The repository consists of tools for multiple languages (R, Python, Matlab, Java) and resources in the form of:
Books & Academic Papers
Online Courses and Videos
Outlier Datasets
Algorithms and Applications
Open-source and Commercial Libraries/Toolkits
Key Conferences & Journals
Outlier Detection (also known as Anomaly Detection) is an exciting yet challenging field, which aims to identify outlying objects that are deviant from the general data distribution. Outlier detection has been proven critical in many fields, such as credit card fraud analytics, network intrusion detection, and mechanical unit defect detection.
This specific link has been on my to-do list for so-long now that I’ve decided to just share it without any further ado.
The people behind GoalKicker, for whatever reason, decided to compile nearly 100 books on different programming languages based on among others StackOverflow entries. Their open access library contains books on languages from Latex to Linux, from Java to JavaScript, from SQL to MySQL, and from C, to C++, C#, and objective-C.
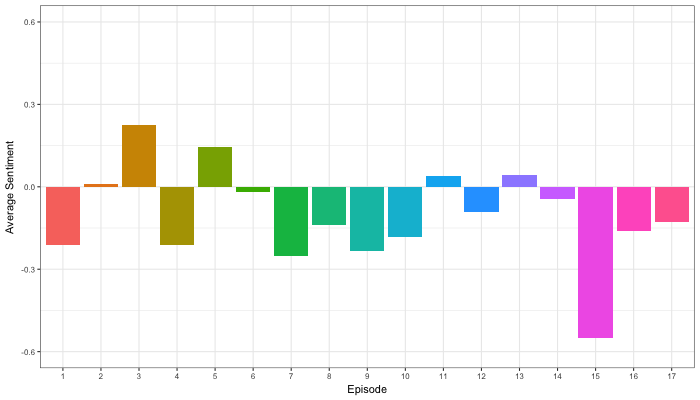
Jordan Dworkin, a Biostatistics PhD student at the University of Pennsylvania, is one of the few million fans of Stranger Things, a 80s-themed Netflix series combining drama, fantasy, mystery, and horror. Awaiting the third season, Jordan was curious as to the emotional voyage viewers went through during the series, and he decided to examine this using a statistical approach. Like I did for the seven Harry Plotter books, Jordan downloaded the scripts of all the Stranger Things episodes and conducted a sentiment analysis in R, of course using the tidyverse and tidytext. Jordan measured the positive or negative sentiment of the words in them using the AFINN dictionary and a first exploration led Jordan to visualize these average sentiment scores per episode:
The average positive/negative sentiment during the 17 episodes of the first two seasons of Stranger Things (from Medium.com)
Jordan jokingly explains that you might expect such overly negative sentiment in show about missing children and inter-dimensional monsters. The less-than-well-received episode 15 stands out, Jordan feels this may be due to a combination of its dark plot and the lack of any comedic relief from the main characters.
Reflecting on the visual above, Jordan felt that a lot of the granularity of the actual sentiment was missing. For a next analysis, he thus calculated a rolling average sentiment during the course of the separate episodes, which he animated using the animation package:
GIF displaying the rolling average (40 words) sentiment per Stranger Things episode (from Medium.com)
Jordan has two new takeaways: (1) only 3 of the 17 episodes have a positive ending – the Season 1 finale, the Season 2 premiere, and the Season 2 finale – (2) the episodes do not follow a clear emotional pattern. Based on this second finding, Jordan subsequently compared the average emotional trajectories of the two seasons, but the difference was not significant:
Smoothed (loess, I guess) trajectories of the sentiment during the episodes in seasons one and two of Stranger Things (from Medium.com)
Potentially, it’s better to classify the episodes based on their emotional trajectory than on the season they below too, Jordan thought next. Hence, he constructed a network based on the similarity (temporal correlation) between episodes’ temporal sentiment scores. In this network, the episodes are the nodes whereas the edges are weighted for the similarity of their emotional trajectories. In that sense, more distant episodes are less similar in terms of their emotional trajectory. The network below, made using igraph (see also here), demonstrates that consecutive episodes (1 → 2, 2 → 3, 3 → 4) are not that much alike:
The network of Stranger Things episodes, where the relations between the episodes are weighted for the similarity of their emotional trajectories (from Medium.com).
Three different emotional trajectories were identified among the 17 Stranger Things episodes in Season 1 and 2 (from Medium.com).
Looking at the average patterns, we can see that group 1 contains episodes that begin and end with neutral emotion and have slow fluctuations in the middle, group 2 contains episodes that begin with negative emotion and gradually climb towards a positive ending, and group 3 contains episodes that begin on a positive note and oscillate downwards towards a darker ending.
Jordan final suggestion is that producers and scriptwriters may consciously introduce these variations in emotional trajectories among consecutive episodes in order to get viewers hooked. If you want to redo the analysis or reuse some of the code used to create the visuals above, you can access Jordan’s R scripts here. I, for one, look forward to his analysis of Season 3!
When I was an undergrad, I was told that beyond a certain sample size (n=30 if I recall correctly), t-tests and ANOVAs are fine. This was a lie. I wished I had been taught robust methods and that t-tests and ANOVAs on means are only a few options among many alternatives. Indeed, t-tests and ANOVAs on means are not robust to outliers, skewness, heavy-tails, and for independent groups, differences in skewness, variance (heteroscedasticity) and combinations of these factors (Wilcox & Keselman, 2003; Wilcox, 2012). The main consequence is a lack of statistical power. For this reason, it is often advised to report a measure of effect size to determine, for instance, if a non-significant effect (based on some arbitrary p value threshold) could be due to lack of power, or reflect a genuine lack of effect. The rationale is that an effect could be associated with a sufficiently large effect…