Apparently, I was not the only geek who decided to celebrate the 20th anniversary of the Harry Potter saga with statistical analysis. Students Moritz Haine and Markus Dienstknecht of the Data Science for Decision Making Master at Maastricht University started their own celebratory project as part of a course Information Retrieval and Text Mining.
Students in previous years looked at for example Lord of the Rings, Star Wars and Game of Thrones. However, to our surprise, Harry Potter was missing. Since the books are about magic, we decided it would be interesting to identify all of the spells and the wizards that cast the most spells
Moritz Haine
From the books, the students extracted 41 different wizards, 64 different spells and 253 spells. Moritz points out that they could only include spoken spells, even though the most powerful wizards can also cast spells without naming them. They expect this might be the reason why Dumbledore and Voldemort are not ranked as high. At the end of their project, Moritz and Markus visualized their results in a spell-character mapping.
A network mapping of the characters and spells casted in the Harry Potter saga [original]This is the latest addition to my collection of Harry Potter analyses, to which a similar, interactive web application of spell usage was added only last week.
I would like to demonstrate how regular expressions can be used to retrieve (sub)strings that follow a specific format. We could use regex to examine, for instance, when, and by whom, which magical spells are cast.
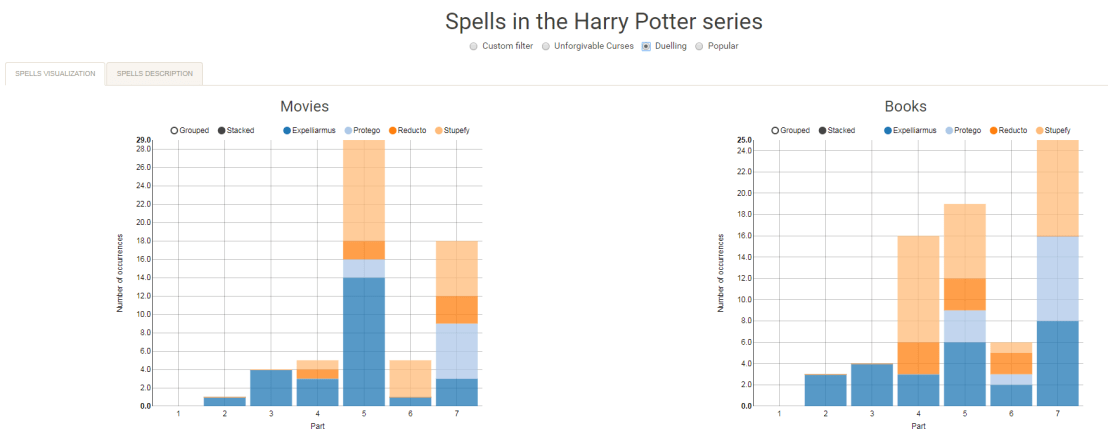
Well, Prusinowskik (real name unknown) beat me to it, and how! S/He formed a comprehensive list of all spells found in the Harry Potter saga (see below), and categorized these into “spells“, “charms“, and “curses“, and into “popular“, “dueling” and “unforgivable” purposes. Next, Prusinowskik built an interactive Shiny application with lovely JavaScript graphs (package: rCharts) for us to discover precisely when during the saga which spells are cast (see also below). Moreover, the analysis was repeated for both the books and the movies.
Truly excellent work Prusinowskik! The Shiny app can be found here.
Sentiment analysis is a topic I cover regularly, for instance, with regard to Harry Plotter, Stranger Things, or Facebook. Usually I stick to the three sentiment dictionaries (i.e., lexicons) included in the tidytext R package (Bing, NRC, and AFINN) but there are many more one could use. Heck, I’ve even tried building one myself using a synonym/antonym network (unsuccessful, though a nice challenge). Two lexicons that did become famous are SentiWordNet, accessible via the lexicon R package, and the Loughran lexicon, designed specifically for the analysis of shareholder reports.
Josh Yazman did the world a favor and compared the quality of the five lexicons mentioned above. He observed their validity in relation to the millions of restaurant reviews in the Yelp dataset. This dataset includes both textual reviews and 1 to 5 star ratings. Here’s a summary of Josh’s findings, including two visualizations (read Josh’s full blog + details here):
NRC overestimates the positive sentiment.
AFINN also provides overly positive estimates, but to a lesser extent.
Loughran seems unreliable altogether (on Yelp data).
Bing estimates are accurate as long as texts are long enough (e.g., 200+ words).
SentiWordNet‘s estimates are mostly valid and precise, also on shorter texts, but may include minor outliers.
Sentiment scores by Yelp rating, estimated using each lexicon. [original]The average sentiment score estimated using lexicons, where words are randomly sampled from the Yelp dataset. Note that, although both NRC and Bing scores are relatively positive on average, they also demonstrate a larger spread of scores (which is a good thing if you assume that reviews vary in terms of sentiment). [original]On a more detailed level, David Robinson demonstrated how to uncover performance errors or quality issues in lexicons, in his 2016 blog on the AFINN lexicon. Using only the most common words (i.e., used in 200+ reviews for at least 10 businesses) of the same Yelp dataset, David visualized the inconsistencies between the AFINN sentiment lexicon and the Yelp ratings in two very smart and appealing ways:
Words’ AFINN sentiment score by the average rating of the reviews they used in [original]As the figure above shows, David found a strong positive correlations between the sentiment score assigned to words in the AFINN lexicon and the way they are used in Yelp reviews. However, there are some exception – words that did not have the same meaning in the lexicon and the observed data. Examples of words that seem to cause errors are die and bomb (both negative AFINN scores but used in positive Yelp reviews) or, the other way around, joke and honor (positive AFINN scores but negative meanings on Yelp).
A graph of the frequency with which words are used in reviews, by the average rating of the reviews they occur in, colored for their AFINN sentiment score [original]With the graph above, it is easy to see what words cause inaccuracies. Blue words should be in the upper section of this visual while reds should be closer to the bottom. If this is not the case, a word likely has a different meaning in the lexicon respective to how it’s used on Yelp. These lexicon-data differences become increasingly important as words are located closer to the right side of the graph, which means they more frequently screw up your sentiment estimates. For instance, fine, joke, fuck and hopecause much overestimation of positive sentiment while fresh is not considered in the positive scores it entails and die causes many negative errors.
TL;DR: Sentiment lexicons vary in terms of their quality/performance. If your texts are short (few hundred words) you might be best off using Bing (tidytext). In other cases, opt for SentiWordNet (lexicon), which considers a broader vocabulary. If possible, try to evaluate inaccuracies, outliers, and/or prediction errors via data visualizations.
Jordan Dworkin, a Biostatistics PhD student at the University of Pennsylvania, is one of the few million fans of Stranger Things, a 80s-themed Netflix series combining drama, fantasy, mystery, and horror. Awaiting the third season, Jordan was curious as to the emotional voyage viewers went through during the series, and he decided to examine this using a statistical approach. Like I did for the seven Harry Plotter books, Jordan downloaded the scripts of all the Stranger Things episodes and conducted a sentiment analysis in R, of course using the tidyverse and tidytext. Jordan measured the positive or negative sentiment of the words in them using the AFINN dictionary and a first exploration led Jordan to visualize these average sentiment scores per episode:
The average positive/negative sentiment during the 17 episodes of the first two seasons of Stranger Things (from Medium.com)
Jordan jokingly explains that you might expect such overly negative sentiment in show about missing children and inter-dimensional monsters. The less-than-well-received episode 15 stands out, Jordan feels this may be due to a combination of its dark plot and the lack of any comedic relief from the main characters.
Reflecting on the visual above, Jordan felt that a lot of the granularity of the actual sentiment was missing. For a next analysis, he thus calculated a rolling average sentiment during the course of the separate episodes, which he animated using the animation package:
GIF displaying the rolling average (40 words) sentiment per Stranger Things episode (from Medium.com)
Jordan has two new takeaways: (1) only 3 of the 17 episodes have a positive ending – the Season 1 finale, the Season 2 premiere, and the Season 2 finale – (2) the episodes do not follow a clear emotional pattern. Based on this second finding, Jordan subsequently compared the average emotional trajectories of the two seasons, but the difference was not significant:
Smoothed (loess, I guess) trajectories of the sentiment during the episodes in seasons one and two of Stranger Things (from Medium.com)
Potentially, it’s better to classify the episodes based on their emotional trajectory than on the season they below too, Jordan thought next. Hence, he constructed a network based on the similarity (temporal correlation) between episodes’ temporal sentiment scores. In this network, the episodes are the nodes whereas the edges are weighted for the similarity of their emotional trajectories. In that sense, more distant episodes are less similar in terms of their emotional trajectory. The network below, made using igraph (see also here), demonstrates that consecutive episodes (1 → 2, 2 → 3, 3 → 4) are not that much alike:
The network of Stranger Things episodes, where the relations between the episodes are weighted for the similarity of their emotional trajectories (from Medium.com).
Three different emotional trajectories were identified among the 17 Stranger Things episodes in Season 1 and 2 (from Medium.com).
Looking at the average patterns, we can see that group 1 contains episodes that begin and end with neutral emotion and have slow fluctuations in the middle, group 2 contains episodes that begin with negative emotion and gradually climb towards a positive ending, and group 3 contains episodes that begin on a positive note and oscillate downwards towards a darker ending.
Jordan final suggestion is that producers and scriptwriters may consciously introduce these variations in emotional trajectories among consecutive episodes in order to get viewers hooked. If you want to redo the analysis or reuse some of the code used to create the visuals above, you can access Jordan’s R scripts here. I, for one, look forward to his analysis of Season 3!
R users have been using the twitter package by Geoff Jentry to mine tweets for several years now. However, a recent blog suggests a novel package provides a better mining tool: rtweet by Michael Kearney (GitHub).
Both packages use a similar setup and require you to do some prep-work by creating a Twitter “app” (see the package instructions). However, rtweet will save you considerable API-time and post-API munging time. This is demonstrated by the examples below, where Twitter is searched for #rstats-tagged tweets, first using twitteR, then using rtweet.
library(twitteR)# this relies on you setting up an app in apps.twitter.com
setup_twitter_oauth(
consumer_key = Sys.getenv("TWITTER_CONSUMER_KEY"),
consumer_secret = Sys.getenv("TWITTER_CONSUMER_SECRET"))
r_folks <- searchTwitter("#rstats", n=300)
str(r_folks,1)## List of 300## $ :Reference class 'status' [package "twitteR"] with 17 fields## ..and 53 methods, of which 39 are possibly relevant## $ :Reference class 'status' [package "twitteR"] with 17 fields## ..and 53 methods, of which 39 are possibly relevant## $ :Reference class 'status' [package "twitteR"] with 17 fields## ..and 53 methods, of which 39 are possibly relevant
str(r_folks[1])## List of 1## $ :Reference class 'status' [package "twitteR"] with 17 fields## ..$ text : chr "RT @historying: Wow. This is an enormously helpful tutorial by @vivalosburros for anyone interested in mapping "| __truncated__## ..$ favorited : logi FALSE## ..$ favoriteCount: num 0## ..$ replyToSN : chr(0) ## ..$ created : POSIXct[1:1], format: "2017-10-22 17:18:31"## ..$ truncated : logi FALSE## ..$ replyToSID : chr(0) ## ..$ id : chr "922150185916157952"## ..$ replyToUID : chr(0) ## ..$ statusSource : chr "Twitter for Android"## ..$ screenName : chr "jasonrhody"## ..$ retweetCount : num 3## ..$ isRetweet : logi TRUE## ..$ retweeted : logi FALSE## ..$ longitude : chr(0) ## ..$ latitude : chr(0) ## ..$ urls :'data.frame': 0 obs. of 4 variables:## .. ..$ url : chr(0) ## .. ..$ expanded_url: chr(0) ## .. ..$ dispaly_url : chr(0) ## .. ..$ indices : num(0) ## ..and 53 methods, of which 39 are possibly relevant:## .. getCreated, getFavoriteCount, getFavorited, getId, getIsRetweet, getLatitude, getLongitude, getReplyToSID,## .. getReplyToSN, getReplyToUID, getRetweetCount, getRetweeted, getRetweeters, getRetweets, getScreenName,## .. getStatusSource, getText, getTruncated, getUrls, initialize, setCreated, setFavoriteCount, setFavorited, setId,## .. setIsRetweet, setLatitude, setLongitude, setReplyToSID, setReplyToSN, setReplyToUID, setRetweetCount,## .. setRetweeted, setScreenName, setStatusSource, setText, setTruncated, setUrls, toDataFrame, toDataFrame#twitterObj
The above operations required only several seconds to completely. The returned data is definitely usable, but not in the most handy format: the package models the Twitter API on to custom R objects. It’s elegant, but also likely overkill for most operations. Here’s the rtweet version:
This operation took equal to less time but provides the data in a tidy, immediately usable structure.
On the rtweetwebsite, you can read about the additional functionalities this new package provides. For instance,ts_plot() provides a quick visual of the frequency of tweets. It’s possible to aggregate by the minute, i.e., by = "mins", or by some value of seconds, e.g.,by = "15 secs".
## Plot time series of all tweets aggregated by second
ts_plot(rt, by ="secs")
ts_filter() creates a time series-like data structure, which consists of “time” (specific interval of time determined via the by argument), “freq” (the number of observations, or tweets, that fall within the corresponding interval of time), and “filter” (a label representing the filtering rule used to subset the data). If no filter is provided, the returned data object includes a “filter” variable, but all of the entries will be blank "", indicating that no filter filter was used. Otherwise, ts_filter() uses the regular expressions supplied to the filter argument as values for the filter variable. To make the filter labels pretty, users may also provide a character vector using the key parameter.
## plot multiple time series by first filtering the data using
## regular expressions on the tweet "text" variable
rt %>%
dplyr::group_by(screen_name) %>%
## The pipe operator allows you to combine this with ts_plot
## without things getting too messy.
ts_plot() +
ggplot2::labs(
title ="Tweets during election day for the 2016 U.S. election",
subtitle ="Tweets collected, parsed, and plotted using `rtweet`"
)
The developer cautions that these plots often resemble frowny faces: the first and last points appear significantly lower than the rest. This is caused by the first and last intervals of time to be artificially shrunken by connection and disconnection processes. To remedy this, users may specify trim = TRUE to drop the first and last observation for each time series.
Give rtweet a try and let me know whether you prefer it over twitter.
A regular expression (regex or regexp for short) is a special text string for describing a search pattern. You can think of regular expressions as wildcards on steroids. You are probably familiar with wildcard notations such as *.txt to find all text files in a file manager. The regex equivalent is .*\.txt$.
Last week I posted a first tutorial on Regular Expressions in R and I am working its sequels. You may find additional resources on Regular Expressions in the learning overviews (R, Python, Data Science).
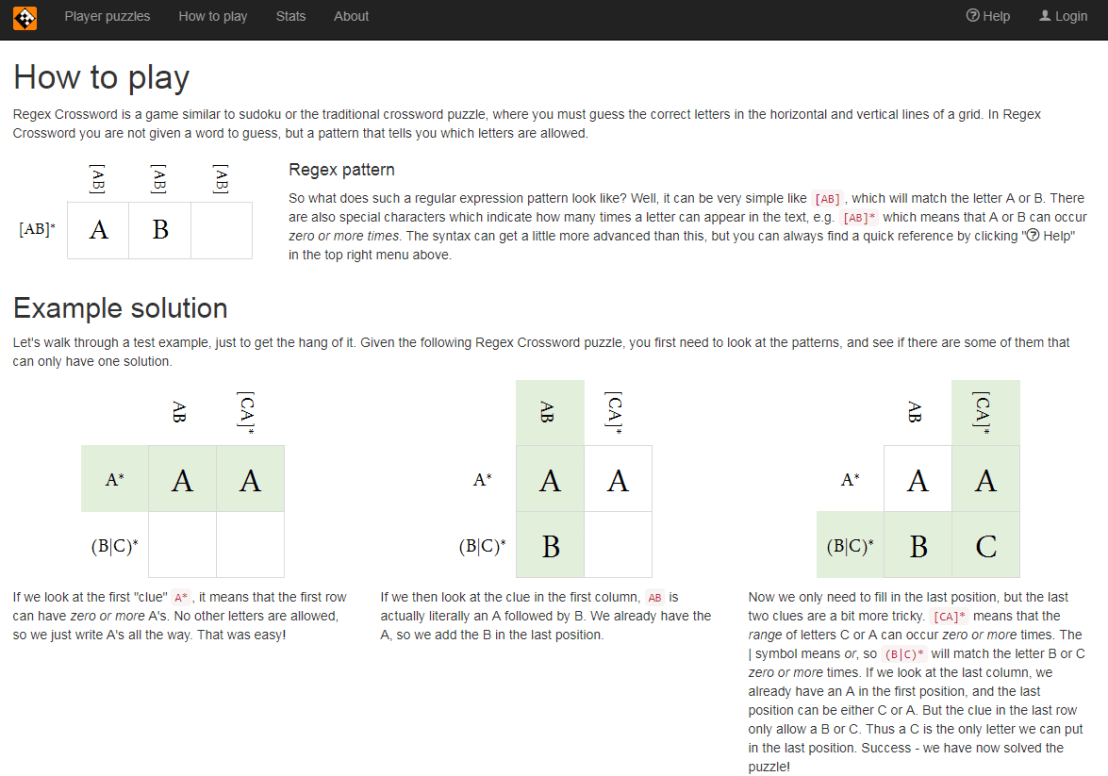
Today I came across this website of Regular Expression Crosswords, which proves a great resource to playfully master regular expression. All puzzles are validated live using the JavaScript regex engine. The figure below explains how it works
Via the links below you can jump puzzles that matches your expertise level: