Google Brain researchers published this amazing paper, with accompanying GIF where they show the true power of AutoML.
AutoML stands for automated machine learning, and basically refers to an algorithm autonomously building the best machine learning model for a given problem.
This task of selecting the best ML model is difficult as it is. There are many different ML algorithms to choose from, and each of these has many different settings ([hyper]parameters) you can change to optimalize the model’s predictions.
For instance, let’s look at one specific ML algorithm: the neural network. Not only can we try out millions of different neural network architectures (ways in which the nodes and lyers of a network are connected), but each of these we can test with different loss functions, learning rates, dropout rates, et cetera. And this is only one algorithm!
In their new paper, the Google Brain scholars display how they managed to automatically discover complete machine learning algorithms just using basic mathematical operations as building blocks. Using evolutionary principles, they have developed an AutoML framework that tailors its own algorithms and architectures to best fit the data and problem at hand.
This is AI research at its finest, and the results are truly remarkable!
Sometimes I find these AI / programming hobby projects that I just wished I had thought of…
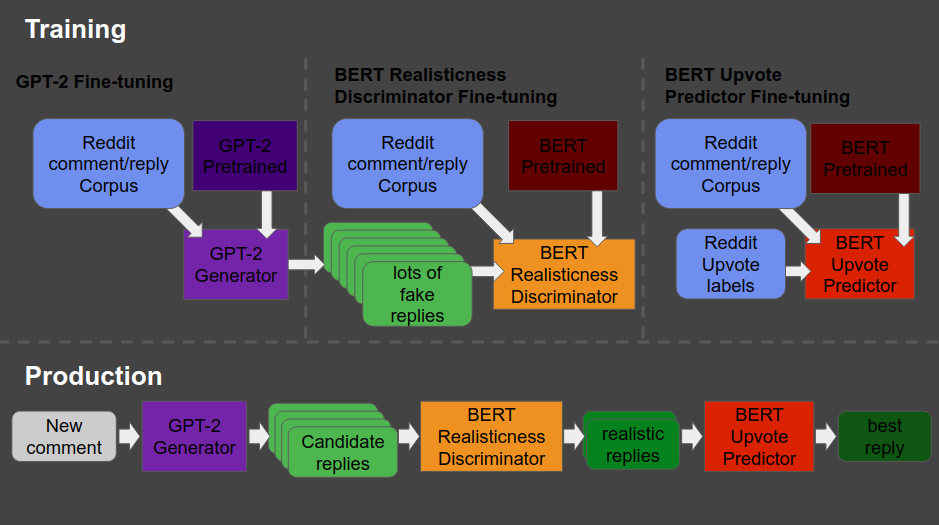
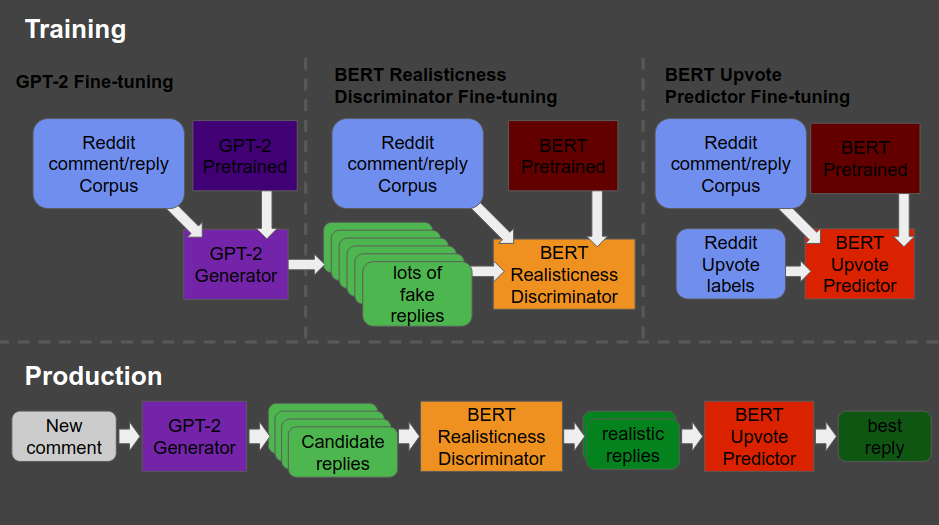
Will Stedden combined OpenAI’s GPT-2 deep learning text generation model with another deep-learning language model by Google called BERT (Bidirectional Encoder Representations from Transformers) and created an elaborate architecture that had one purpose: posting the best replies on Reddit.
The architecture is shown at the end of this post — copied from Will’s original bloghere. Moreover, you can read this post for details regarding the construction of the system. But let me see whether I can explain you what it does in simple language.
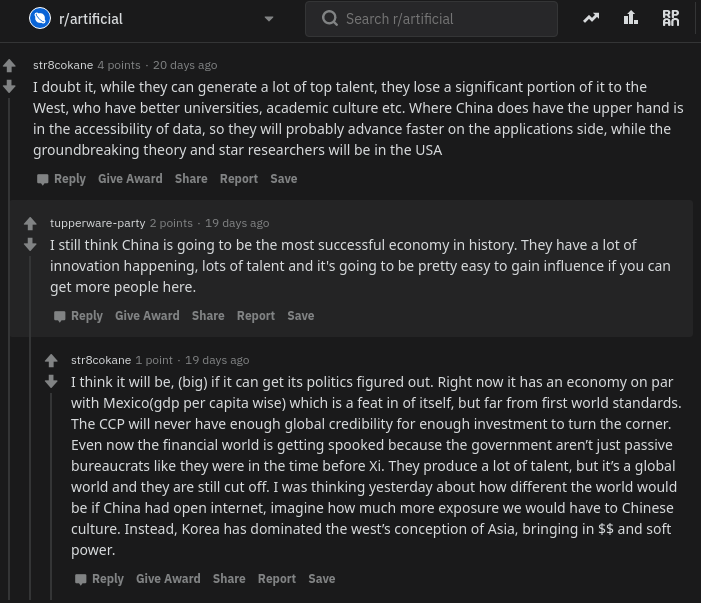
The below is what a Reddit comment and reply thread looks like. We have str8cokane making a comment to an original post (not in the picture), and then tupperware-party making a reply to that comment, followed by another reply by str8cokane. Basically, Will wanted to create an AI/bot that could write replies like tupperware-party that real people like str8cokane would not be able to distinguish from “real-people” replies.
Note that with 4 points, str8cokane‘s original comments was “liked” more than tupperware-party‘s reply and str8cokane‘s next reply, which were only upvoted 2 and 1 times respectively.
So here’s what the final architecture looks like, and my attempt to explain it to you.
Basically, we start in the upper left corner, where Will uses a database (i.e. corpus) of Reddit comments and replies to fine-tune a standard, pretrained GPT-2 model to get it to be good at generating (red: “fake”) realistic Reddit replies.
Next, in the upper middle section, these fake replies are piped into a standard, pretrained BERT model, along with the original, real Reddit comments and replies. This way the BERT model sees both real and fake comments and replies. Now, our goal is to make replies that are undistinguishable from real replies. Hence, this is the task the BERT model gets. And we keep fine-tuning the original GPT-2 generator until the BERT discriminator that follows is no longer able to distinguish fake from real replies. Then the generator is “fooling” the discriminator, and we know we are generating fake replies that look like real ones! You can find more information about such generative adversarial networks here.
Next, in the top right corner, we fine-tune another BERT model. This time we give it the original Reddit comments and replies along with the amount of times they were upvoted (i.e. sort of like likes on facebook/twitter). Basically, we train a BERT model to predict for a given reply, how much likes it is going to get.
Finally, we can go to production in the lower lane. We give a real-life comment to the GPT-2 generator we trained in the upper left corner, which produces several fake replies for us. These candidates we run through the BERT discriminator we trained in the upper middle section, which determined which of the fake replies we generated look most real. Those fake but realistic replies are then input into our trained BERT model of the top right corner, which predicts for every fake but realistic reply the amount of likes/upvotes it is going to get. Finally, we pick and reply with the fake but realistic reply that is predicted to get the most upvotes!
What Will’s final architecture, combining GPT-2 and BERT, looked like (via bonkerfield.org)
The results are astonishing! Will’s bot sounds like a real youngster internet troll! Do have a look at the original blog, but here are some examples. Note that tupperware-party — the Reddit user from the above example — is actually Will’s AI.
Will ends his blog with a link to the tutorial if you want to build such a bot yourself. Have a try!
Moreover, he also notes the ethical concerns:
I know there are definitely some ethical considerations when creating something like this. The reason I’m presenting it is because I actually think it is better for more people to know about and be able to grapple with this kind of technology. If just a few people know about the capacity of these machines, then it is more likely that those small groups of people can abuse their advantage.
I also think that this technology is going to change the way we think about what’s important about being human. After all, if a computer can effectively automate the paper-pushing jobs we’ve constructed and all the bullshit we create on the internet to distract us, then maybe it’ll be time for us to move on to something more meaningful.
If you think what I’ve done is a problem feel free to email me , or publically shame me on Twitter.
Finland developed a crash course on AI to educate its citizens. The course was arguably a great local success, with over 50 thousand Fins taking the course (1% of the population).
Now, as a gift to the European Union, Finland has opened up the course for the rest of Europe and the world to enjoy.
All pictures are screenshots taken from the website
The course is even being translated into several local languages. At the time of writing, five Northern European languages are already supported, but additional translation efforts are still in progress.
Elements of AI takes six weeks and functions as a crash course and beginner introduction to the field of AI:
Came across this awesome Youtube video that blew my mind. Definitely a handy resource if you want to explain the inner workings of neural networks. Have a look!
PyData is famous for it’s great talks on machine learning topics. This 2019 London edition, Vincent Warmerdamagain managed to give a super inspiring presentation. This year he covers what he dubs Artificial Stupidity™. You should definitely watch the talk, which includes some great visual aids, but here are my main takeaways:
Vincent speaks of Artificial Stupidity, of machine learning gone HorriblyWrong™ — an example of which below — for which Vincent elaborates on three potential fixes:
Example of a model that goes HorriblyWrong™, according to Vincent’s talk.
1. Predict Less, but Carefully
Vincent argues you shouldn’t extrapolate your predictions outside of your observed sampling space. Even better: “Not predicting given uncertainty is a great idea.” As an alternative, we could for instance design a fallback mechanism, by including an outlier detection model as the first step of your machine learning model pipeline and only predict for non-outliers.
I definately recommend you watch this specific section of Vincent’s talk because he gives some very visual and intuitive explanations of how extrapolation may go HorriblyWrong™.
Be careful! One thing we should maybe start talking about to our bosses: Algorithms merely automate, approximate, and interpolate. It’s the extrapolation that is actually kind of dangerous.
Vincent Warmerdam @ Pydata 2019 London
Basically, we can choose to not make automated decisions sometimes.
2. Constrain thy Features
What we feed to our models really matters. […] You should probably do something to the data going into your model if you want your model to have any sort of fairness garantuees.
Vincent Warmerdam @ Pydata 2019 London
Often, simply removing biased features from your data does not reduce bias to the extent we may have hoped. Fortunately, Vincent demonstrates how to remove biased information from your variables by applying some cool math tricks.
Unfortunately, doing so will often result in a lesser predictive accuracy. Unsurprisingly though, as you are not closely fitting the biased data any more. What makes matters more problematic, Vincent rightfully mentions, is that corporate incentives often not really align here. It might feel that you need to pick: it’s either more accuracy or it’s more fairness.
However, there’s a nice solution that builds on point 1. We can now take the highly accurate model and the highly fair model, make predictions with both, and when these predictions differ, that’s a very good proxy where you potentially don’t want to make a prediction. Hence, there may be observations/samples where we are comfortable in making a fair prediction, whereas in most other situations we may say “right, this prediction seems unfair, we need a fallback mechanism, a human being should look at this and we should not automate this decision”.
Vincent does not that this is only one trick to constrain your model for fairness, and that fairness may often only be fair in the eyes of the beholder. Moreover, in order to correct for these biases and unfairness, you need to know about these unfair biases. Although outside of the scope of this specific topic, Vincent proposes this introduces new ethical issues:
Basically, we can choose to put our models on a controlled diet.
3. Constrain thy Model
Vincent argues that we should include constraints (based on domain knowledge, or common sense) into our models. In his presentation, he names a few. For instance, monotonicity, which implies that the relationship between X and Y should always be either entirely non-increasing, or entirely non-decreasing. Incorporating the previously discussed fairness principles would be a second example, and there are many more.
If we every come up with a model where more smoking leads to better health, that’s bad. I have enough domain knowledge to say that that should never happen. So maybe I should just make a system where I can say “look this one column with relationship to Y should always be strictly negative”.
Vincent Warmerdam @ Pydata 2019 London
Basically, we can integrate domain knowledge or preferences into our models.
Survival of the Best Fit was built by Gabor Csapo, Jihyun Kim, Miha Klasinc, and Alia ElKattan. They are software engineers, designers and technologists, advocating for better software that allows members of the public to question its impact on society.
You don’t need to be an engineer to question how technology is affecting our lives. The goal is not for everyone to be a data scientist or machine learning engineer, though the field can certainly use more diversity, but to have enough awareness to join the conversation and ask important questions.
With Survival of the Best Fit, we want to reach an audience that may not be the makers of the very technology that impact them everyday. We want to help them better understand how AI works and how it may affect them, so that they can better demand transparency and accountability in systems that make more and more decisions for us.
I found that the game provides a great intuitive explanation of how (humas) bias can slip into A.I. or machine learning applications in recruitment, selection, or other human resource management practices and processes.
Note, as Joachin replied below, that the game apparently does not learn from user-input, but is programmed to always result in bias towards blues. I kind of hoped that there was actually an algorithm “learning” in the backend, and while the developers could argue that the bias arises from the added external training data (you picked either Google, Apple, or Amazon to learn from), it feels like a bit of a disappointment that there is no real interactivity here.