Both in science and business, we often experience difficulties collecting enough data to test our hypotheses, either because target groups are small or hard to access, or because data collection entails prohibitive costs.
Such obstacles may result in data sets that are too small for the complexity of the statistical model needed to answer the questions we’re really interested in.
This unique book provides guidelines and tools for implementing solutions to issues that arise in small sample studies. Each chapter illustrates statistical methods that allow researchers and analysts to apply the optimal statistical model for their research question when the sample is too small.
This book will enable anyone working with data to test their hypotheses even when the statistical model required for answering their questions are too complex for the sample sizes they can collect. The covered statistical models range from the estimation of a population mean to models with latent variables and nested observations, and solutions include both classical and Bayesian methods. All proposed solutions are described in steps researchers can implement with their own data and are accompanied with annotated syntax in R.
Bayesian networks are a type of probabilistic graphical model that uses Bayesian inference for probability computations. Bayesian networks aim to model conditional dependence, and therefore causation, by representing conditional dependence by edges in a directed graph. Through these relationships, one can efficiently conduct inference on the random variables in the graph through the use of factors.
As Bayes nets represent data as a probabilistic graph, it is very easy to use that structure to simulate new data that demonstrate the realistic patterns of the underlying causal system. Daniel’s post shows how to do this with bnlearn.
Daniel’s example Bayes net
New data is simulated from a Bayes net (see above) by first sampling from each of the root nodes, in this case sex. Then followed by the children conditional on their parent(s) (e.g. sport | sex and hg | sex) until data for all nodes has been drawn. The numbers on the nodes below indicate the sequence in which the data is simulated, noting that rcc is the terminal node.
The original and simulated datasets are compared in a couple of ways 1) observing the distributions of the variables 2) comparing the output from various models and 3) comparing conditional probability queries. The third test is more of a sanity check. If the data is generated from the original Bayes net then a new one fit on the simulated data should be approximately the same. The more rows we generate the closer the parameters will be to the original values.
The original data alongside the generated data in Daniel’s example
As you can see, a Bayesian network allows you to generate data that looks, feels, and behaves a lot like the data on which you based your network on in the first place.
This can be super useful if you want to generate a synthetic / fake / artificial dataset without sharing personal or sensitive data.
Moreover, the underlying Bayesian net can be very useful to compute missing values. In Daniel’s example, he left out some values on purpose (pretending they were missing) and imputed them with the Bayes net. He found that the imputed values for the missing data points were quite close to the original ones:
For two variables, the original values plotted against the imputed replacements.
In the original blog, Daniel goes on to show how to further check the integrity of the simulated data using statistical models and shares all his code so you can try this out yourself. Please do give his website a visit as Daniel has many more interesting statistics blogs!
Sometimes I find these AI / programming hobby projects that I just wished I had thought of…
Will Stedden combined OpenAI’s GPT-2 deep learning text generation model with another deep-learning language model by Google called BERT (Bidirectional Encoder Representations from Transformers) and created an elaborate architecture that had one purpose: posting the best replies on Reddit.
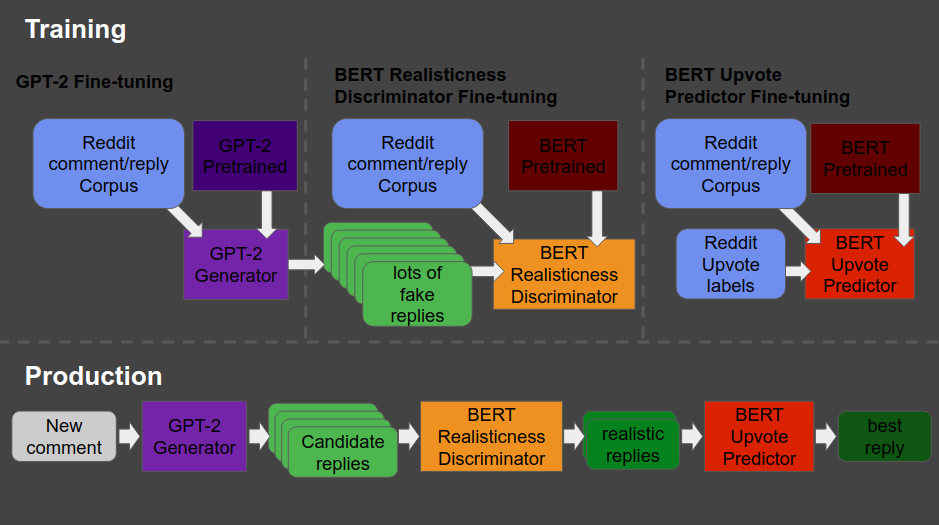
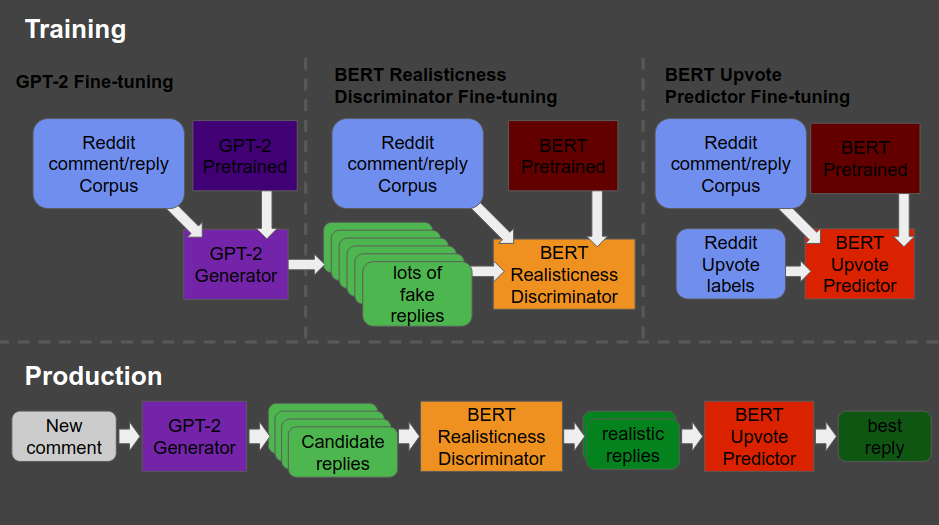
The architecture is shown at the end of this post — copied from Will’s original bloghere. Moreover, you can read this post for details regarding the construction of the system. But let me see whether I can explain you what it does in simple language.
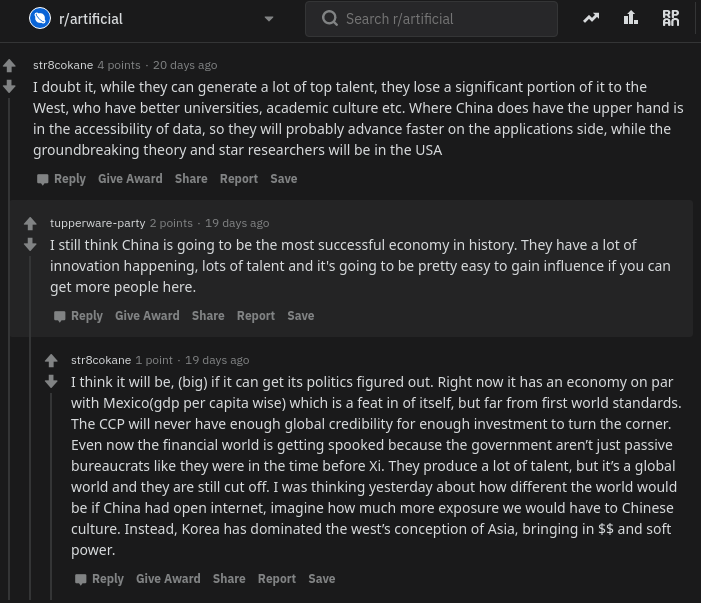
The below is what a Reddit comment and reply thread looks like. We have str8cokane making a comment to an original post (not in the picture), and then tupperware-party making a reply to that comment, followed by another reply by str8cokane. Basically, Will wanted to create an AI/bot that could write replies like tupperware-party that real people like str8cokane would not be able to distinguish from “real-people” replies.
Note that with 4 points, str8cokane‘s original comments was “liked” more than tupperware-party‘s reply and str8cokane‘s next reply, which were only upvoted 2 and 1 times respectively.
So here’s what the final architecture looks like, and my attempt to explain it to you.
Basically, we start in the upper left corner, where Will uses a database (i.e. corpus) of Reddit comments and replies to fine-tune a standard, pretrained GPT-2 model to get it to be good at generating (red: “fake”) realistic Reddit replies.
Next, in the upper middle section, these fake replies are piped into a standard, pretrained BERT model, along with the original, real Reddit comments and replies. This way the BERT model sees both real and fake comments and replies. Now, our goal is to make replies that are undistinguishable from real replies. Hence, this is the task the BERT model gets. And we keep fine-tuning the original GPT-2 generator until the BERT discriminator that follows is no longer able to distinguish fake from real replies. Then the generator is “fooling” the discriminator, and we know we are generating fake replies that look like real ones! You can find more information about such generative adversarial networks here.
Next, in the top right corner, we fine-tune another BERT model. This time we give it the original Reddit comments and replies along with the amount of times they were upvoted (i.e. sort of like likes on facebook/twitter). Basically, we train a BERT model to predict for a given reply, how much likes it is going to get.
Finally, we can go to production in the lower lane. We give a real-life comment to the GPT-2 generator we trained in the upper left corner, which produces several fake replies for us. These candidates we run through the BERT discriminator we trained in the upper middle section, which determined which of the fake replies we generated look most real. Those fake but realistic replies are then input into our trained BERT model of the top right corner, which predicts for every fake but realistic reply the amount of likes/upvotes it is going to get. Finally, we pick and reply with the fake but realistic reply that is predicted to get the most upvotes!
What Will’s final architecture, combining GPT-2 and BERT, looked like (via bonkerfield.org)
The results are astonishing! Will’s bot sounds like a real youngster internet troll! Do have a look at the original blog, but here are some examples. Note that tupperware-party — the Reddit user from the above example — is actually Will’s AI.
Will ends his blog with a link to the tutorial if you want to build such a bot yourself. Have a try!
Moreover, he also notes the ethical concerns:
I know there are definitely some ethical considerations when creating something like this. The reason I’m presenting it is because I actually think it is better for more people to know about and be able to grapple with this kind of technology. If just a few people know about the capacity of these machines, then it is more likely that those small groups of people can abuse their advantage.
I also think that this technology is going to change the way we think about what’s important about being human. After all, if a computer can effectively automate the paper-pushing jobs we’ve constructed and all the bullshit we create on the internet to distract us, then maybe it’ll be time for us to move on to something more meaningful.
If you think what I’ve done is a problem feel free to email me , or publically shame me on Twitter.
Most data scientists favor Python as a programming language these days. However, there’s also still a large group of data scientists coming from a statistics, econometrics, or social science and therefore favoring R, the programming language they learned in university. Now there’s a new kid on the block: Julia.
According to some, you can think of Julia as a mixture of R and Python, but faster. As a programming language for data science, Julia has some major advantages:
Julia is light-weight and efficient and will run on the tiniest of computers
Julia is just-in-time (JIT) compiled, and can approach or match the speed of C
Julia is a functional language at its core
Julia support metaprogramming: Julia programs can generate other Julia programs
Julia has a math-friendly syntax
Julia has refined parallelization compared to other data science languages
Julia can call C, Fortran, Python or R packages
However, others also argue that Julia comes with some disadvantages for data science, like data frame printing, 1-indexing, and its external package management.
Comparing Julia to Python and R
Open Risk Manual published this side-by-side review of the main open source Data Science languages: Julia, Python, R.
You can click the links below to jump directly to the section you’re interested in. Once there, you can compare the packages and functions that allow you to perform Data Science tasks in the three languages.
Here’s a very well written Medium article that guides you through installing Julia and starting with some simple Data Science tasks. At least, Julia’s plots look like:
Tait Brown was annoyed at the Victoria Police who had spent $86 million Australian dollars on developing the BlueNet system which basically consists of an license-plate OCR which crosschecks against a car theft database.
Tait was so disgruntled as he thought he could easily replicate this system without spending millions and millions of tax dollars. And so he did. In only 57 lines of JavaScript, though, to be honest, there are many more lines of code hidden away in abstraction and APIs…
Anyway, he built a system that can identify license plates, read them, and should be able to cross check them with a criminal database.