YouTube recommended I’d watch this recorded presentation by Raymond Hettinger at PyBay2019 last October. Quite a long presentation for what I’d normally watch, but what an eye-openers it contains!
Raymond Hettinger is a Python core developer and in this video he presents 10 programming strategies in these 60 minutes, all using live examples. Some are quite obvious, but the presentation and examples make them very clear. Raymond presents some serious programming truths, and I think they’ll stick.
First, Raymond discusses chunking and aliasing. He brings up the theory that the human mind can only handle/remember 7 pieces of information at a time, give or take 2. Anything above proves to much cognitive load, and causes discomfort as well as errors. Hence, in a programming context, we need to make sure programmers can use all 7 to improve the code, rather than having to decypher what’s in front of them. In a programming context, we do so by modularizing and standardizing through functions, modules, and packages. Raymond uses the Python random module to hightlight the importance of chunking and modular code. This part was quite long, but still interesting.
For the next two strategies, Raymond quotes the Feinmann method of solving problems: “(1) write down a clear problem specification; (2) think very, very hard; (3) write down a solution”. Using the example of a tree walker, Raymond shows how the strategies of incremental development and solving simpler programs can help you build programs that solve complex problems. This part only lasts a couple of minutes but really underlines the immense value of these strategies.
Next, Raymond touches on the DRY principle: Don’t Repeat Yourself. But in a context I haven’t seen it in yet, object oriented programming [OOP], classes, and inherintance.
Raymond continues to build his arsenal of programming strategies in the next 10 minutes, where he argues that programmers should repeat tasks manually until patterns emerge, before they starting moving code into functions. Even though I might not fully agree with him here, he does have some fun examples of file conversion that speak in his case.
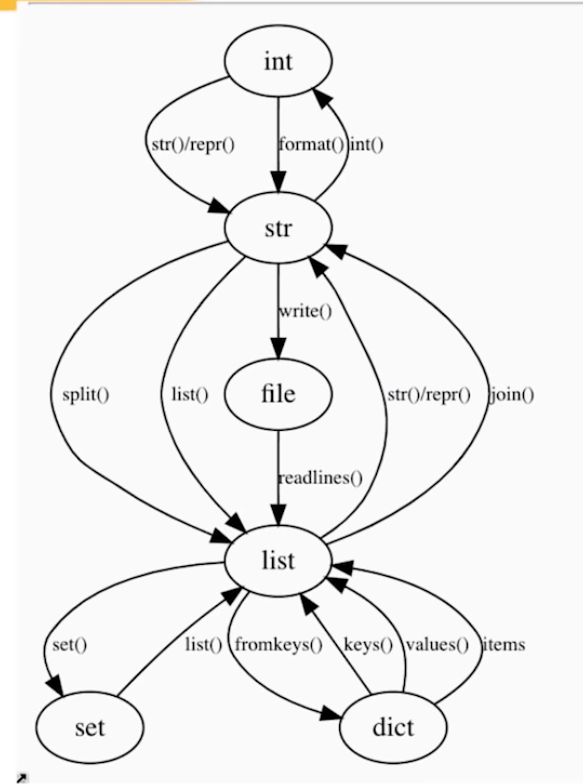
Lastly, Raymond uses the graph below to make the case that OOP is a graph traversal problem. According to Raymond, the Python ecosystem is so rich that there’s often no need to make new classes. You can simply look at the graph below. Look for the island you are currently on, check which island you need to get to, and just use the methods that are available, or write some new ones.
While there were several more strategies that Raymond wanted to discuss, he doesn’t make it to the end of his list of strategies as he spend to much time on the first, chunking bit. Super curious as to the rest? Contact Raymond on Twitter.
After several years of proscrastinating, the inevitable finally happened: Three months ago, I committed to learning Python!
I must say that getting started was not easy. One afternoon three months ago, I sat down, motivated to get started. Obviously, the first step was to download and install Python as well as something to write actual Python code. Coming from R, I had expected to be coding in a handy IDE within an hour or so. Oh boy, what was I wrong.
Apparently, there were already a couple of versions of Python present on my computer. And apparently, they were in grave conflict. I had one for the R reticulate package; one had come with Anaconda; another one from messing around with Tensorflow; and some more even. I was getting all kinds of error, warning, and conflict messages already, only 10 minutes in. Nothing I couldn’t handle in the end, but my good spirits had dropped slightly.
With Python installed, the obvious next step was to find the RStudio among the Python IDE’s and get working in that new environment. As an rational consumer, I went online to read about what people recommend as a good IDE. PyCharm seemed to be quite fancy for Data Science. However, what’s this Spyder alternative other people keep talking about? Come again, there are also Rodeo, Thonny, PyDev, and Wing? What about those then? A whole other group of Pythonista’s said that, as I work in Data Science, I should get Anaconda and work solely in Jupyter Notebooks! Okay…? But I want to learn Python to broaden my skills and do more regular software development as well. Maybe I start simple, in a (code) editor? However, here we have Atom, Sublime Text, Vim, and Eclipse? All these decisions. And I personally really dislike making regrettable decisions or committing to something suboptimal. This was already taking much, much longer than the few hours I had planned for setup.
This whole process demotivated so much that I reverted back to programming in R and RStudio the week after. However, I had not given up. Over the course of the week, I brought the selection back to Anaconda Jupyter Notebooks, PyCharm, and Atom, and I was ready to pick one. But wait… What’s this Visual Studio Code (VSC) thing by Microsoft. This looks fancy. And it’s still being developed and expanded. I had already been working in Visual Studio learning C++, and my experiences had been good so far. Moreover, Microsoft seems a reliable software development company, they must be able to build a good IDE? I decided to do one last deepdive.
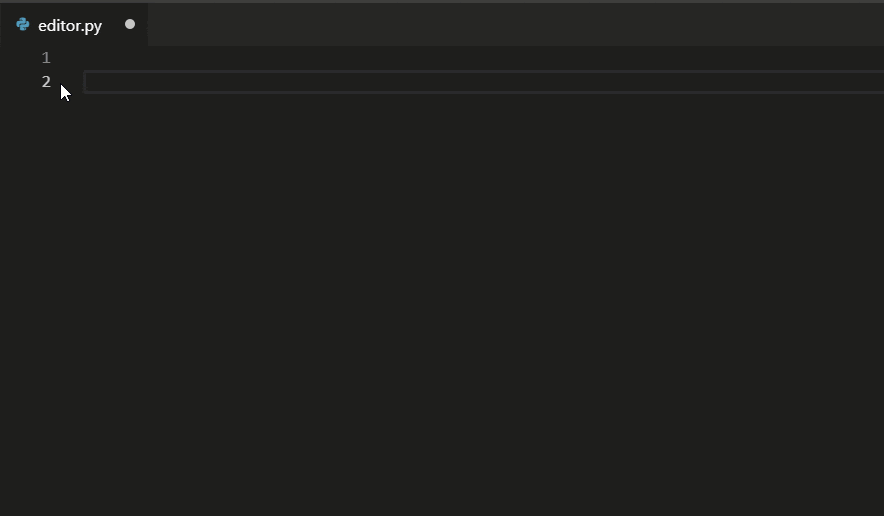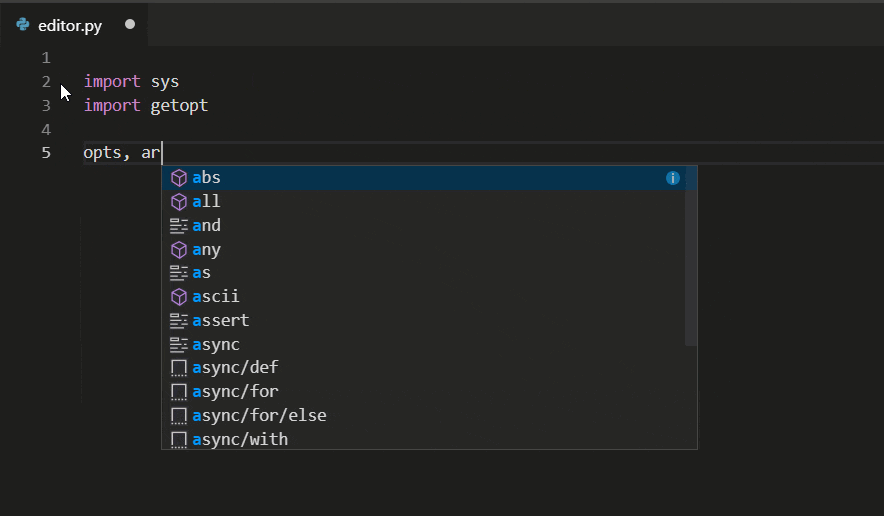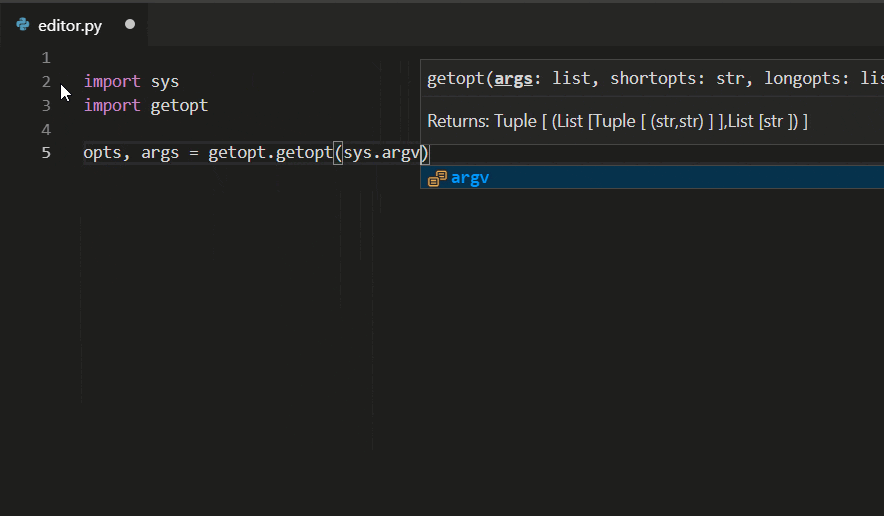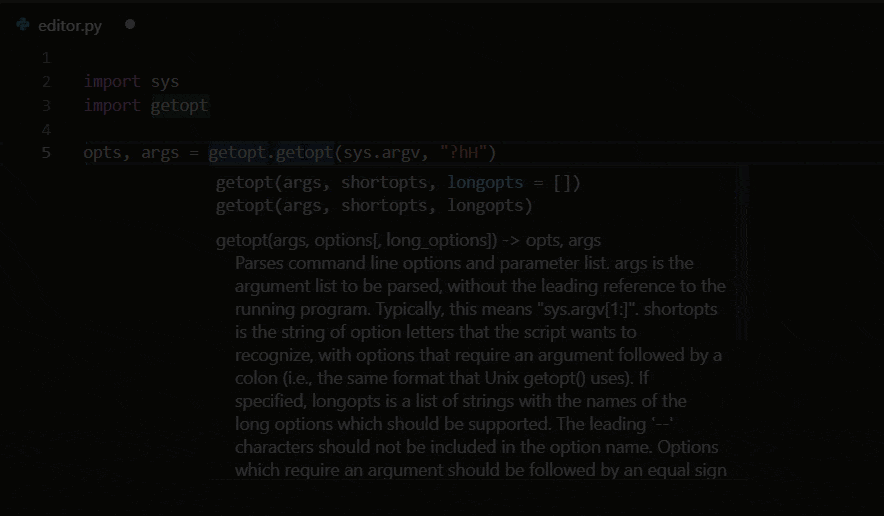
The more I read about VSC and its features for Python, the more excited I got. Hey, VSC’s Python extension automatically detects Python interpreters, so it solves my conflicts-problem. Linting you say? Never heard of it, but I’ll have it. Okay, able to run notebooks, nice! Easy debugging, testing, and handy snippets… Okay! Machine learning-based IntelliSense autocompletes your Python code – that sounds like something I’d like. A shit-ton of extensions? Yes please! Multi-language support – even tools for R programming? Say no more! I’ll take it. I’ll take it all!
Linting in VSC provides code suggestions
My goods friends at Microsoft were not done yet though. To top it all of, they have documented everything so well. It’s super easy to get started! There are numerous ordered pages dedicated to helping you set up and discover your new Python environment in VSC:
The Microsoft VSC pages also link to some more specific resources:
Editing Python in VS Code: Learn more about how to take advantage of VS Code’s autocomplete and IntelliSense support for Python, including how to customize their behvior… or just turn them off.
Linting Python: Linting is the process of running a program that will analyse code for potential errors. Learn about the different forms of linting support VS Code provides for Python and how to set it up.
Debugging Python: Debugging is the process of identifying and removing errors from a computer program. This article covers how to initialize and configure debugging for Python with VS Code, how to set and validate breakpoints, attach a local script, perform debugging for different app types or on a remote computer, and some basic troubleshooting.
Unit testing Python: Covers some background explaining what unit testing means, an example walkthrough, enabling a test framework, creating and running your tests, debugging tests, and test configuration settings.
Python IntelliSense in VSC makes real-time code autocomplete suggestions
My Own Python Journey
So three months in I am completely blown away at how easy, fun, and versatile the language is. Nearly anything is possible, most of the language is intuitive and straightforward, and there’s a package for anything you can think of. Although I have spent many hours, I am very happy with the results. I did not get this far, this quickly, in any other language. Let me share some of the stuff I’ve done the past three months.
I’ve mainly been building stuff. Some things from scratch, others by tweaking and recycling other people’s code. In my opinion, reusing other people’s code is not necessarily bad, as long as you understand what the code does. Moreover, I’ve combed through lists and lists of build-it-yourself projects to get inspiration for projects and used stuff from my daily work and personal life as further reasons to code. I ended up building:
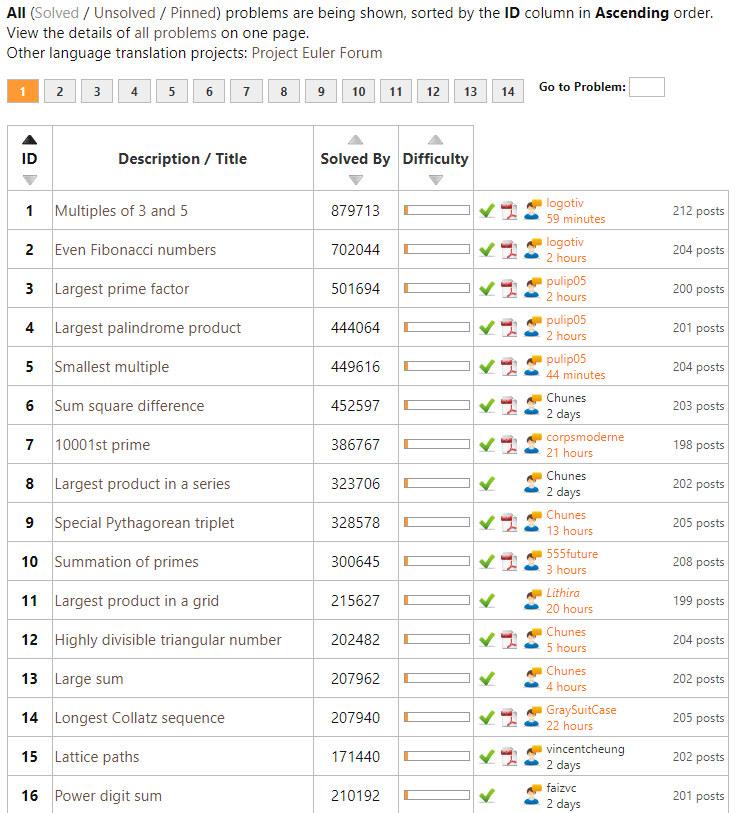
solutions to the first 31 problems of Project Euler, which I highly recommend you try to solve yourself!
solutions to the first dozen problems posed in Automate the Boring Stuff with Python. This book and online tutorial forces you to get your hands dirty right from the start. Simply amazing content and the learning curve is precisely good
"Programming today is a race between software engineers striving to build bigger and better idiot-proof programs, and the universe trying to build bigger and better idiots. So far, the universe is winning." – Rick Cook#programming#coding#ArtificialStupidity no.20 pic.twitter.com/cBiR1HQszn
all Socratica Python Youtube videos. They are simply a fantastic introduction to the language and amazingly amusing. You can sponsor them here
hours and hours of Corey Shafer’s Youtube channel. Seriously good quality content, and more in-depth than Socratica. Corey covers the versatile functionalities included in the standard Python libraries and then some more
Although it is no longer maintained, you might find some more, interesting links on my Python resources page or here, for those transitioning from R. If only the links to the more up-to-date resources pages. Anyway, hope this current blog helps you on your Python journey or to get Python and Visual Studio Code working on your computer. Please feel free to share any of the stories, struggles, or successes you experience!
Over the last months I’ve been working my way through Project Euler in my spare time. I wanted to learn Python programming, and what better way than solving mini-problems and -projects?!
Well, Project Euler got a ton of these, listed in increasing order of difficulty. It starts out simple: to solve the first problem you need to write a program to identify multiples of 3 and 5. Next, in problem two, you are asked to sum the first thousand even Fibonacci numbers. Each problem, the task at hand gets slighly more difficult…
For me, Project Euler combines math, programming, and stats in a way that really keeps me motivated to continue and learn new concepts and programming / problem-solving approaches.
However, at problem 31, I really got stuck. For several hours, I struggled to solve it in a satisfactory fashion, even though most other problems only take 5-90 minutes.
After hours of struggling, I pretty much gave up, and googled some potential solutions. Aparently, the way to solve problem 31, is to take a so-called dynamic programming approach.
Dynamic programming is both a mathematical optimization method and a computer programming method. The method was developed by Richard Bellman in the 1950s and has found applications in numerous fields, from aerospace engineering to economics. In both contexts it refers to simplifying a complicated problem by breaking it down into simpler sub-problems in a recursive manner. While some decision problems cannot be taken apart this way, decisions that span several points in time do often break apart recursively. Likewise, in computer science, if a problem can be solved optimally by breaking it into sub-problems and then recursively finding the optimal solutions to the sub-problems, then it is said to have optimal substructure.
Now, this sounded like something I’d like to learn more about! I was already quite familiar with recursive problems and solutions, but this dynamic programming sounded next-level.
So I googled and googled for tutorials and other resources, and I finally came across this free 2011 MIT course that I intend to view over the coming weeks.
There’s even a course website with additional materials and assignments (in Python).
For those less interested in (dynamic) programming but mostly in machine learning, there’s this other great MIT OpenCourseWare youtube playlist of their Artificial Intelligence course. I absolutely loved that course and I really powered through it in a matter of weeks (which is why I am already psyched about this new one). I learned so much new concepts, and I strongly recommend it. Unfortunately, the professor recently passed away.
Last week, this interesting reddit thread was filled with overviews for cool projects that may help you learn a programming language. The top entries are:
Lars Albertsson, former software engineer at Spotify and Google and currently freelance data engineer via mapflat, maintains this list of data engineering resources. It includes many links to videos and courses about data pipelines, batch processing, Kafka, NoSQL, Clojure, Scala, Parquet, Luigi, Storm, Spark, Hadoop, Cassandra, and other tools I am not too familiar with. Looks like it could function as a great curated overview for starters.
PyData is famous for it’s great talks on machine learning topics. This 2019 London edition, Vincent Warmerdamagain managed to give a super inspiring presentation. This year he covers what he dubs Artificial Stupidity™. You should definitely watch the talk, which includes some great visual aids, but here are my main takeaways:
Vincent speaks of Artificial Stupidity, of machine learning gone HorriblyWrong™ — an example of which below — for which Vincent elaborates on three potential fixes:
Example of a model that goes HorriblyWrong™, according to Vincent’s talk.
1. Predict Less, but Carefully
Vincent argues you shouldn’t extrapolate your predictions outside of your observed sampling space. Even better: “Not predicting given uncertainty is a great idea.” As an alternative, we could for instance design a fallback mechanism, by including an outlier detection model as the first step of your machine learning model pipeline and only predict for non-outliers.
I definately recommend you watch this specific section of Vincent’s talk because he gives some very visual and intuitive explanations of how extrapolation may go HorriblyWrong™.
Be careful! One thing we should maybe start talking about to our bosses: Algorithms merely automate, approximate, and interpolate. It’s the extrapolation that is actually kind of dangerous.
Vincent Warmerdam @ Pydata 2019 London
Basically, we can choose to not make automated decisions sometimes.
2. Constrain thy Features
What we feed to our models really matters. […] You should probably do something to the data going into your model if you want your model to have any sort of fairness garantuees.
Vincent Warmerdam @ Pydata 2019 London
Often, simply removing biased features from your data does not reduce bias to the extent we may have hoped. Fortunately, Vincent demonstrates how to remove biased information from your variables by applying some cool math tricks.
Unfortunately, doing so will often result in a lesser predictive accuracy. Unsurprisingly though, as you are not closely fitting the biased data any more. What makes matters more problematic, Vincent rightfully mentions, is that corporate incentives often not really align here. It might feel that you need to pick: it’s either more accuracy or it’s more fairness.
However, there’s a nice solution that builds on point 1. We can now take the highly accurate model and the highly fair model, make predictions with both, and when these predictions differ, that’s a very good proxy where you potentially don’t want to make a prediction. Hence, there may be observations/samples where we are comfortable in making a fair prediction, whereas in most other situations we may say “right, this prediction seems unfair, we need a fallback mechanism, a human being should look at this and we should not automate this decision”.
Vincent does not that this is only one trick to constrain your model for fairness, and that fairness may often only be fair in the eyes of the beholder. Moreover, in order to correct for these biases and unfairness, you need to know about these unfair biases. Although outside of the scope of this specific topic, Vincent proposes this introduces new ethical issues:
Basically, we can choose to put our models on a controlled diet.
3. Constrain thy Model
Vincent argues that we should include constraints (based on domain knowledge, or common sense) into our models. In his presentation, he names a few. For instance, monotonicity, which implies that the relationship between X and Y should always be either entirely non-increasing, or entirely non-decreasing. Incorporating the previously discussed fairness principles would be a second example, and there are many more.
If we every come up with a model where more smoking leads to better health, that’s bad. I have enough domain knowledge to say that that should never happen. So maybe I should just make a system where I can say “look this one column with relationship to Y should always be strictly negative”.
Vincent Warmerdam @ Pydata 2019 London
Basically, we can integrate domain knowledge or preferences into our models.