In optimizing their transportation services, Uber uses evolutionary strategies and genetic algorithms to train deep neural networks through reinforcement learning. A lot of difficult words in one sentence; you can imagine the complexity of the process.
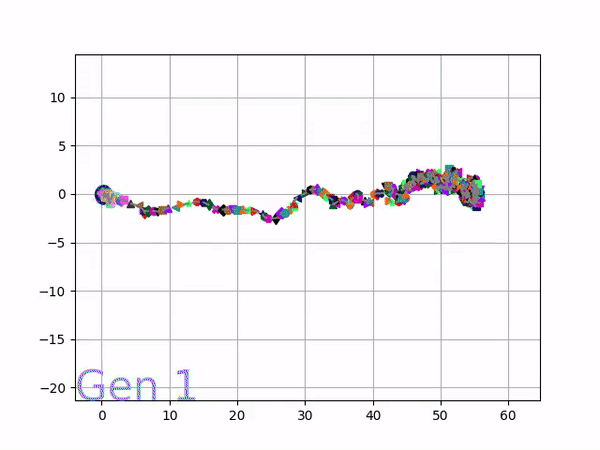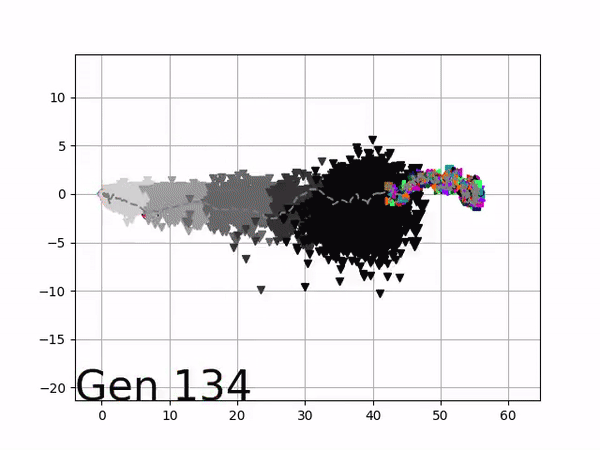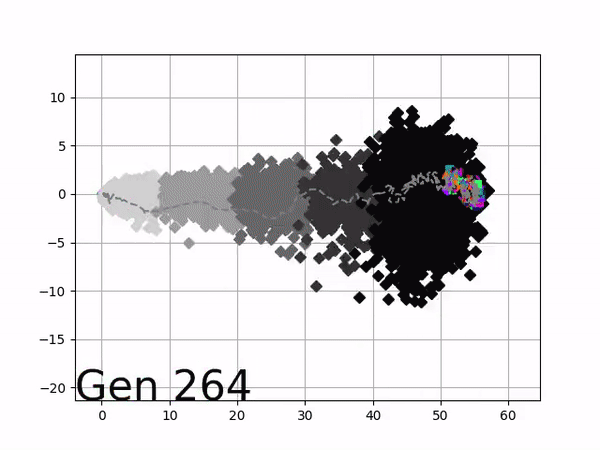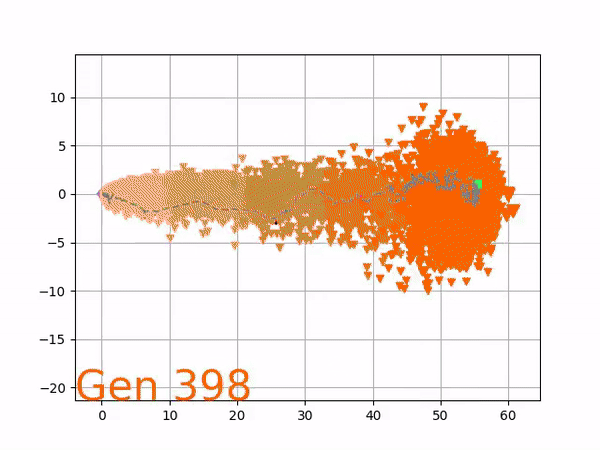
Because it is particularly difficult to observe the underlying dynamics of this learning process in neural network optimization, Uber built VINE – a Visual Inspector for NeuroEvolution. VINE helps to discover how evolutionary strategies and genetic optimizing are performing under the hood. In a recent article, they demonstrate how VINE works on the MujocoHumanoid Locomotion task.
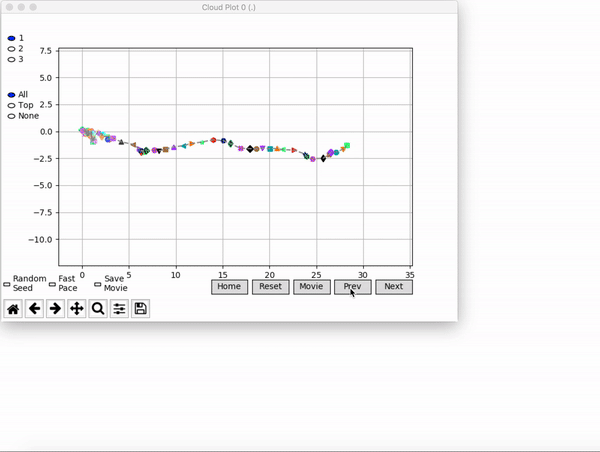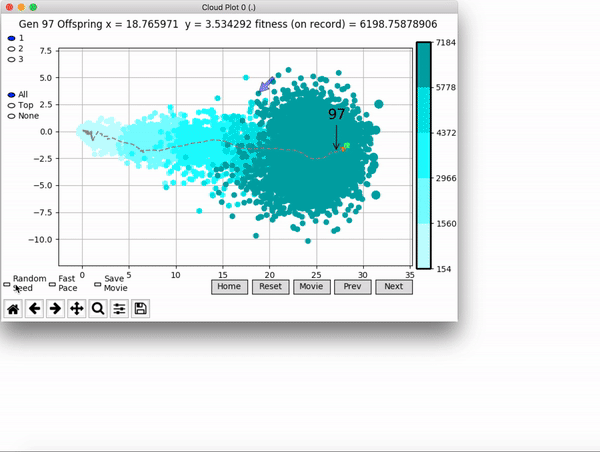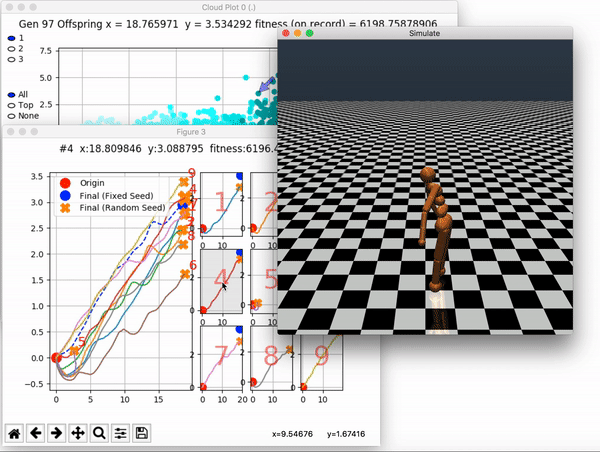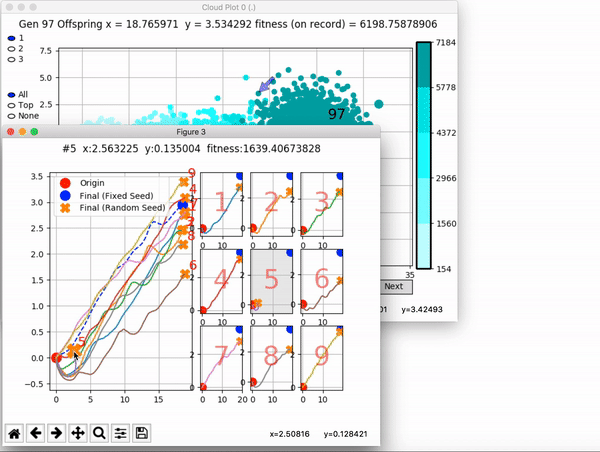
[…] In the Humanoid Locomotion Task, each pseudo-offspring neural network controls the movement of a robot, and earns a score, called its fitness, based on how well it walks. [Evolutionary principles] construct the next parent by aggregating the parameters of pseudo-offspring based on these fitness scores […]. The cycle then repeats.
VINE plots parent neural networks and their pseudo-offspring according to their performance. Users can then interact with these plots to:
visualize parents, top performance, and/or the entire pseudo-offspring cloud of any generation,
compare between and within generation performance,
and zoom in on any pseudo-offspring (points) in the plot to display performance information.
The GIFs below demonstrate what VINE is capable of displaying:
The evolution of performance over generations. The color changes in each generation. Within a generation, the color intensity of each pseudo-offspring is based on the percentile of its fitness score in that generation (aggregated into five bins). [original]Vine allows user to deep dive into each single generation, comparing generations and each pseudo-offspring within them [original]VINE can be found at this link. It is lightweight, portable, and implemented in Python.
In the video below, one of my favorite YouTube channels (Two Minute Papers) discusses a new super resolution project where academic scholars taught a neural network to improve low quality photo’s. The researchers took the same picture with multiple camera’s of varying quality and allowed a neural network to learn how the lowest quality pictures can be adjusted to more closely resemble their high quality counterparts. A very interesting approach and the results are just mind-boggling:
The field of computer vision tries to replicate our human visual capabilities, allowing computers to perceive their environment in a same way as you and I do. The recent breakthroughs in this field are super exciting and I couldn’t but share them with you.
In the TED talk below by Joseph Redmon (PhD at the University of Washington) showcases the latest progressions in computer vision resulting, among others, from his open-source research on Darknet – neural network applications in C. Most impressive is the insane speed with which contemporary algorithms are able to classify objects. Joseph demonstrates this by detecting all kinds of random stuff practically in real-time on his phone! Moreover, you’ve got to love how well the system works: even the ties worn in the audience are classified correctly!
The second talk, below, is more scientific and maybe even a bit dry at the start. Blaise Aguera y Arcas (engineer at Google) starts with a historic overview brain research but, fortunately, this serves a cause, as ~6 minutes in Blaise provides one of the best explanations I have yet heard of how a neural network processes images and learns to perceive and classify the underlying patterns. Blaise continues with a similarly great explanation of how this process can be reversed to generate weird, Asher-like images, one could consider creative art:
An example of a reversed neural network thus “estimating” an image of a bird [via Youtube]Blaise’s colleagues at Google took this a step further and used t-SNE to visualize the continuous space of animal concepts as perceived by their neural network, here a zoomed in part on the Armadillo part of the map, apparently closely located to fish, salamanders, and monkeys?
A zoomed view of part of a t-SNE map of latent animal concepts generated by reversing a neural network [via Youtube]We’ve seen these latent spaces/continua before. This example Andrej Karpathy shared immediately comes to mind:
If you want to learn more about this process of image synthesis through deep learning, I can recommend the scientific papers discussed by one of my favorite Youtube-channels, Two-Minute Papers. Karoly’s videos, such as the ones below, discuss many of the latest developments:
Let me know if you have any other video’s, papers, or materials you think are worthwhile!
Super-resolution imaging is a class of techniques that enhance the resolution of an imaging system (Wikipedia). The entertainment series CSI has been ridiculed for relying on exaggerated and unrealistic applications of it:
As a result, there are now several applications where machines have learned to literallyfill in the blanks in imagery. Most notable seems the method developed by Google: Rapid and Accurate Image Super Resolution, or RAISR is short. In contrast to other approaches, RAISR does not rely on (adversarial) neural network(s) and is thus not as resource-demanding to train. Moreover, it’s performance is quite remarkable:
I guess you’re eager to test this super resolution out yourself?! letsenhance.io let’s you enhance the resolution of five images for free, after which it charges you $5 per twenty pictures processed. The website feeds the input image to a neural net and puts out an image of which the resolution has been increased four fold! I tested it with this random blurry picture I retrieved from Google/Pinterest.
Original 500×500Enhanced 2000×2000
Do you see how much more detailed (though still blurry) the second image is? Nevertheless, upscaling four times seems about the limit as that is the default factor for both RAISR and Let’s Enhance. I am very curious to see how this super resolution is going to develop in the future, how it will be used to decrease memory or network demands, whether it will be integrated with video platforms like YouTube or Netflix, and which algorithm will ultimately take the crown!
Adam Geitgey likes to write about computers and machine learning. He explains machine learning as “generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.” (Part 1)
Adam’s visual explanation of two machine learning applications (original from Part 1)
In the fourth part of his series on machine learning Adam touches on Facial Recognition. Facebook is one of the companies using such algorithms in real-time, allowing them to recognize your friends’ faces after you’ve tagged them only a few times. Facebook reports they recognize faces with 97% accuracy, which is comparable to our own, human facial recognition abilities!
Facebook’s algorithms recognizing and automatically tagging Adam’s family. Helpful or creepy? (original from Part 4)
Adam decided to put up a challenge: would a facial recognition algorithm be able to distinguish Will Ferrell (famous actor) from Chad Smith (famous rock musician)? Indeed, these two celebrities look very much alike:
If you want to train such an algorithm, Adam explain, you need to overcome a series of related problems:
First, look at a picture and find all the faces in it
Second, focus on each face and be able to understand that even if a face is turned in a weird direction or in bad lighting, it is still the same person.
Third, be able to pick out unique features of the face that you can use to tell it apart from other people— like how big the eyes are, how long the face is, etc.
Finally, compare the unique features of that face to all the people you already know to determine the person’s name.
How the facial recognition algorithm steps might work (original from Part 4)
To detect the faces, Adam used Histograms of Oriented Gradients (HOG). All input pictures were converted to black and white (because color is not needed) and then every single pixel in our image is examined, one at a time. Moreover, for every pixel, the algorithm examined the pixels directly surrounding it:
Illustration of the algorithm as it would take in a black and white photo of Will Ferrel (original from Part 4)
The algorithm then checks, for every pixel, in which direction the picture is getting darker and draws an arrow (a gradient) in that direction.
Illustration of how algorithm would reduce a black and white photo of Will Ferrel to gradients (original from Part 4)
However, to do this for every single pixel would require too much processing power, so Adam broke up pictures in 16 by 16 pixel squares. The result is a very simple representation that does capture the basic structure of the original face, based on which we can now spot faces in pictures. Moreover, because we used gradients, the result will be similar regardless of the lighting of the picture.
The original image turned into a HOG representation (original from Part 4)
Now that the computer can spot faces, we need to make sure that it knows that two perspectives of the same face represent the same person. Adam uses landmarks for this: 68 specific points that exist on every face. An algorithm can then be trained to find these points on any face:
The 68 points on the image of Will Ferrell (original from Part 4)
Now the computer knows where the chin, the mouth and the eyes are, the image can be scaled and rotated to center it as best as possible:
The image of Will Ferrell transformed (original from Part 4)
Adam trained a Deep Convolutional Neural Network to generate 128 measurements for each face that best distinguish it from faces of other people. This network needs to train for several hours, going through thousands and thousands of face pictures. If you want to try this step yourself, Adam explains how to run OpenFace’s lua script. This study at Google provides more details, but it basically looks like this:
The training process visualized (original from Part 4)
After hours of training, the neural net will output 128 numbers accurately representing the specific face put in. Now, all you need to do is check which face in your database is most closely resembled by those 128 numbers, and you have your match! Many algorithms can do this final check, and Adam trained a simple linear SVM classifier on twenty pictures of Chad Smith, Will Ferrel, and Jimmy Falon (the host of a talkshow they both visited).
In the end, Adam’s machine had learned to distinguish these three people – two of whom are nearly indistinguishable with the human eye – in real-time:
Adam Geitgey’s facial recognition algorithm in action: providing real time classifications of the faces of lookalikes Chad Smith and Will Ferrel at Jimmy Falon’s talk show (original from Part 4)
Seth Bling calls himself a video game designer, a hacker and an engineer. You might know him from MarI/O: his neural network that got extremely good to at playing Super Mario Bros. The video below shows the genetic approach Seth used to train this neural network. Seth randomly generated a starting population of neural networks where the inputs – the current frame in the Mario video game – were randomly connected to the outputs – the eight buttons to press (jump, duck, up, down, right, left, etc). By giving the neural nets that made it furthest into the game a larger chance to pass on their genes (their input-output relations) to the next generation with slight mutations, Seth automatically generated neural networks that were more and more proficient in completing the game. In short, by evolution, Seth’s neural network learned the most effective response to the changing video game environment.
After MarI/O, Seth this week posted his newest creation: MariFlow. Here, Seth trained a neural network on 15 hours of training data, consisting of Seth himself playing Super Mario Kart. The neural network thus learned what buttons (output) Seth would most likely push when he encountered a certain Mario Kart parcours piece (input). However, due to random chance, the neural net would often get itself stuck in situations that Seth had not encountered in his training sessions (e.g., reversed, against a wall). The neural net would fail miserably in such situations because it had not learned how to behave. Accordingly, Seth had to generate new training data for these situations and he did so using Human-Computer Interactions in Machine Learning: Seth and the neural net would play alternatively for a while, thus generating training data for situations that Seth would not have encountered on its own. After the neural net was trained with these additional data, it became quite proficient in playing Mario Kart (like Seth) often even winning matches! If you want to know more, you can read the manual here or watch Seth’s video below. If you want to replicate or just play with the data, Seth made everything available here.
Seth has active YouTube, Twitch and Twitter channels and I recommend you check them out!








 You can read more details in the
You can read more details in the 















