Continuing my recent line of posts on data visualization resources, I found another repository in my inbox: OriginLab’s GraphGallery!
If I’m being honest, I would personally advice you to look at the dataviz project instead, if you haven’t heard of that one yet.
However, OriginLab might win in terms of sentiment. It has this nostalgic look of the ’90s, and apparently people really used it during that time. Nevertheless, despite looking old, the repo seems to be quite extensive, with nearly 400 different types of data visualizations:
Quantity isn’t everything though, as some of the 400 entries are disgustingly horrible:
There’s so much wrong with this graph…
What I do like about this OriginLab repo is that it has an option to sort its contents using a random order. This really facilitates discovery of new pearls:
Thanks to Maarten Lambrechts for sharing this resource on twitter a while back!
This visualisation tool I've never heard of is used by "500.000 scientists and engineers" and has an amazing gallery of 388 different chart types and variations https://t.co/0N3Td6jhqlpic.twitter.com/A7g4DeEGEv
I’ve mentioned before that I dislike wordclouds (for instance here, or here) and apparently others share that sentiment. In his recent Medium blog, Daniel McNichol goes as far as to refer to the wordcloud as the pie chart of text data! Among others, Daniel calls wordclouds disorienting, one-dimensional, arbitrary and opaque and he mentions their lack of order, information, and scale.
Wordcloud of the negative characteristics of wordclouds, via Medium
Instead of using wordclouds, Daniel suggests we revert to alternative approaches. For instance, in their Tidy Text Mining with R book, Julia Silge and David Robinson suggest using bar charts or network graphs, providing the necessary R code. Another alternative is provided in Daniel’s blog: the chatterplot!
While Daniel didn’t invent this unorthodox wordcloud-like plot, he might have been the first to name it a chatterplot. Daniel’s chatterplot uses a full x/y cartesian plane, turning the usually only arbitrary though exploratory wordcloud into a more quantitatively sound, information-rich visualization.
R package ggplot’s geom_text() function — or alternatively ggrepel‘s geom_text_repel() for better legibility — is perfectly suited for making a chatterplot. And interesting features/variables for the axis — apart from the regular word frequencies — can be easily computed using the R tidytext package.
Here’s an example generated by Daniel, plotting words simulatenously by their frequency of occurance in comments to Hacker News articles (y-axis) as well as by the respective popularity of the comments the word was used in (log of the ranking, on the x-axis).
[CHATTERPLOTs are] like a wordcloud, except there’s actual quantitative logic to the order, placement & aesthetic aspects of the elements, along with an explicit scale reference for each. This allows us to represent more, multidimensional information in the plot, & provides the viewer with a coherent visual logic& direction by which to explore the data.
I highly recommend the use of these chatterplots over their less-informative wordcloud counterpart, and strongly suggest you read Daniel’s original blog, in which you can also find the R code for the above visualizations.
Xeno.graphics is the collection of unusual charts and maps Maarten Lambrechts maintains. It’s a repository of novel, innovative, and experimental visualizations to inspire you, to fight xenographphobia, and popularize new chart types.
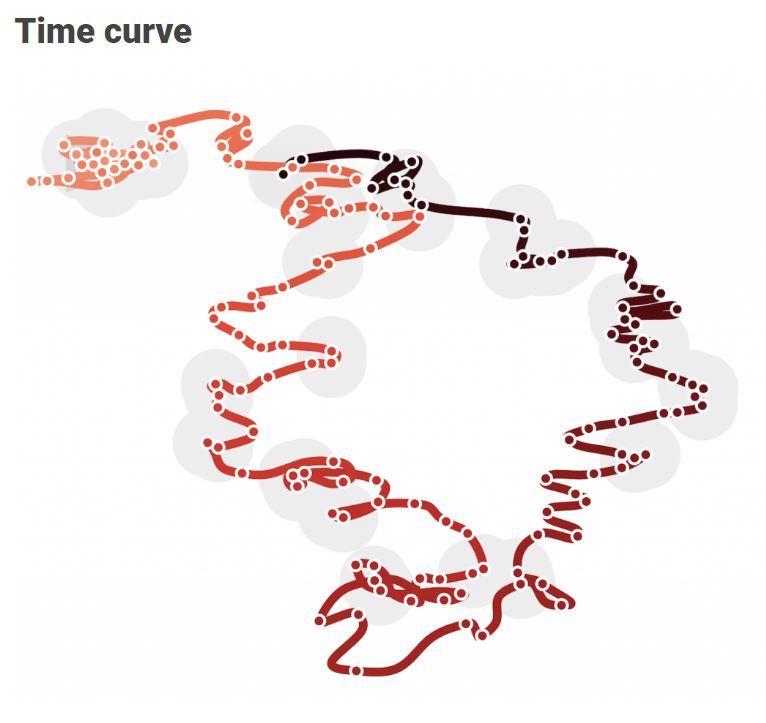
For instance, have you ever before heard of a time curve? These are very useful to visualize the development of a relationship over time.
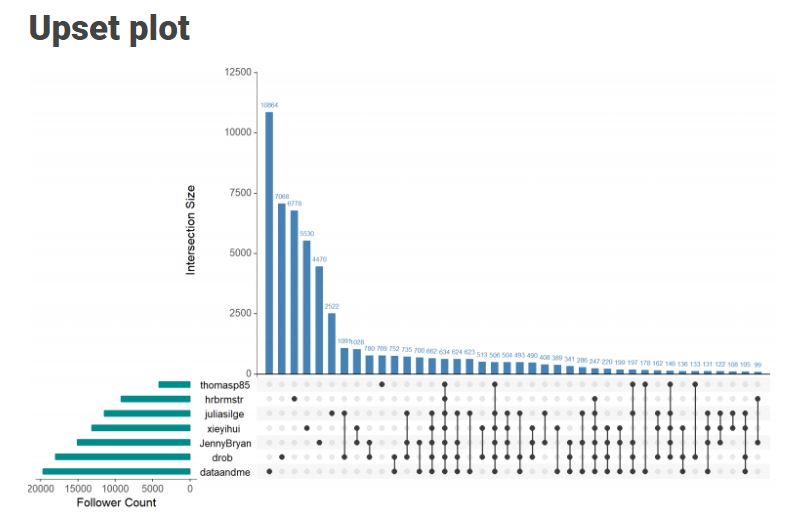
Time curves are based on the metaphor of folding a timeline visualization into itself so as to bring similar time points close to each other. This metaphor can be applied to any dataset where a similarity metric between temporal snapshots can be defined, thus it is largely datatype-agnostic. [https://xeno.graphics/time-curve]The upset plot is another example of an upcoming visualization. It can demonstrate the overlap or insection in a dataset. For instance, in the social network of #rstats twitter heroes, as the below example from the Xenographics website does.
Understanding relationships between sets is an important analysis task. The major challenge in this context is the combinatorial explosion of the number of set intersections if the number of sets exceeds a trivial threshold. To address this, we introduce UpSet, a novel visualization technique for the quantitative analysis of sets, their intersections, and aggregates of intersections. [https://xeno.graphics/upset-plot/]The below necklace map is new to me too. What it does precisely is unclear to me as well.
In a necklace map, the regions of the underlying two-dimensional map are projected onto intervals on a one-dimensional curve (the necklace) that surrounds the map regions. Symbols are scaled such that their area corresponds to the data of their region and placed without overlap inside the corresponding interval on the necklace. [https://xeno.graphics/necklace-map/]There are hundreds of other interestingcharts, maps, figures, and plots, so do have a look yourself. Moreover, the xenographics collection is still growing. If you know of one that isn’t here already, please submit it. You can also expect some posts about certain topics around xenographics.
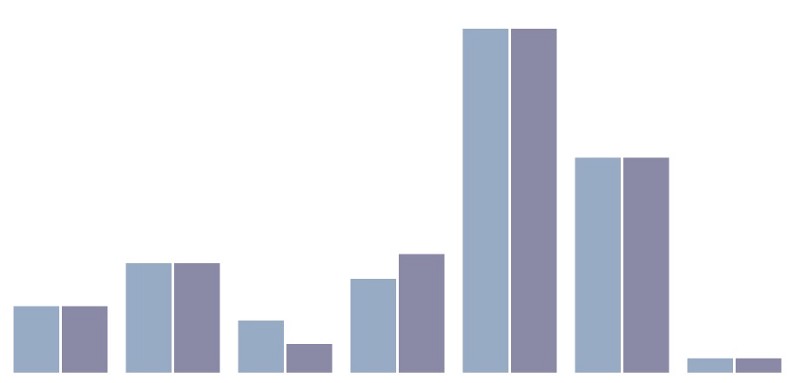
Many people have criticized the pie chart. The most important critique is that we, humans, are good in comparing lengths and heights, but angles and areas not so much. The following three charts by Kristin Henry demonstrate the phenomenon. Can you spot how the two pie charts below are different?
And how about now?
OK, I admit that the order of the categories matters quite a lot in the chart above. But alternatively, you can transform the pie charts into grouped bar charts, that will immediately show the difference:
In general, pie charts should be avoided when a large number of items is considered. Simple pie charts displaying 2-3 categories or one category as opposed to the others may work just fine, but when displaying more data, it is better to choose a different chart type. Oracle hosted a different example some years back: