierig is naar wat analytics kan bij dragen aan zijn of haar professionaliteit. De voorbeelden en verhalen uit de praktijk leveren verschillende leerpunten en inzichten die helpen bij een meer analytische benadering van de diverse HR beleidsthema’s rondom recruitment, loopbanen, arbeidsvoorwaarden, training en opleiding of engagement. Het is een duwtje in de rug op weg naar HR Analytics als een toevoeging aan het HR-vak. Niet als vervanging.
Wiemer Renkema, recensist op managementboeken.nl, heeft het boek inmiddels gelezen en vat de inhoud mooi samen:
In de tien hoofdstukken van het boek komen de belangrijkste HR analytics voorbij, zoals die voor recruitment, carrièreontwikkeling, medewerkerstevredenheid en beloning. De lezer kan zelf de relevantie van ieder onderwerp bepalen en gericht de informatie zoeken die voor hem van belang is. Bij ieder onderwerp gaan de schrijvers in op alle kernvragen, wat het boek een overzichtelijke en makkelijk leesbare structuur geeft.
[…]
Je hebt geen lange adem nodig om HR analytics. Een 7e zintuig voor de moderne HR-professional te lezen. Wat een praktisch, compleet en goed geschreven boek is dit!
Wiemer Renkema, recensist [link]
Hier kun je een deel van het introductiehoofdstuk inzien om te kijken of het boek iets voor jou is.
Simpson’s Paradox: Two HR examples with R code.
Simpson (1951) demonstrated that a statistical relationship observed within a population—i.e., a group of individuals—could be reversed within all subgroups that make up that population. This phenomenon, where X seems to relate to Y in a certain way, but flips direction when the population is split for W, has since been referred to as Simpson’s paradox. Others names, according to Wikipedia, include the Simpson-Yule effect, reversal paradox or amalgamation paradox.
The most famous example has to be the seemingly gender-biased Berkeley admission rates:
“Examination of aggregate data on graduate admissions to the University of California, Berkeley, for fall 1973 shows a clear but misleading pattern of bias against female applicants. Examination of the disaggregated data reveals few decision-making units that show statistically significant departures from expected frequencies of female admissions, and about as many units appear to favor women as to favor men. If the data are properly pooled, taking into account the autonomy of departmental decision making, thus correcting for the tendency of women to apply to graduate departments that are more difficult for applicants of either sex to enter, there is a small but statistically significant bias in favor of women. […] The bias in the aggregated data stems not from any pattern of discrimination on the part of admissions committees, which seem quite fair on the whole, but apparently from prior screening at earlier levels of the educational system.” – part of abstract of Bickel, Hammel, & O’Connel (1975)
In a table, the effect becomes clear. While it seems as if women are rejected more often overall, women are actually less often rejected on a departmental level. Women simply applied to more selective departments more often (E & C below), resulting in the overall lower admission rate for women (35% as opposed to 44% for men).

Examples in HR
Simpsons Paradox can easily occur in organizational or human resources settings as well. Let me run you through two illustrated examples, I simulated:
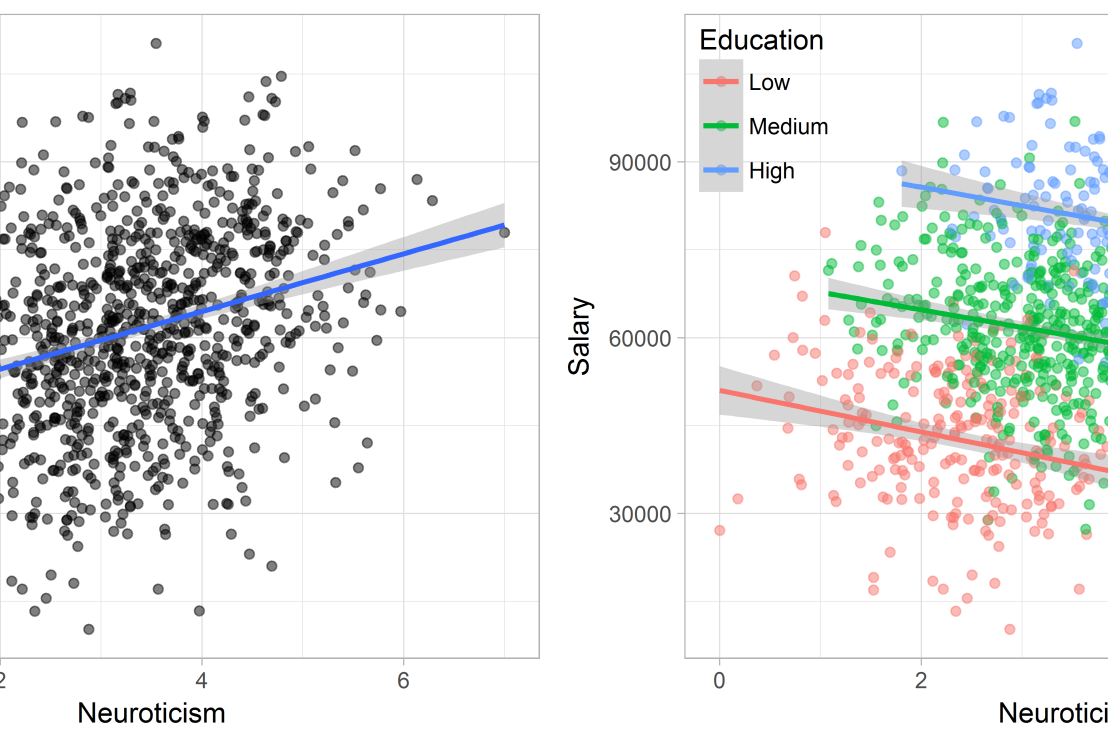
Assume you run a company of 1000 employees and you have asked all of them to fill out a Big Five personality survey. Per individual, you therefore have a score depicting his/her personality characteristic Neuroticism, which can run from 0 (not at all neurotic) to 7 (very neurotic). Now you are interested in the extent to which this Neuroticism of employees relates to their Job Performance (measured 0 – 100) and their Salary (measured in Euro’s per Year). In order to get a sense of the effects, you may decide to visualize both these relations in scatter plots:
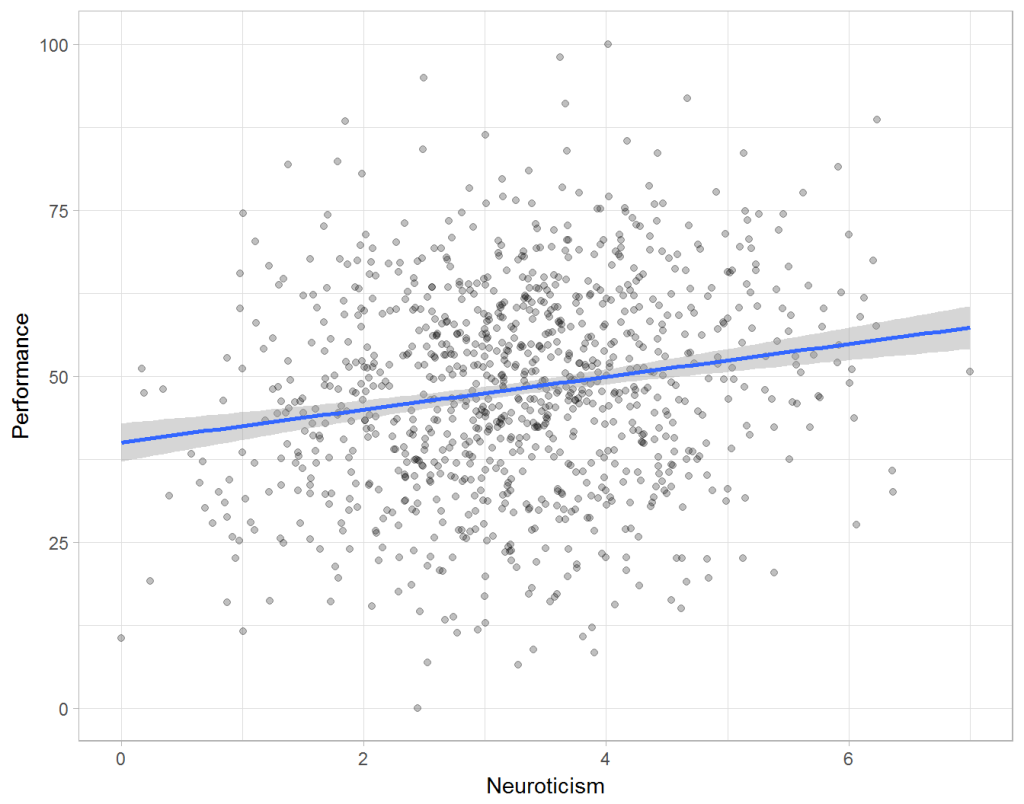
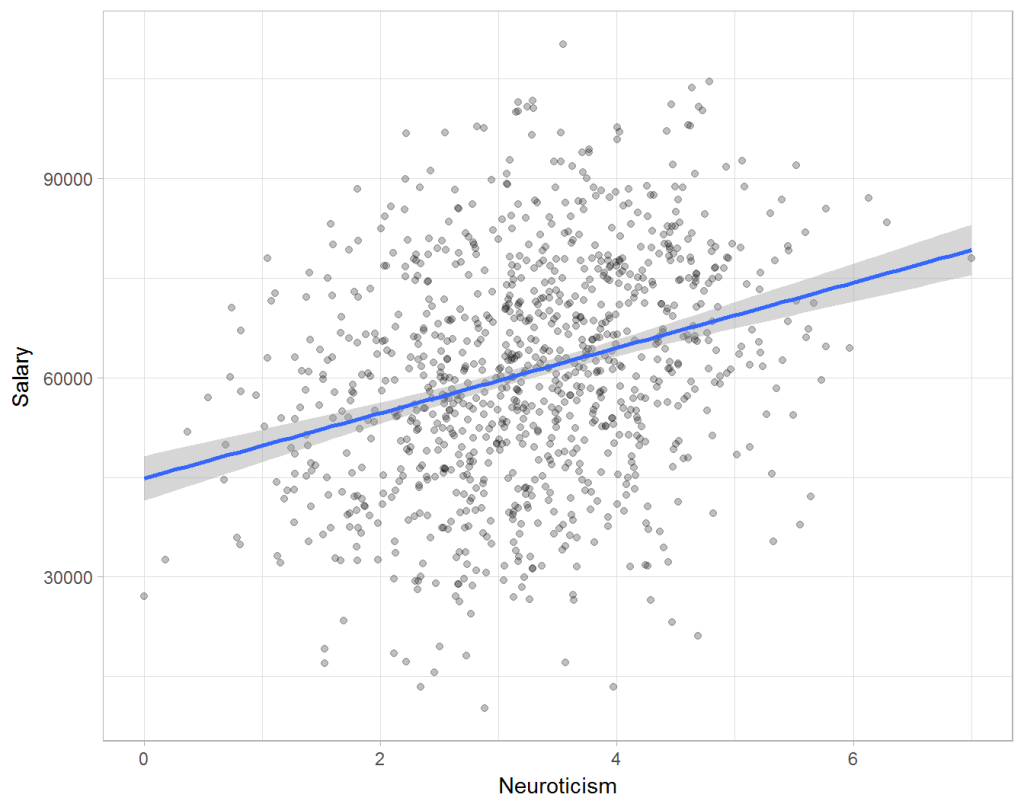
From these visualizations it would look like Neuroticism relates significantly and positively to both employees’ performance and their yearly salary. Should you select more neurotic people to improve your overall company performance? Or are you discriminating emotionally-stable (non-neurotic) employees when it comes to salary?
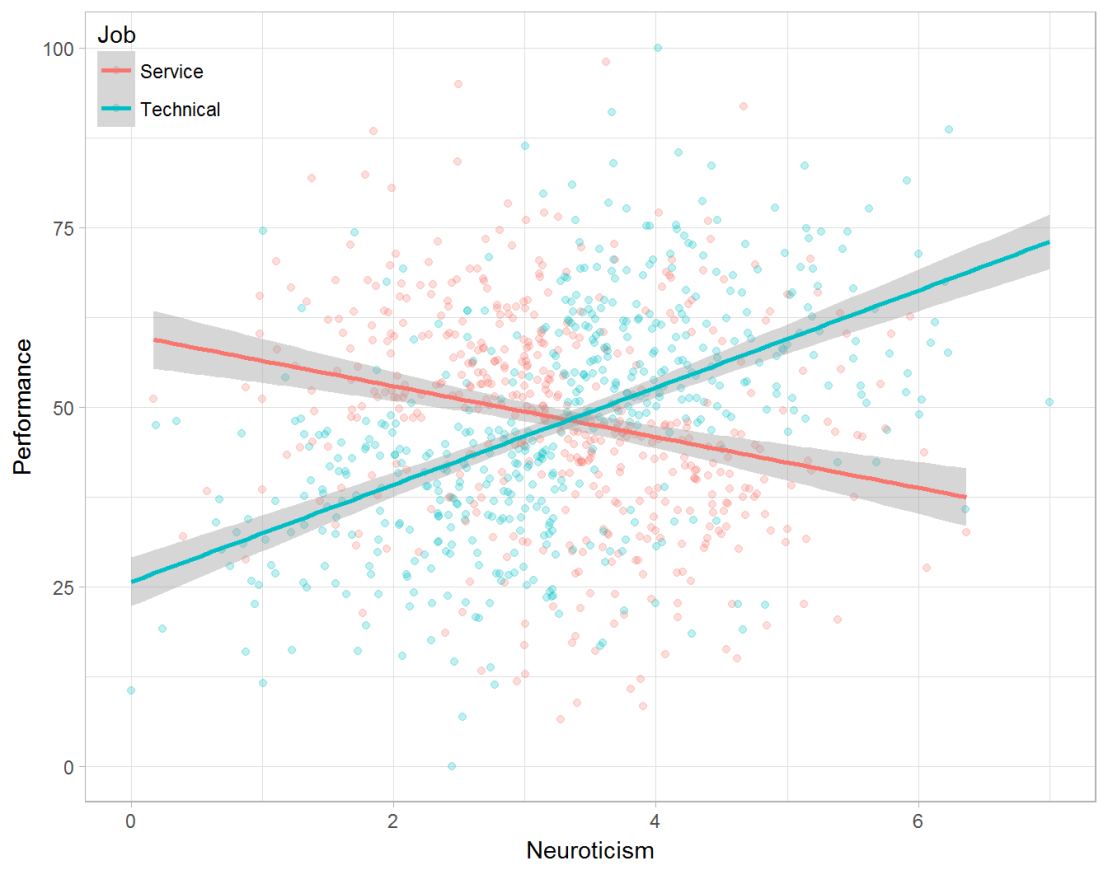
Taking a closer look at the subgroups in your data, you might however find very different relationships. For instance, the positive relationship between neuroticism and performance may only apply to technical positions, but not to those employees’ in service-oriented jobs.
Similarly, splitting the employees by education level, it becomes clear that there is a relationship between neuroticism and education level that may explain the earlier association with salary. More educated employees receive higher salaries and within these groups, neuroticism is actually related to lower yearly income.
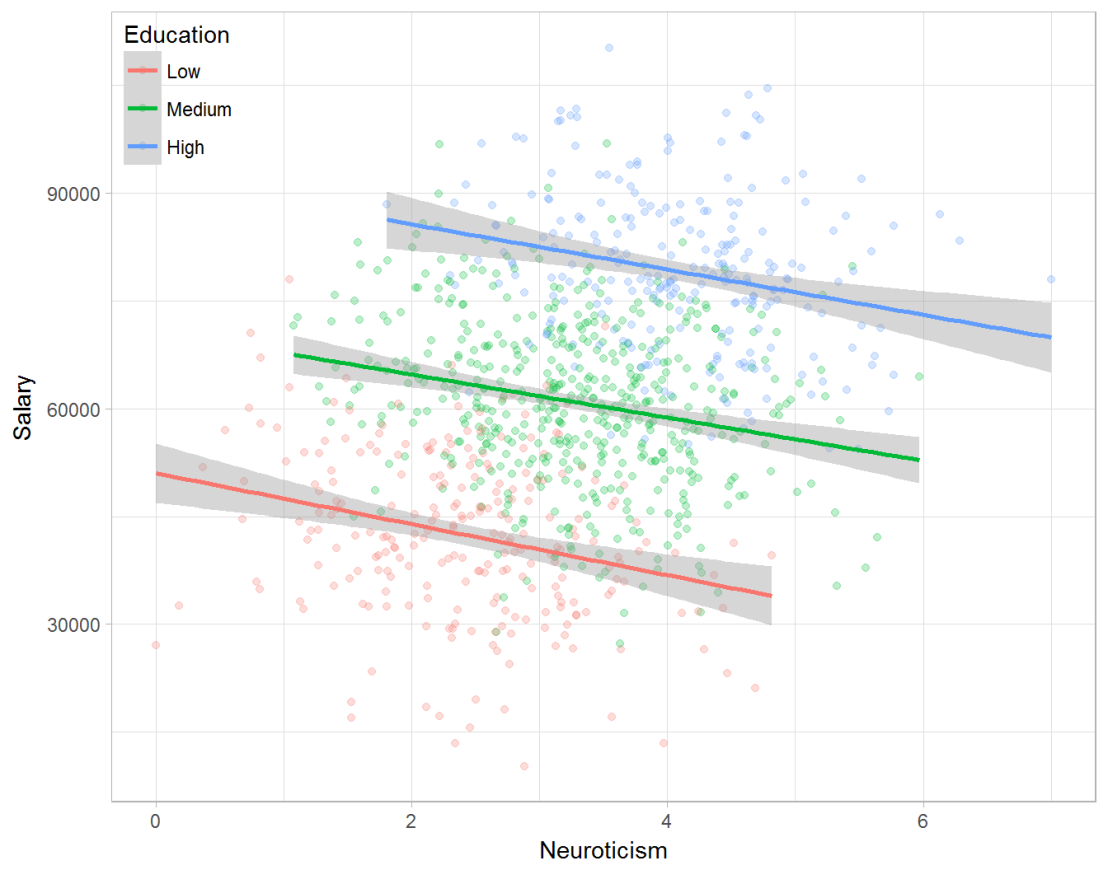
If you’d like to see the code used to simulate these data and generate the examples, you can find the R markdown file here on Rpubs.
Solving the paradox
Kievit and colleagues (2013) argue that Simpsons paradox may occur in a wide variety of research designs, methods, and questions, particularly within the social and medical sciences. As such, they propose several means to “control” or minimize the risk of it occurring. The paradox may be prevented from occurring altogether by more rigorous research design: testing mechanisms in longitudinal or intervention studies. However, this is not always feasible. Alternatively, the researchers pose that data visualization may help recognize the patterns and subgroups and thereby diagnose paradoxes. This may be easy if your data looks like this:

But rather hard, or even impossible, when your data looks more like the below:

Clustering may nevertheless help to detect Simpson’s paradox when it is not directly observable in the data. To this end, Kievit and Epskamp (2012) have developed a tool to facilitate the detection of hitherto undetected patterns of association in existing datasets. It is written in R, a language specifically tailored for a wide variety of statistical analyses which makes it very suitable for integration into the regular analysis workflow. As an R package, the tool is is freely available and specializes in the detection of cases of Simpson’s paradox for bivariate continuous data with categorical grouping variables (also known as Robinson’s paradox), a very common inference type for psychologists. Finally, its code is open source and can be extended and improved upon depending on the nature of the data being studied.
One example of application is provided in the paper, for a dataset on coffee and neuroticism. A regression analysis would suggest a significant positive association between coffee and neuroticism overall. However, when the detection algorithm of the R package is applied, a different picture appears: the analysis shows that there are three latent clusters present and that the purported positive relationship only holds for one cluster whereas it is negative in the others.

Update 24-10-2017: minutephysics – one of my favorite YouTube channels – uploaded a video explaining Simpson’s paradox very intuitively in a medical context:
Update 01-11-2017: minutephysics uploaded a follow-up video:
The paradox is that we remain reluctant to fight our bias, even when they are put in plain sight.
