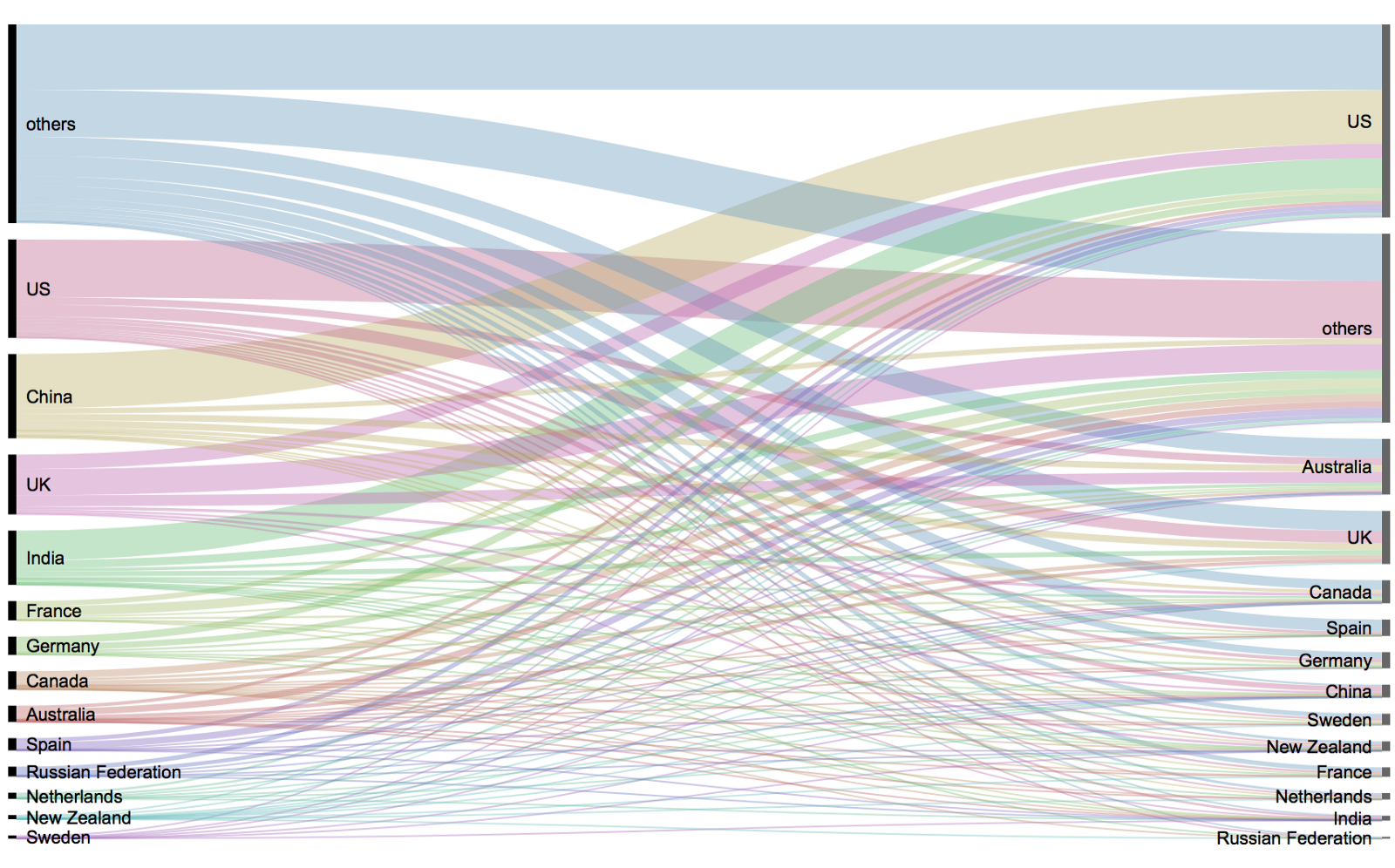
Thanks to Sebastian Raschka I am able to share this great GitHub overview page of relevant graph classification techniques, and the scientific papers behind them. The overview divides the algorithms into four groups:
As well as a link to relevant graph classification benchmark datasets.
"Awesome Graph Classification" — A collection of graph classification methods, covering embedding, deep learning, graph kernel, and factorization papers with reference implementations https://t.co/ugpL3xSvf1
I’ve seen some uses of reinforcement learning and generative algorithms for architectural purposes already, like these evolving blueprints for school floorplans. However, this new application called ArchiGAN blew me away!
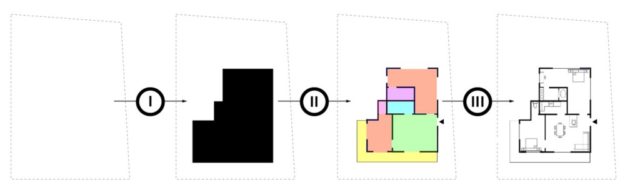
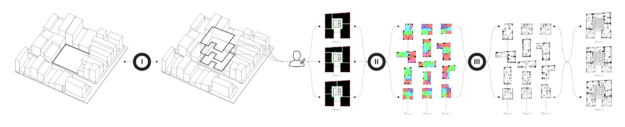
ArchiGAN (try here) was made by Stanislas Chaillou as a Harvard master’s thesis project. The program functions in three steps:
building footprint massing
program repartition
furniture layout
Stanislas’ three generation steps
Each of these three steps uses a TensorFlow Pix2Pix GAN-model (Christopher Hesse’s implementation) in the back-end, and their combination makes for a entire apartment building “generation stack” — according to Stanislas — which also allows for user input at each step.
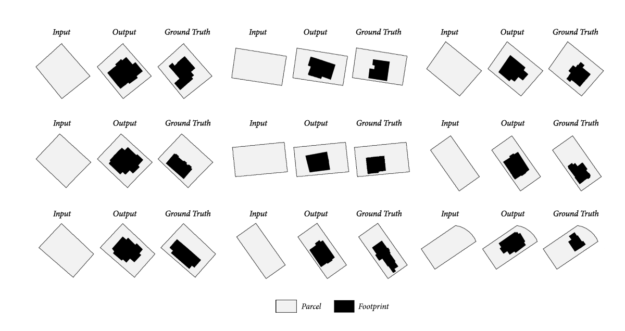
The design of a building can be inferred from the piece of land it stands on. Hence, Stanislas fed his first model using GIS-data (Geographic Information System) from the city of Boston in order to generate typical footprints based on parcel shapes.
The inputs and outputs of model I
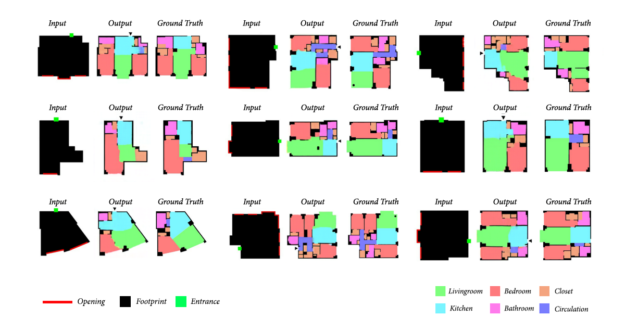
Stanislas’ second model was responsible for repartition and fenestration (the placement of windows and doors). This GAN took the footprint of the building (the output of model I) as input, along with the position of the entrance door (green square), and the positions of the user-specified windows.
Stanislas used a database of 800+ plans of apartments for training. To visualize the output, rooms are color-coded and walls and fenestration are blackened.
The inputs and outputs of model II
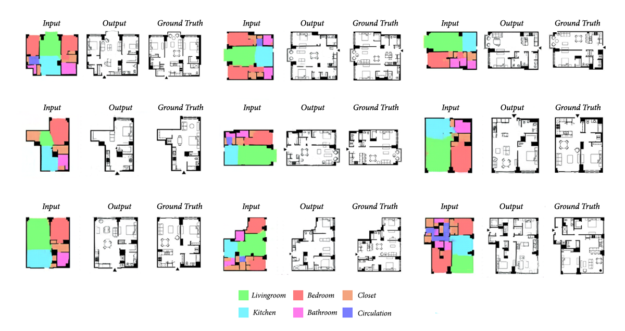
Finally, in the third model, the rooms are filled with appropriate furniture. What training data Stanislas has used here, he did not specify in the original blog.
The inputs and outputs of model III
Now, to put all things together, Stanislas created a great interactive tool you can play with yourself. The original NVIDEA blog contains some great GIFs of the tool being used:
Stanislas’ GAN-models progressively learned to design rooms and realistically position doors and windows. It took about 250 iterations to get some realistic floorplans out of the algorithm. Here’s how an example learning sequence looked like:
Visualization of the training process
Now, Stanislas was not done yet. He also scaled the utilization of GANs to design whole apartment buildings. Here, he chains the models and processes multiple units as single images at each step.
Generating whole appartment blocks using ArchiGAN
Stanislas did other cool things to improve the flexibility of his ArchiGAN models, about which you can read more in the original blog. Let these visuals entice you to read more:
ArchiGAN scaled to handle whole appartment blocks and neighborhoods.
I believe a statistical approach to design conception will shape AI’s potential for Architecture. This approach is less deterministic and more holistic in character. Rather than using machines to optimize a set of variables, relying on them to extract significant qualities and mimicking them all along the design process represents a paradigm shift.
I am so psyched about these innovative applications of machine learning, so please help me give Stanislas the attention and credit he deserved.
Currently, Stanislas is Data Scientist & Architect at Spacemaker.ai. Read more about him in his NVIDEA developer bio here. He recently published a sequence of articles, laying down the premise of AI’s intersection with Architecture. Read here about the historical background behind this significant evolution, to be followed by AI’s potential for floor plan design, and for architectural style analysis & generation.
Just sitting there. Waiting to be opened, read. For months already.
The sender, you ask? Me. Paul van der Laken.
A nuisance that guy, I tell you. He keeps sending me reminders, of stuff to do, books to read. Books he’s sure a more productive me would enjoy.
Now, I could wipe my inbox. Be done with it. But I don’t wan’t to lose this digital to-do list… Perhaps I should put them here instead. So you can help me read them!
Each of the below links represents a formidable book on programming! (I hear) And there are free versions! Have a quick peek. A peek won’t hurt you:
Disclaimer: This page contains one or more links to Amazon. Any purchases made through those links provide us with a small commission that helps to host this blog.
Applied Predictive Modelling – by Max Kuhn & Kjell Johnson
The books listed above have a publicly accessible version linked. Some are legitimate. Other links are somewhat shady. If you feel like you learned something from reading one of the books (which you surely will), please buy a hardcopy version. Or an e-book. At the very least, reach out to the author and share what you appreciated in his/her work. It takes valuable time to write a book, and we should encourage and cherish those who take that time.
[Awful A.I.] aims to track all of them. We hope that Awful AI can be a platform to spur discussion for the development of possible contestational technology (to fight back!).
The Awful A.I. list contains a few dozen applications of machine learning where the results were less than optimal for several involved parties. These AI solutions either resulted in discrimination, disinformation (fake news), mass surveillance, or severely violate privacy or ethical issues in many other ways.
We’ve all heard of Cambridge Analytica, but there are many more on this Awful A.I. list:
Deep Fakes – Deep Fakes is an artificial intelligence-based human image synthesis technique. It is used to combine and superimpose existing images and videos onto source images or videos. Deepfakes may be used to create fake celebrity pornographic videos or revenge porn. [AI assisted fake porn][CNN Interactive Report]
Social Credit System – Using a secret algorithm, Sesame credit constantly scores people from 350 to 950, and its ratings are based on factors including considerations of “interpersonal relationships” and consumer habits. [summary][Foreign Correspondent (video)][travel ban]
SenseTime & Megvii– Based on Face Recognition technology powered by deep learning algorithm, SenseFace and Megvii provides integrated solutions of intelligent video analysis, which functions in target surveillance, trajectory analysis, population management. [summary][forbes][The Economist (video)]
David Dao is a PhD student at DS3Lab — the computer science dpt. of Zurich — and maintains the awful AI list. The cover photo was created by LargeStupidity on Drawception
2018 seemed to be the year of challengesgoing viral on the web. Most of them were plain stupid and/or dangerous. However, one viral challenge I did like: #100DaysOfCode
1. Code minimum an hour every day for the next 100 days.
2. Tweet your progress every day with the #100DaysOfCode hashtag.
3. Each day, reach out to at least two people on Twitter who are also doing the challenge
Many (aspiring) programming professionals competed in this challenge, sharing their learning journeys in domains from web development, machine learning, or data visualization.
With this blog, I wanted to share two of those learning journeys that stood out for me.
Machine learning
First, there’s Avik Jain’s 100 days of Machine Learning code repository on Github. Avik’s repository contains all learning activities he followed during the 53 days of programming he completed. Some of Avik’s entries really stood out, and I particularly liked his educational infographics:
Just look at the wonderful design and visual aids on this decision tree for dummies infographic, pseudocode and all:
Day 23: Decision trees for dummies. This just looks fabulous right?!
Although Avik didn’t seem to have completed the full 100 days, many others did.
Data visualization
I have blogged about Hannah Yan Han‘s 100 days of code project before, but she definately deserves another mention here. Her 100 days revolved around data science, data visualization, and storytelling using both R and Python. You can find her #100DaysOfCode Medium page here, and her associated Github repository here.
For example, one day Hannah explored where instant noodles come from, how they are served, and whether people like them or not.
What I found so great about Hannah’s project is that she picked a novel dataset every couple of days. Moreover, she used a extremely large variety of different visualization formats. All visuals were equally beautiful, but Hannah made sure to pick the right one for the purpose she was trying to serve. If you are interested in data visualization, you seriously should check out Hannah’s 100DaysOfCode Medium page.
The website PapersWithCode.com lists all scientific publications of which the codes are open-sourced on GitHub. Moreover, you can sort these papers by the stars they accumulated on Github over the past days.
The authors, @rbstojnic and @rosstaylor90, just made this in their spare time. Thank you, sirs!
Papers with Code allows you to quickly browse state-of-the-art research on GANs and the code behind them, for instance. Alternatively, you can browse for research and code on sentiment analysis or LSTMs.