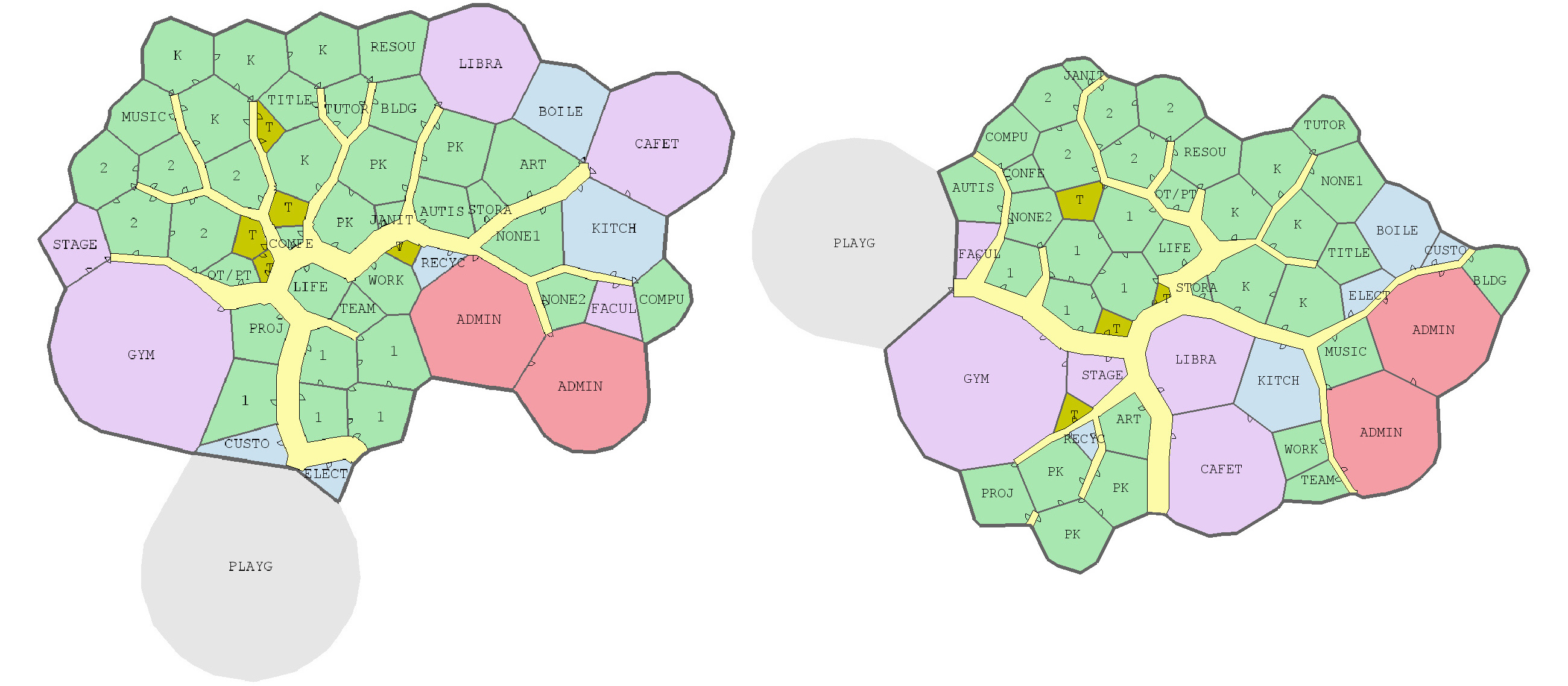
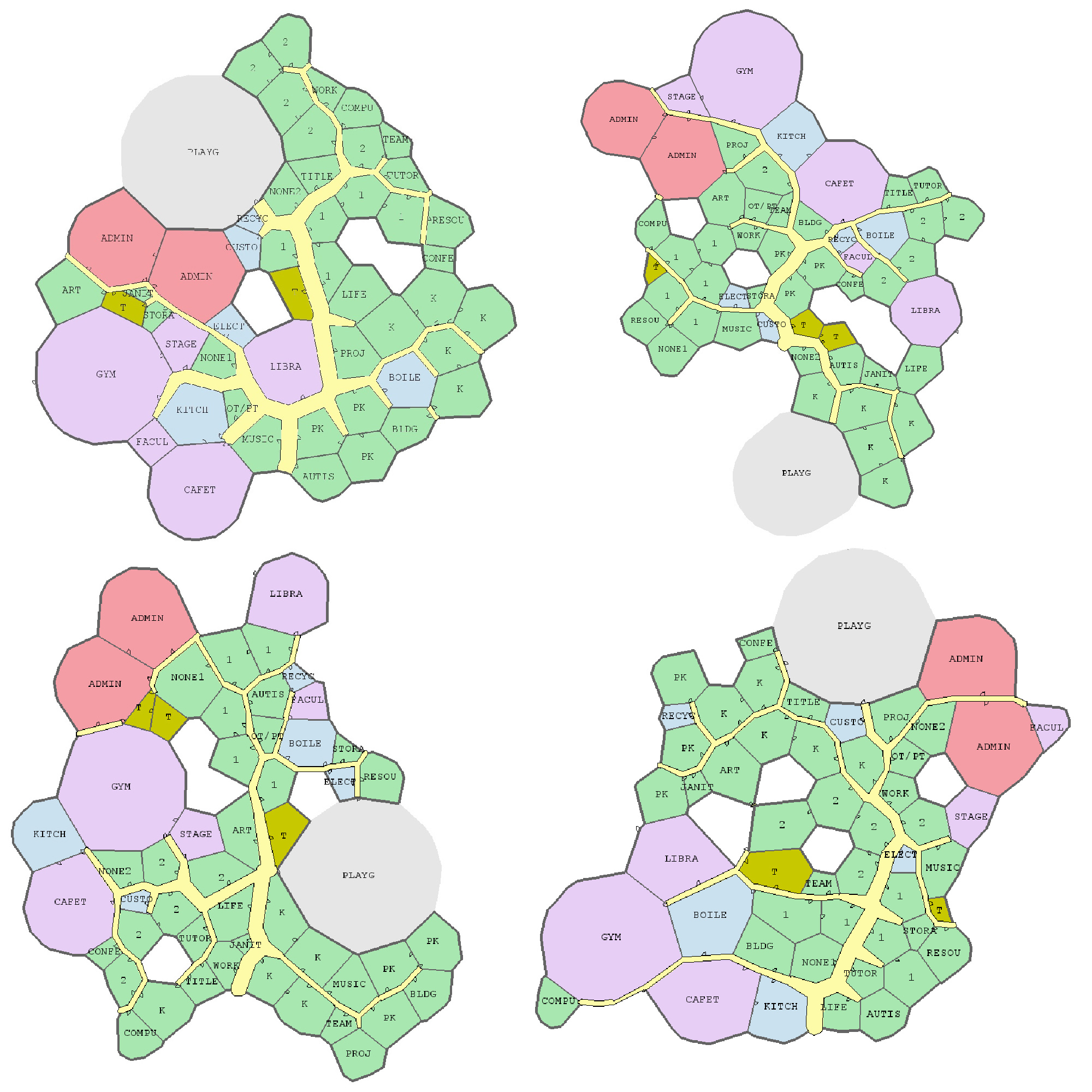
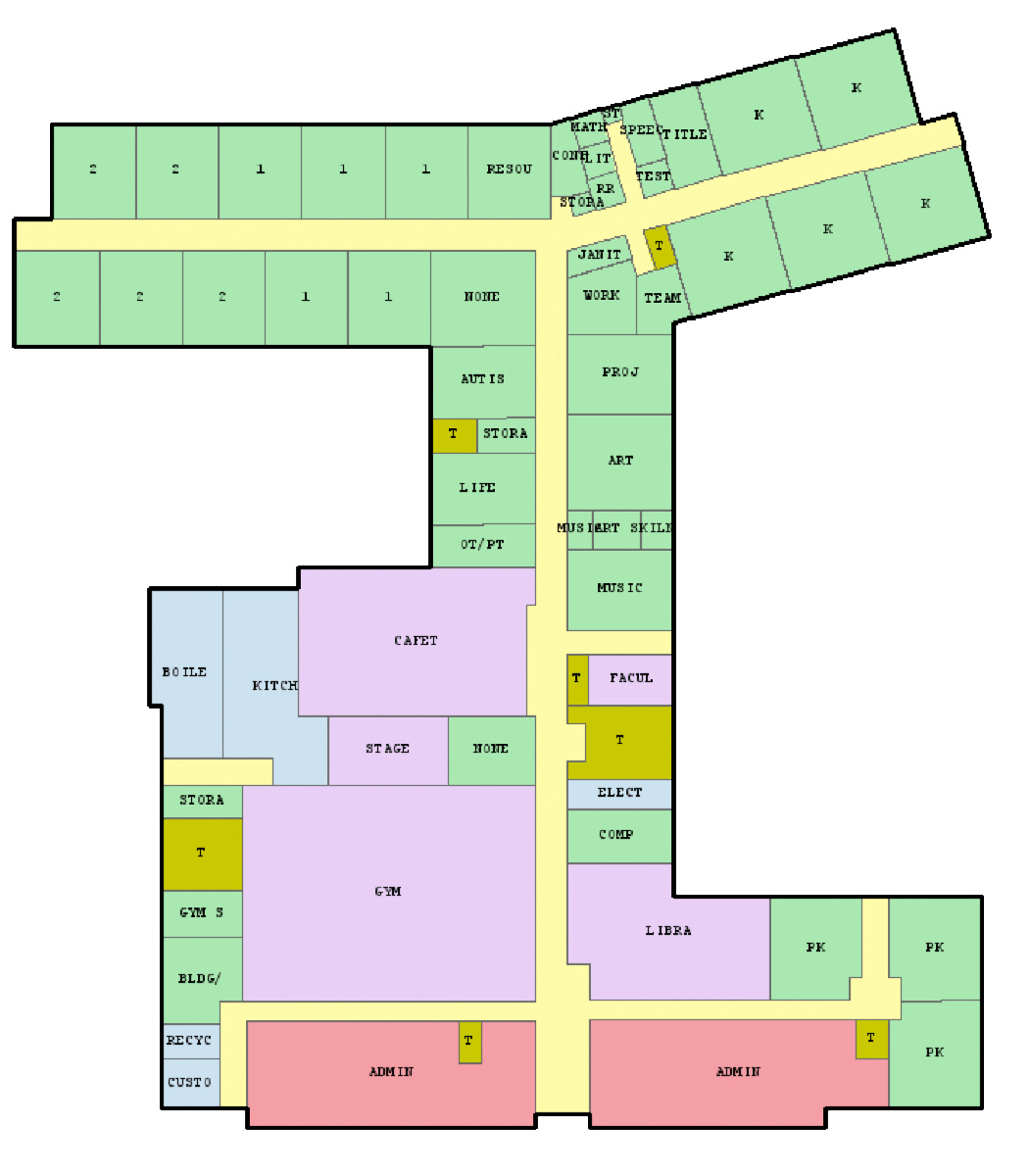
Joel Simon is the genius behind an experimental project exploring optimized school blueprints. Joel used graph-contraction and ant-colony pathing algorithms as growth processes, which could generate elementary school designs optimized for all kinds of characteristics: walking time, hallway usage, outdoor views, and escape routes just to name a few.
Two generated designs, minimizing the traffic flow (left) as well as escape routes (right) [original]Other designs tried to maximize the number of windows, resulting in seemingly random open courtyards [original]
The original floor plan [original]Definitely check out the original write-up if you are interested in the details behind the generation process! Or have a look at some of Joel’s other projects.
Zack Nado wrote the best machine learning application I’ve seen so far: a neural network architecture that generates new Pusheen pictures.
This is an orginal Pusheen picture.
In his blog, Zack describes his generative adversarial network (GAN) , a special type of machine learning architecture where two neural networks try to fool each other. Zack first gave the discriminator network some real Pusheen images, so it gets an idea of what Pusheen looks like. Next, the generator network gets a bunch of random numbers so it can generate completely new (fake) images. These generated images are then fed back into the discriminator, so it knows what generated images look like. Zack repeated this process several hundred thousand times, so he obtained a generator network that’s great at making new Pusheen images which the discriminator (nearly) can’t dinstinguish from the original, real ones. Below is the learning process of the generator network visualized:
Samples output by the generator network. It learns distinctive features of “real” Pusheen (e.g., tail, eyes, ears) over time [original]
In the end, the generated images are very much like the real Pusheen. Zack added an interactive module (using Tensorflow.js) to the blog so you can generate some Pusheens yourself. (it didn’t work for me though…) On a final note, Zack wrote the orginal blog both in plain English, for non-experts, and in jargon, for the more experienced data scientists. I highly recommend you read either one of those versions!
Some of the Pusheen’s generated by Zack’s GAN [original]
The field of computer vision tries to replicate our human visual capabilities, allowing computers to perceive their environment in a same way as you and I do. The recent breakthroughs in this field are super exciting and I couldn’t but share them with you.
In the TED talk below by Joseph Redmon (PhD at the University of Washington) showcases the latest progressions in computer vision resulting, among others, from his open-source research on Darknet – neural network applications in C. Most impressive is the insane speed with which contemporary algorithms are able to classify objects. Joseph demonstrates this by detecting all kinds of random stuff practically in real-time on his phone! Moreover, you’ve got to love how well the system works: even the ties worn in the audience are classified correctly!
The second talk, below, is more scientific and maybe even a bit dry at the start. Blaise Aguera y Arcas (engineer at Google) starts with a historic overview brain research but, fortunately, this serves a cause, as ~6 minutes in Blaise provides one of the best explanations I have yet heard of how a neural network processes images and learns to perceive and classify the underlying patterns. Blaise continues with a similarly great explanation of how this process can be reversed to generate weird, Asher-like images, one could consider creative art:
An example of a reversed neural network thus “estimating” an image of a bird [via Youtube]Blaise’s colleagues at Google took this a step further and used t-SNE to visualize the continuous space of animal concepts as perceived by their neural network, here a zoomed in part on the Armadillo part of the map, apparently closely located to fish, salamanders, and monkeys?
A zoomed view of part of a t-SNE map of latent animal concepts generated by reversing a neural network [via Youtube]We’ve seen these latent spaces/continua before. This example Andrej Karpathy shared immediately comes to mind:
If you want to learn more about this process of image synthesis through deep learning, I can recommend the scientific papers discussed by one of my favorite Youtube-channels, Two-Minute Papers. Karoly’s videos, such as the ones below, discuss many of the latest developments:
Let me know if you have any other video’s, papers, or materials you think are worthwhile!
A Generative Adversarial Network, GAN in short, is a machine learning architecture where two neural networks compete against each other. One of them functions as a discriminator, seeking to optimize its classification of data (i.e., determine whether or not there is a cat in a picture). The other one functions as a generator, seeking to best generate new data to fool the discriminator (i.e., create realistic fake images of cats). Over time, the generator network will become increasingly good at simulating realistic data and being able to mimic real-life.
The concept of GAN was introduced by Ian Goodfellow in 2014, whom we know from the Machine Learning & Deep Learning book. Although GANs are computationally heavy and still undergoing major development, their potential implications are widespread. We can see these architectures taking over all sort of creative work, where generating new “data” is the main task. Think for instance of designing clothes, creating video footage, writing novels, animating movies, or even whole video games. One of my favorite Youtube channels discusses multiple of its recent applications, and here are a few of my favorites:
If you want to try out these GANs yourself but do not have the programming experience: Reiichiro Nakano made a GAN playground in (what seems) JavaScript, where you can play around with the discriminator and the generator to create an adversarial network that identifies and generates images of numbers.
The Deep Learning textbook helps students and practitioners enter the field of machine learning in general and deep learning in particular. Its online version is available online for free whereas a hardcover copy can be ordered here on Amazon. You can click on the topics below to be redirected to the book chapter:
A while ago, I blogged about this new algorithm, pix2code, which takes in pictures of graphical user interfaces and outputs the underlying code. Today, I discovered another fantastic algorithm, by Scott Reed and his colleagues at Google Deepmind. txt2pix would be a catchy name for this algorithm, as it can take in a fairly complex sentence (e.g., “a grey bird with a black head, orange eyes, and a yellow beak“) and generate a completely new and unique image based on its content. In their recently published paper, they elaborate on the algorithms inner workings.
An example of the training and generation process reported in the paper
Scott and his team have been working on this project for quite some time. The early version of the algorithm generated an image one pixel at a time, but it had difficulties generating large or high-quality images. After picking a starting pixel to generate, any consecutively generated pixel the algorithm generates needs to align with its neighbours. For example, if pixel A is the first pixel in the generation of the yellow beak of a bird, any pixels that are created in the neighbourhood of that pixel should take into account that pixel A is trying to visualize a yellow beak, and behave accordingly: either continuing the beak, or ending the beak and starting on another element of the image.
The problem with such an iterative approach (i.e., pixel by pixel) is that it can take a very long time for a computer to generate an image. Considering that a fairly small image, say 256 by 256 pixels, already contains 65.536 pixels, each of which needs to be generated while considering all its neighbours and keeping in mind the bigger picture. In the most recent, updated version of the algorithm, Scott and his team have allowed the generation of multiple unrelated pixels simultaneously at different ‘zones’ of the image. Hence the Parallel in Parallel Multiscale Autoregressive Density Estimation. With this parallel approach, the algorithm can now generate the pixels representing the yellow beak in one area of the image, while simultaneously generating pixels for the bird’s wings and the branch it’s sitting on at different sections of the image. This speeds up the process quite extensively, demanding less computation time, thus allowing for quicker image generation.
If you want to know more details behind the algorithm but do not fancy reading the entire paper, I recommend this short explanation video by Károly Zsolnai-Fehér (what a name!) of Two Minute papers: