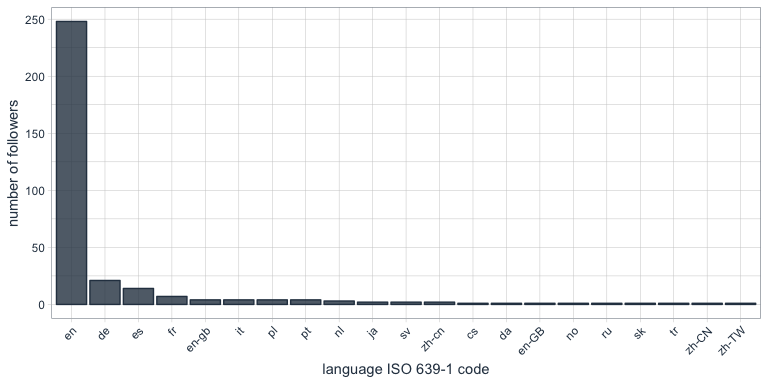
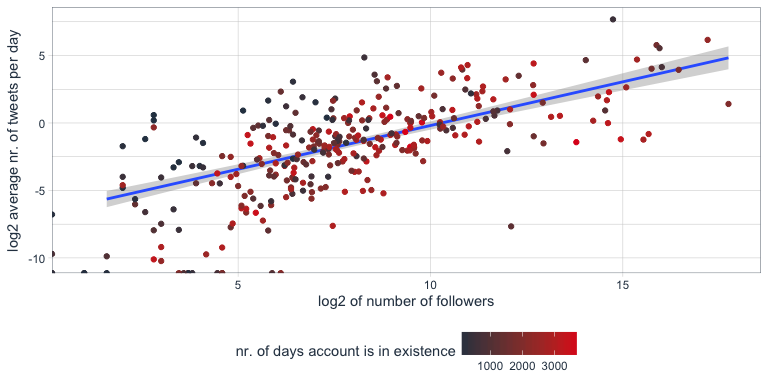
This is a repost of my Linked-In article of January 10th 2017.
The Dutch version of this blog is posted here.
TL;DR // Summary
In order to analyze which of the contestants of a Dutch television game show was suspected of sabotage by public opinion, 10,000+ #WIDM tweets were downloaded and analyzed. Data analysis of this first episode demonstrates how certain contestants increasingly receive public attention whereas others are quickly abandoned. Hopefully, this wisdom-of-the-crowd approach will ultimately demonstrate who is most likely to be this years’ mole. (link to Dutch blog)
A sneak peak:
Introduction
“Wie is de Mol?” [literal translation: ‘Who is the mole?’], or WIDM in short, is a popular Dutch TV game show that has been running for 17 years. The format consists of 10 famous Dutchies (e.g., actors, comedians, novelists) being sent abroad to complete a series of challenging tasks and puzzles, amassing collective prize money along the way.
However, among the contestants is a mole. This saboteur is carefully trained by the WIDM production team beforehand and his/her secret purpose is to prevent the group from collecting any money. Emphasis on secret, as the mole can only operate if unidentified by the other contestants. Furthermore, at the end of each episode, contestants have to complete a test on their knowledge of the identity of the mole. The one whose suspicions are the furthest off is eliminated and sent back to the cold and rainy Netherlands. This process is repeated every episode until in the final episode only three contestants remain: one mole, one losing finalist, and the winner of the series and thus the prize money.
WIDM has a large, active fanbase of so-called ‘molloten‘, which roughly translates to mole-fanatics. Part of its popularity can be attributed to viewers themselves being challenged to uncover the mole before the end of the series. Although the production team assures that most of the sabotage is not shown to the viewer at home, each episode is filled with visual, musical and textual hints. Frequently, viewers come up with wild theories and detect the most bizarre patterns. In recent years, some dedicated fans even go as far as analyzing the contestants’ personal social media feeds in order to determine who was sent home early. A community has developed with multiple online fora, frequent polling of public suspicions, and even a mobile application so you can compare suspicions and compete with friends. Because of all this public effort, the identity of the mole is frequently known before the actual end of the series.
So, why this blog? Well, first off, I have followed the series for several years myself and, to be honest, my suspicions are often quite far off. Secondly, past year, I played around with twitter data analysis and WIDM seemed like a nice opportunity to dust off that R script. Third, I hoped the LinkedIn community might enjoy a step-by-step example of twitter data analysis. The following is the first of, hopefully, a series of blogs in which I try to uncover the mole using the wisdom of the tweeting crowd. I hope you enjoy it as much as I do.
Analysis & Results
To not keep you waiting, let’s start with the analysis and the results right away.
Time of creation
First, let’s examine when the #WIDM tweets were posted. Episode 1 is clearly visible in the data with most of the traffic occurring in a short timeframe on Saturday evening. Note that unfortunately Twitter only allows data to be downloaded nine days back in time.
hist(tweets.df$created, breaks = 50,xlab = 'Day & Time', main = 'Tweets by date')
ggplot(tweets.df) + geom_histogram(aes(created),col = 'black', fill = 'grey') +
labs(x = 'Date & Time', y = 'Frequency', title = '#WIDM tweets over time') +
theme_bw()
ggsave('e1_tweetsovertime_histogram.png')
Hashtags
Next, it seemed wise to examine which other hashtags were being used so that future search queries on WIDM can be more comprehensive.
hashtags <- table(tolower(unlist(str_extract_all(tweets.df$text,'#\\S+\\b'))))
head(sort(hashtags,T),20)
10272 1722 1248 360 91
56 55 50 47 45
30 27 27 24 23
21 20 20 19 18
png('e1_hashtags_wordcloud.png')
wordcloud(names(hashtags),freq = log(hashtags),rot.per = 0)
dev.off()
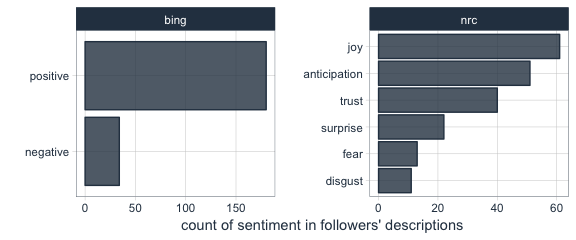
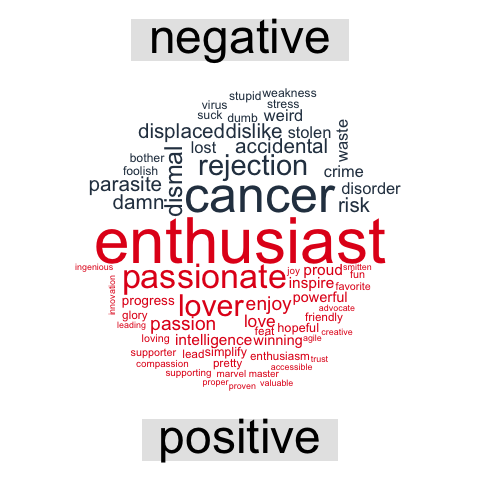
Because the hashtag I queried was obviously overwhelmingly used in the dataset, this wordcloud depicts hashtags’ by their logarithmic frequency.
Curiously, not all tweets had #widm included in their text. Potentially this is caused by regular expressions I used (more on those later) which may have filtered out hashtags such as #widm-poule whereas Twitter may return those when #WIDM is queried.
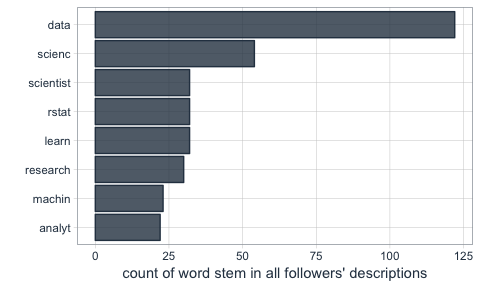
Contestant frequencies
Using for-loops and if-statements, described later in this blog, I retrieved the frequency with which contestants were mentioned in the tweets. I had the data in three different formats and the following consists of a series of visualizations of those data.
All tweets combined, contestant Jeroen Kijk in de Vegte (hurray for Dutch surnames) was mentioned most frequently. Vincent Vianen passes him only once retweets are excluded.
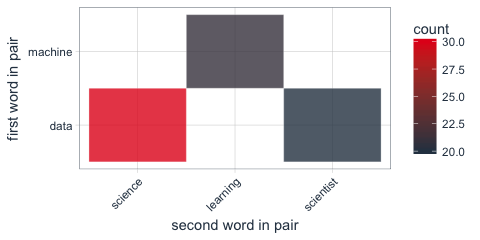
If we split the data based on the time of the post relative to the episode, it becomes clear that the majority of the tweets mentioning Vincent occured during the episode’s airtime.
This is likely due to one of two reasons. First of all, Vincent was eliminated in this first episode and the production team of WIDM has the tendency to fool the viewer and frame the contestant that is going to be eliminated as the mole. Often, the eliminated contestant received more airtime and all his/her suspicious behaviors and remarks are showed. Potentially, viewers have tweeted about Vincent throughout the episode because they suspected him. Secondly, Vincent was eliminated at the end of this current episode. This may have roused some positive/negative tweets on his behalf. These would likely not be suspicions by the public though. Let’s see what the data can tell us, by plotting the cumulative name references in tweets per minute during the episode.

Hmm… Apparently, Vincent was not being suspected by Dutch Twitter folk to the extent I had expected. He is not being mentioned any more or less than other contestants (with the exception of Jeroen) up until the very end of the episode. There is a slight bump in the frequency after his blunt behavior, but sentiment for Vincent really kicks in around the 21:25 when it becomes evident that he is going home.
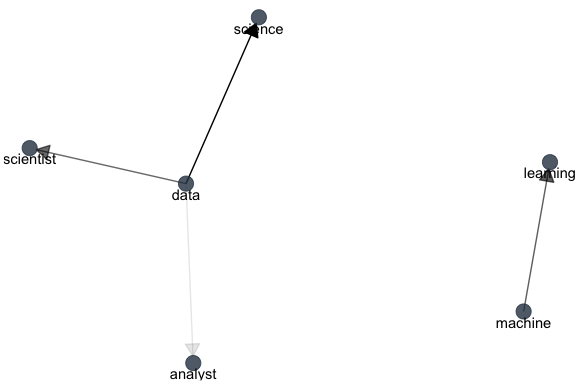
The graph also tells us Jeroen is quite popular throughout the entire episode, whereas both Roos and Sanne receive some last minute boosts in the latter part of the episode. Reference to the rest of the contestants seems to be fairly level.
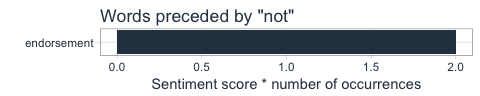
Also in the tweets that were posted since the episode’s end, Jeroen is mentioned most.
Compared to one of the more popular WIDM polls, our Twitter results seem quite reliable. The four most suspected contestants according to the poll overlap nicely with our Twitter frequencies. The main difference is that Sanne Wallis de Vries is the number one suspect in the poll, whereas she comes in third in our results.
Let us now examine the frequencies of the individual contestants over the course of time, with aggregated frequencies before, during and after the first episode (note: no cumulative here). Note that Vincent has a dotted line as he was eliminated at the end of the first episode. Seemingly, the public immediately lost interest. Jeroen, in particular, seems to be of interest during as well as after the first episode. Enthusiasm about Diederik also increases a fair amount during and after the show. Finally, interest in Roos and Sanne keeps grows, but at a lesser rate. Excitement regarding the rest of the contestants seems to level off.
We have almost come to the end of my Twitter analysis of the first episode of ‘Wie is de Mol?’ 2017. As my main intent was to spark curiosity for WIDM, data visualization, and general programming, I hope this post is received with positive sentiment.
If this blog/post gets a sequel, my main focus would be to track contestant popularity over time, the start of which can be found in the final visualizations below. If I find the time, I will create a more fluent tracking tool, updating on a daily basis, potentially in an interactive Shiny webpage application. I furthermore hope to conduct some explorative text and sentiment analysis – for instance, examining the most frequently used terms to describe specific contestants, what emotions tweets depict, or what makes people retweet others. Possibly, there is even time to perform some network analysis – for instance, examining whether sub-communities exist among the tweeting ‘Molloten‘.


For now, I hope you enjoyed this post! Please do not hesitate to share or use its contents. Also, feel free to comment or to reach out at any time. Maybe you as a reader can suggest additional elements to investigate, or maybe you can spot some obvious errors I made. Also, feel free to download the data yourself and please share any alternative or complementary analyses you conduct. Most of the R script you can find below.in the appendices
Cheers!
Link to Dutch blog (part 1)
About the author: Paul van der Laken is a Ph.D. student at the department of Human Resource Studies at Tilburg University. Working closely with organizations such as Shell and Unilever, Paul conducts research on the application of advanced statistical analysis within the field of HR. Among others, his studies examine how organizations can make global mobility policies more evidence-based and thus effective. Next to this, Paul provides graduate and post-graduate training on HR data analysis at Tilburg University, TIAS Business School and in-house at various organizations.
Appendix: R setup
Let me run you through the packages I used.
libs <- c('plyr','dplyr','tidyr','stringr','twitteR','tm','wordcloud','ggplot2')
lapply(libs,require,character.only = T)
- The plyr–family make coding so much easier and prettier. (here for more of my blogs on the tidyverse)
- stringr comes in handy when dealing with text data.
- twitteR is obviously the package with which to download Twitter data.
- Though I think I did not use tm in the current analysis, it will probably come in handy for further text analysis.
- wordcloud is not necessarily useful, but does quick frequency visualizations of text data.
- It takes a while to become fluent in ggplot2 but it is so much more flexible than the base R plotting. A must have IMHO and I recommend anyone who works with R to learn ggplot sooner rather than later.
Retrieving the contestants
Although it was not really needed, I wanted to load in the 2017 WIDM contestants right from the official website. I quickly regretted this decision as it took me significantly longer than just typing in the names by hand would have. Nevertheless, it posed a good learning experience. Never before had I extracted raw HTML data and, secondly, this allowed me to refresh my knowledge of regular expressions (R specific). For those of you not familiar with regex, they are tremendously valuable and make coding so much easier and prettier. I am still learning myself and found this playlist by Daniel Shiffman quite helpful and entertaining, despite the fact that it is programming in, I think, javascript, and Mr. Shiffman can become overly enthusiastic from time to time.
After extracting the raw HTML data from the WIDM website contestants page (unfortunately, the raw data did not disclose the identity of the mole), I trimmed it down until a vector containing the contestants’ full names remained. By sorting the vector and creating a color palette right away, I hope to have ensured that I use the same color per contestant in future blogs. In case you may wonder, I specifically use a color-blind friendly palette (with two additions) as I have trouble myself. : )
In a later stage, I added a vector containing the first names of the losers (for lack of a better term) to simplify visualization.
webpage <- readLines('http://wieisdemol.avrotros.nl/contestants/')
contestants <- webpage[grepl('<strong>[A-Za-z]+</strong>',webpage)]
contestants <- gsub('</*\\w+>','',trimws(contestants))
contestants <- sort(contestants)
cbPalette <- c("#999999", "#000000", "#E69F00", "#56B4E9", "#009E73",
"#F0E442", "#0072B2", "#D55E00", "#CC79A7","#E9D2D2")
losers <- c('Vincent',rep(NA,9))
Retrieving the tweets
This is not the first blog on Twitter analysis in R. Other blogs demonstrate the sequence of steps to follow before one can extract Twitter data in a structured way.
After following these steps, I did a quick exploration of the actual Twitter feeds surrounding the WIDM series and decided that the hashtag #WIDM would serve as a good basis for my extraction. The latest time at which I ran this script is Monday 2017-01-09 17:03 GTM+0, two days after the first episode was aired. It took the system less than 3 minutes to download the 10,503 #WIDM tweets. The tweets and their metadata I stored into a data frame after which I ran a custom cleaning function to extract only the tweeted text.
Next, I subsetted the data in multiple ways. First of all, there seem to be a lot of retweets in my dataset and I expected original messages to differ from those retweeted (in a sense duplicates). Hence, I stored the original tweets in a separate file. Next, I decided to split the tweets based on the time of their creation relative to the show’s airtime. Those in the pre-subset were uploaded before the broadcast, those in the during-subset were posted during the episode, and those in the post-subset were sent after the first episode had ended and the first loser was known.
system.time(tweets.raw <- searchTwitter('#WIDM', n = 50000,lang = 'nl'))
user system elapsed
87.75 0.89 159.65
tweets.df <- twListToDF(tweets.raw)
tweets.text.clean <- CleanTweets(tweets.df$text)
tweets.text.clean.lc <- tolower(tweets.text.clean)
tweets.text.clean.lc.org <- tweets.text.clean.lc[substring(tweets.df$text,1,2) != 'RT']
airdate <- '2017-01-07'
e1.start <- as.POSIXct(paste(airdate,'19:25:00'))
e1.end <- as.POSIXct(paste(airdate,'20:35:00'))
tweets.text.clean.lc.pre <- tweets.text.clean.lc[tweets.df$created < e1.start]
tweets.text.clean.lc.during <- tweets.text.clean.lc[tweets.df$created > e1.start & tweets.df$created < e1.end]
tweets.text.clean.lc.post <- tweets.text.clean.lc[tweets.df$created > e1.end]
Contestant mentions
Ultimately, my goal was to create some sort of thermometer or measurement instrument to analyze which of the contestants is suspected most by the public. Some of the tweets include quite clear statements of suspicion (“verdenkingen” in Dutch) or just plain accusations:
head(tweets.text.clean[grepl('ik verdenk [A-Z]',tweets.text.clean)])
[1] " widm ik verdenk Sigrid omdat bij de executie haar reactie erg geacteerd leek"
[2] "Oké ik verdenk Jochem heel erg widm"
head(tweets.text.clean[grepl('[A-Z][a-z]+ is de mol',tweets.text.clean)],4)
[1] "Jeroen is de mol widm"
[2] " Ik weet het zeker Jandino is de mol amoz widm moltalk"
[3] "Ik weet het zeker Jandino is de mol amoz widm moltalk"
[4] "Net widm teruggekeken Ik zeg Sigrid is de mol
However, writing the regular expression(s) to retrieve all the different ways in which tweets can accuse contestants or name suspicions would be quite the job. Besides, in this early phase of the series, tweets often just mention uncommon behaviors contestants have displayed, rather than accusing them. I theorized that those who act more suspiciously would be mentioned more frequently on Twitter, and decided to do a simple count of contestant name occurrences.
What follows are three multi-layer for-loops; probably super inefficient for larger datasets, but here it does the trick in mere seconds while being relatively easy to program. In it, I loop through the different subsets I created earlier and do a contestant name count in each of these. I also count references over time and during the episode’s airtime in specific. I recommend you to scroll past it quickly.
named <- data.frame()
for(i in contestants){
name <- tolower(word(i,1))
count.rt <- 0
for (j in 1:length(tweets.text.clean.lc)){
tweet <- tweets.text.clean.lc[j]
if(grepl(name,tweet)){
count.rt <- count.rt + 1
}
}
[......truncated......]
named <- rbind.data.frame(named,
cbind(Contestant = i,
Total = count.rt,
Original= count.org,
BeforeEp = count.pre,
DuringEp = count.during,
AfterEp = count.post),
stringsAsFactors = F)
print(paste(i,'... done!'))
}
named.overtime <- data.frame()
for(Day in unique(as.Date(tweets.df$created))){
tweets <- tweets.text.clean.lc[as.Date(tweets.df$created) == Day]
cat(as.Date(as.numeric(Day), origin = '1970-01-01'),':',sep = '')
for(i in contestants){
name <- tolower(word(i,1))
Count <- 0
for(j in 1:length(tweets)){
tweet <- tweets[j]
if(grepl(name,tweet)){
Count <- Count + 1
}
}
named.overtime <- rbind.data.frame(
named.overtime,
cbind(Day,Contestant = word(i,1),Count),
stringsAsFactors = F
)
cat(word(i,1),' ')
}
cat('\n')
}
named.during <- data.frame()
for(Minute in unique(minutes.during)){
temp <- tweets.text.clean.lc.during[minutes.during == Minute]
for(i in contestants){
name = tolower(word(i,1))
Count <- 0
for(tweet in temp){
if(grepl(name,tweet)){
Count <- Count + 1
}
}
named.during <- rbind.data.frame(named.during,
cbind(Minute,Contestant = word(i,1),Count),
stringsAsFactors = F)
}
}
After some final transformations, I have the following tables nicely stored two data frames.
> named
Contestant Total Original BeforeEp DuringEp AfterEp
1 Diederik Jekel 358 201 16 128 214
2 Imanuelle Grives 96 65 5 43 48
3 Jeroen Kijk in de Vegte 517 335 12 218 287
4 Jochem van Gelder 157 124 15 73 69
5 Roos Schlikker 203 154 7 88 108
6 Sanne Wallis de Vries 255 194 3 106 146
7 Sigrid Ten Napel 135 102 7 65 63
8 Thomas Cammaert 97 69 5 45 47
9 Vincent Vianen 406 354 19 285 102
10 Yvonne Coldeweijer 148 109 16 66 66
> named.overtime
Day Contestant Count Cumulative
<date> <chr> <int> <int>
1 2016-12-31 Diederik 0 0
2 2016-12-31 Imanuelle 0 0
3 2016-12-31 Jeroen 0 0
4 2016-12-31 Jochem 0 0
5 2016-12-31 Roos 1 1
6 2016-12-31 Sanne 0 0
7 2016-12-31 Sigrid 0 0
8 2016-12-31 Thomas 0 0
9 2016-12-31 Vincent 0 0
10 2016-12-31 Yvonne 0 0
# ... with 90 more rows
> named.during
Minute Contestant Count Cumulative
<chr> <chr> <int> <int>
1 19:25 Diederik 0 0
2 19:25 Imanuelle 0 0
3 19:25 Jeroen 0 0
4 19:25 Jochem 0 0
5 19:25 Roos 0 0
6 19:25 Sanne 0 0
In order to summarize the frequency table above in a straightforward visual, I wrote the following custom function to automate the generation of barplots for each of the subsets I created earlier.
y.max <- ceiling(max(named$Total)/100)*100
GeomBarFlipped <- function(data, x, y, y.max = y.max,
x.lab = 'Contestant', y.lab = '# Mentioned', title.lab){
ggplot(data) +
geom_bar(aes(x = reorder(x,y), y = y), stat = 'identity') +
geom_text(aes(x = reorder(x,y), y = y, label = y),
col = 'white', hjust = 1.3) +
labs(x = x.lab, y = y.lab, title = title.lab) +
lims(y = c(0,y.max)) + theme_bw() + coord_flip()
}
For further details surrounding the analyses, please feel free to reach out.
About the author: Paul van der Laken is a Ph.D. student at the department of Human Resource Studies at Tilburg University. Working closely with organizations such as Shell and Unilever, Paul conducts research on the application of advanced statistical analysis within the field of HR. Among others, his studies examine how organizations can make global mobility policies more evidence-based and thus effective. Next to this, Paul provides graduate and post-graduate training on HR data analysis at Tilburg University, TIAS Business School and in-house at various organizations.



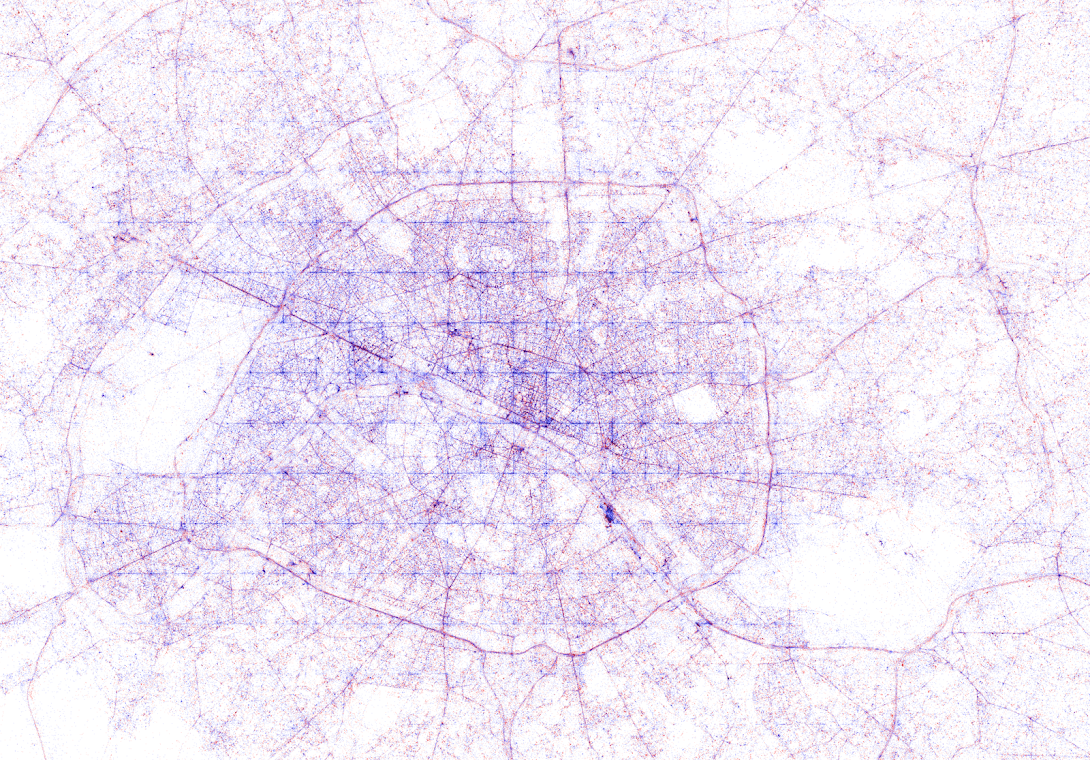

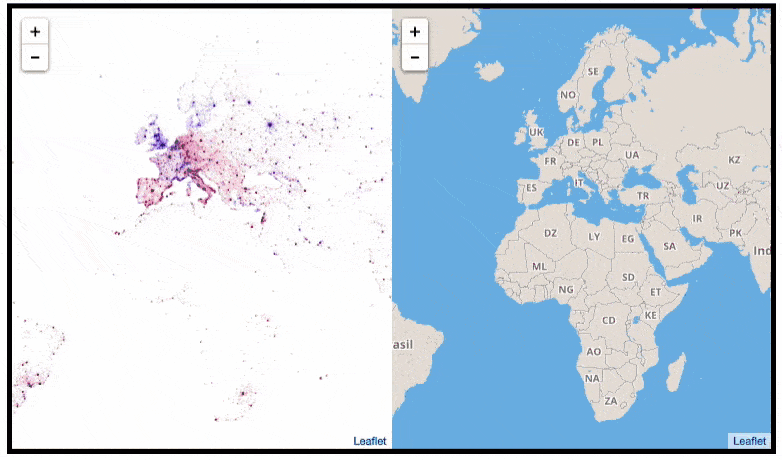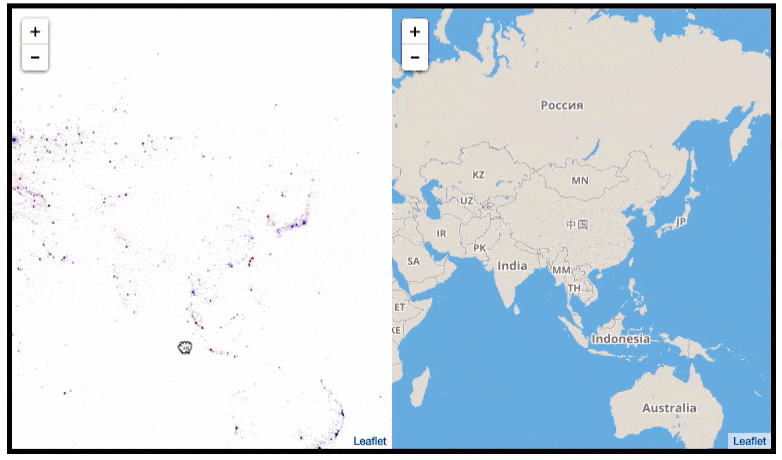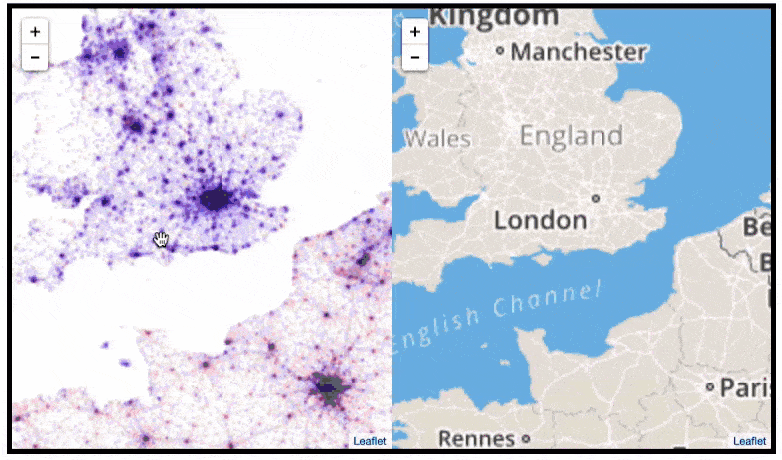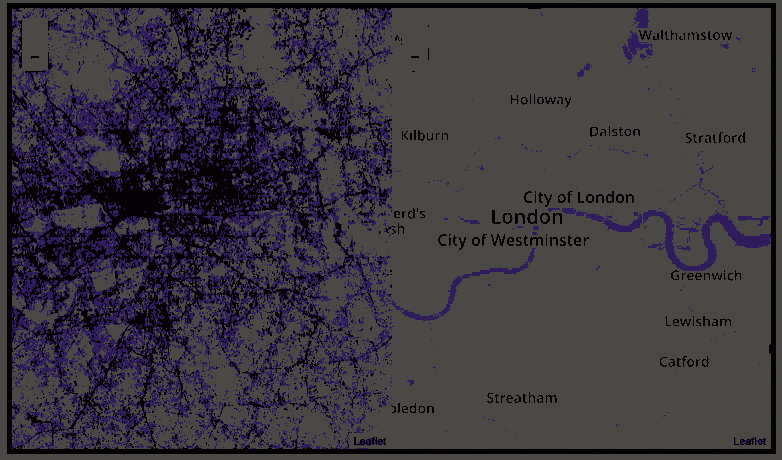 This required quite complex code, the details of which are in his blog. For now, here is another, beautiful map of England, with (the density of) Shazam recognitions reflected by color intensity on a dark background.
This required quite complex code, the details of which are in his blog. For now, here is another, beautiful map of England, with (the density of) Shazam recognitions reflected by color intensity on a dark background.