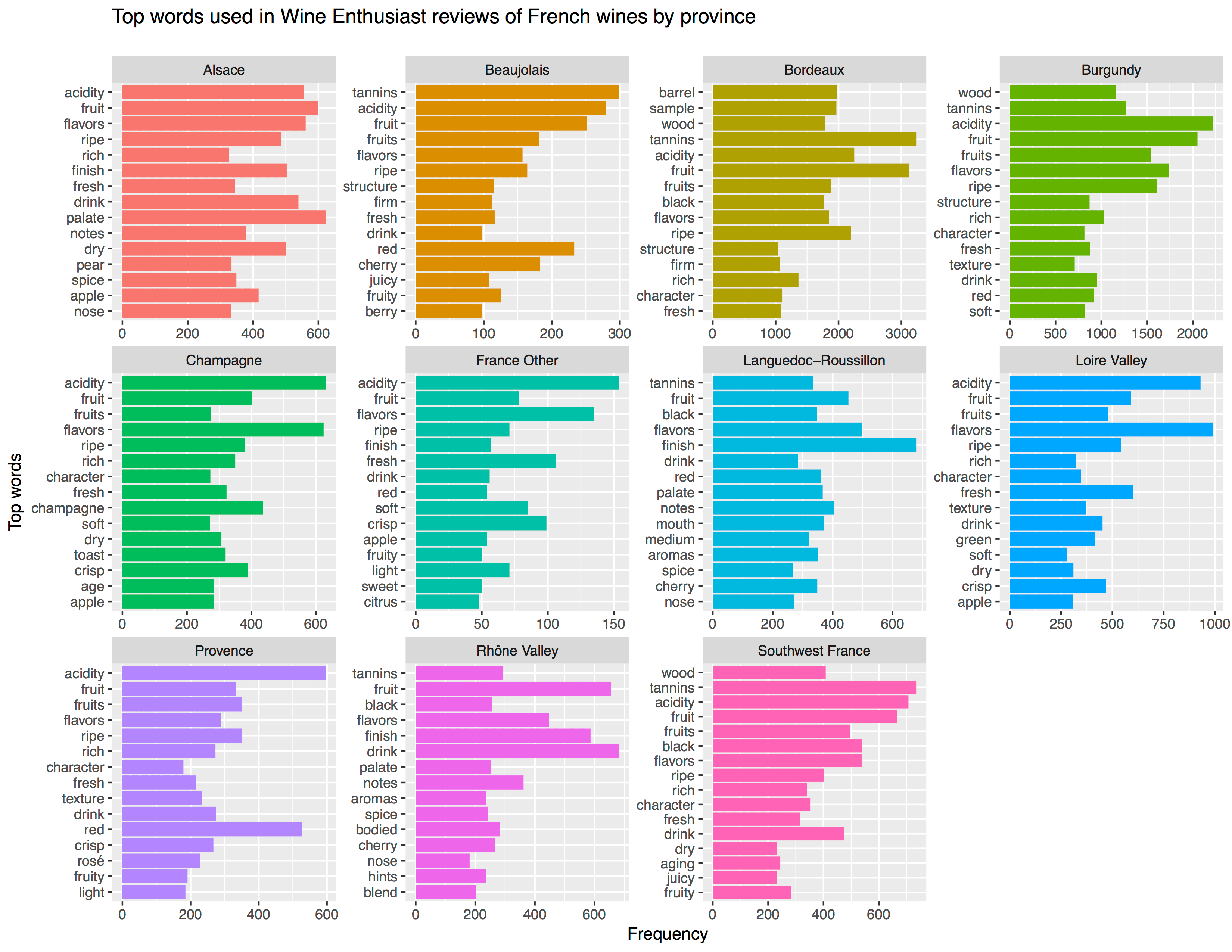
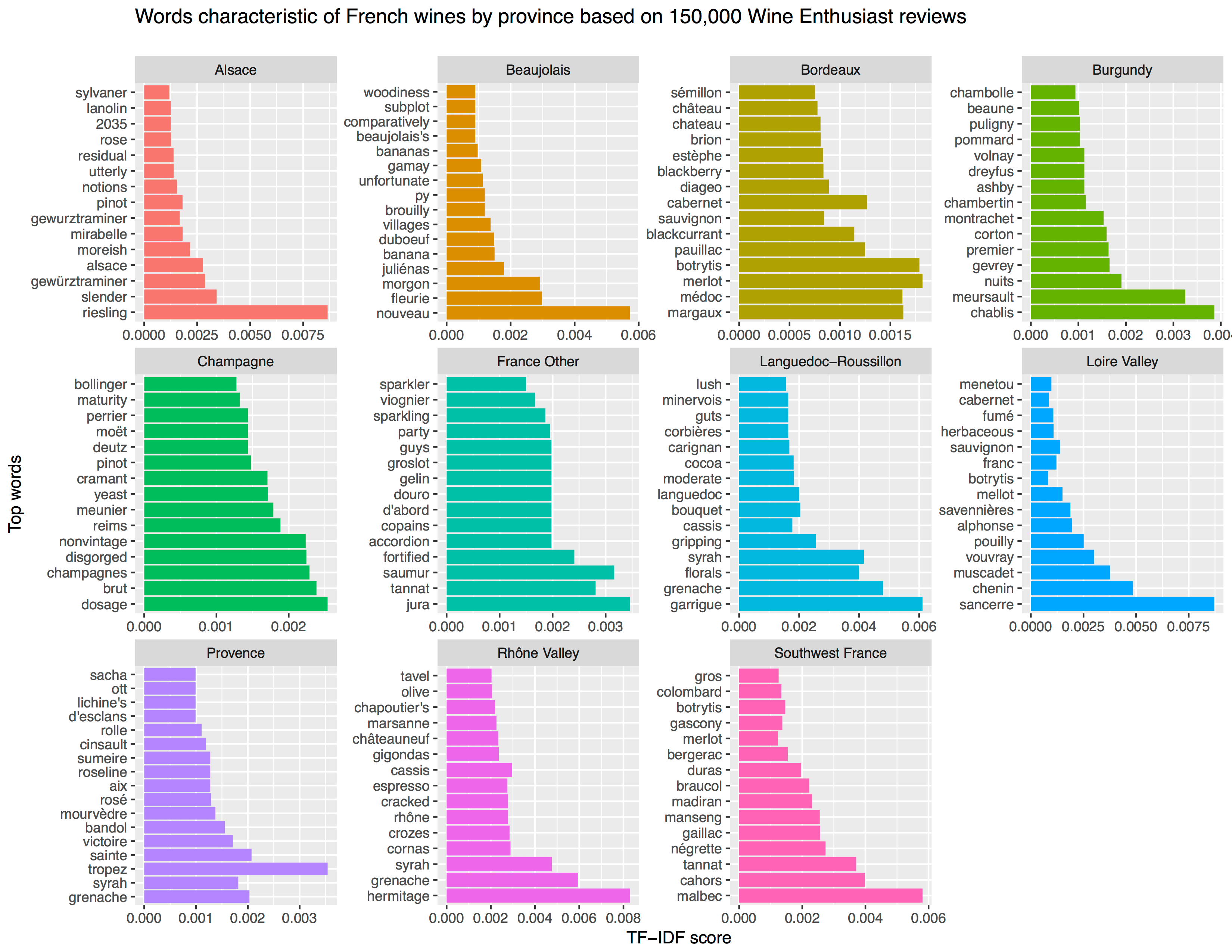
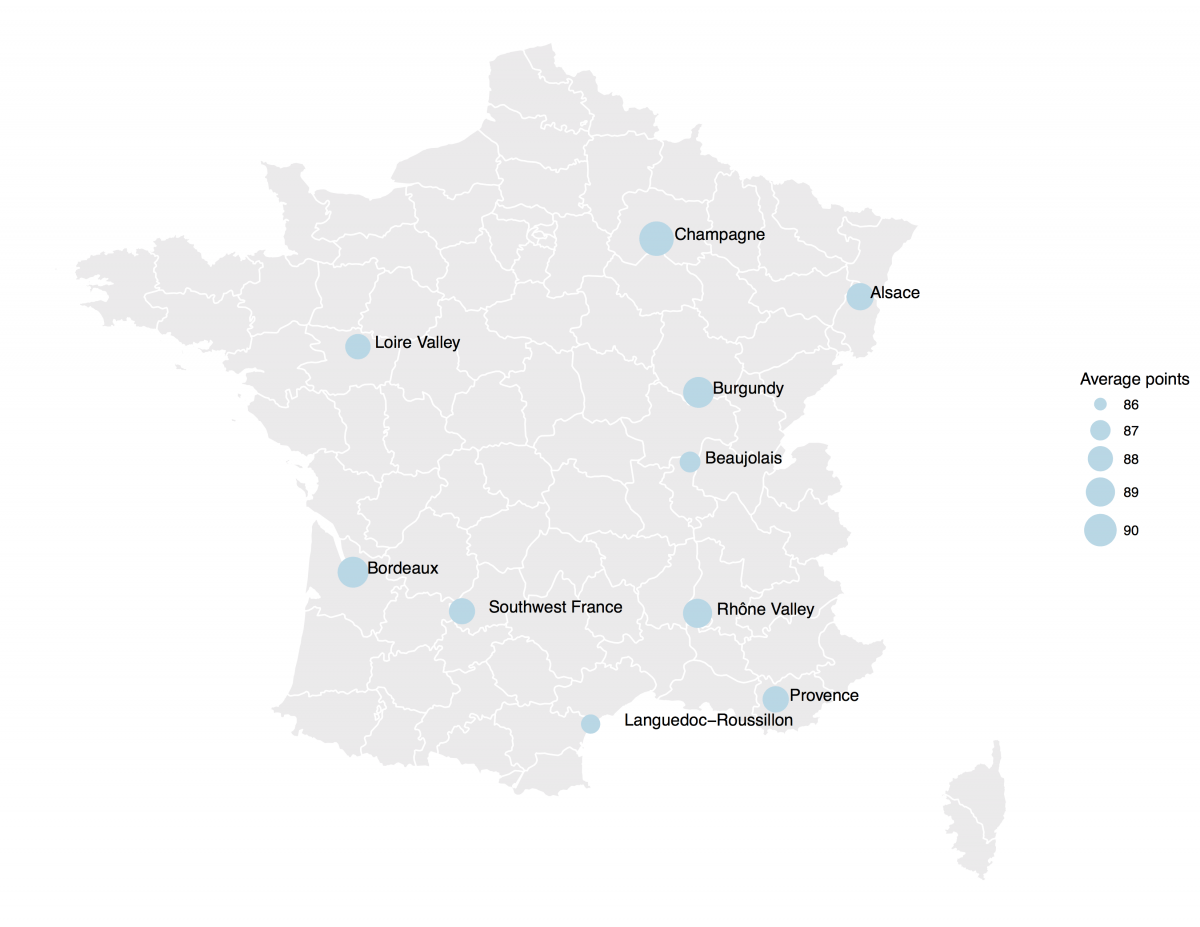
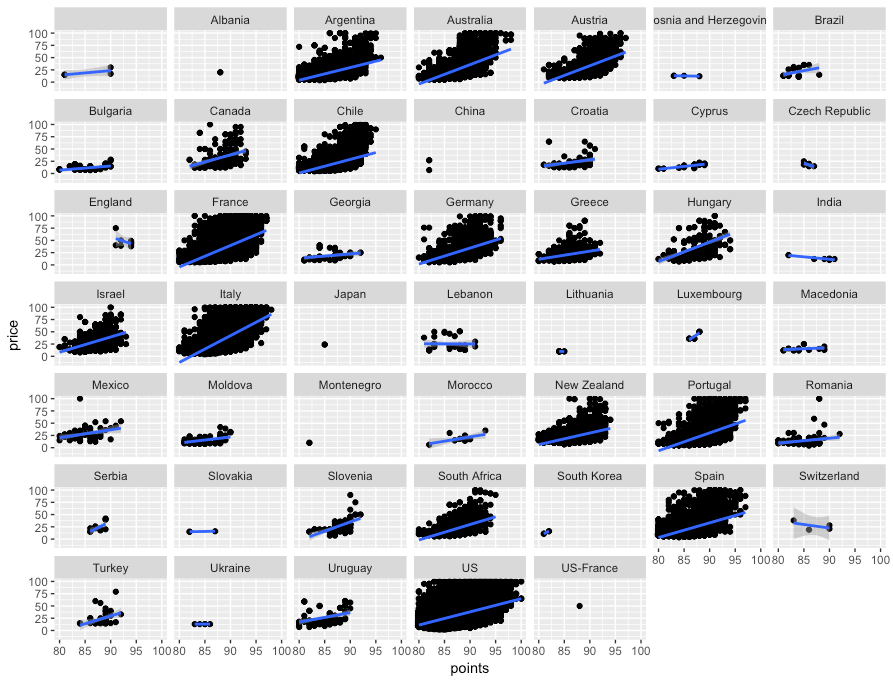
This pearl had been resting in my inbox for quite a while before I was able to add it to my R resources list. Citing its GitHub page, ggstatsplot is an extension of ggplot2 package for creating graphics with details from statistical tests included in the plots themselves and targeted primarily at behavioral sciences community to provide a one-line code to produce information-rich plots. The package is currently maintained and still under development by Indrajeet Patil. Nevertheless, its functionality is already quite impressive. You can download the latest stable version via:
utils::install.packages(pkgs = "ggstatsplot")
Or download the development version via:
devtools::install_github( repo = "IndrajeetPatil/ggstatsplot", # package path on GitHub dependencies = TRUE, # installs packages which ggstatsplot depends on upgrade_dependencies = TRUE # updates any out of date dependencies )
The package currently supports many different statistical plots, including:
?ggbetweenstats ?ggscatterstats ?gghistostats ?ggpiestats ?ggcorrmat ?ggcoefstats ?combine_plots ?grouped_ggbetweenstats ?grouped_ggscatterstats ?grouped_gghistostats ?grouped_ggpiestats ?grouped_ggcorrmat
Let’s take a closer look at the first one:
ggbetweenstats
This function creates either a violin plot, a box plot, or a mix of two for between-group or between-condition comparisons and additional detailed results from statistical tests can be added in the subtitle. The simplest function call looks like the below, but much more complex information can be added and specified.
set.seed(123) # to get reproducible results # the functions work approximately the same as ggplot2 ggstatsplot::ggbetweenstats( data = datasets::iris, x = Species, y = Sepal.Length, messages = FALSE ) + # and can be adjusted using the same, orginal function calls ggplot2::coord_cartesian(ylim = c(3, 8)) + ggplot2::scale_y_continuous(breaks = seq(3, 8, by = 1))

ggscatterstats
Not all plots are ggplot2-compatible though, for instance, ggscatterstats is not. Nevertheless, it produces a very powerful plot in my opinion.
ggstatsplot::ggscatterstats( data = datasets::iris, x = Sepal.Length, y = Petal.Length, title = "Dataset: Iris flower data set", messages = FALSE )

ggcormat
ggcorrmat is also quite impressive, producing correlalograms with only minimal amounts of code as it wraps around ggcorplot. The defaults already produces publication-ready correlation matrices:
ggstatsplot::ggcorrmat( data = datasets::iris, corr.method = "spearman", sig.level = 0.005, cor.vars = Sepal.Length:Petal.Width, cor.vars.names = c("Sepal Length", "Sepal Width", "Petal Length", "Petal Width"), title = "Correlalogram for length measures for Iris species", subtitle = "Iris dataset by Anderson", caption = expression( paste( italic("Note"), ": X denotes correlation non-significant at ", italic("p "), "< 0.005; adjusted alpha" ) ) )

ggcoefstats
Finally, ggcoefstats is a wrapper around GGally::ggcoef, creating a plot with the regression coefficients’ point estimates as dots with confidence interval whiskers. Here’s an example with some detailed specifications:
ggstatsplot::ggcoefstats( x = stats::lm(formula = mpg ~ am * cyl, data = datasets::mtcars), point.color = "red", vline.color = "#CC79A7", vline.linetype = "dotdash", stats.label.size = 3.5, stats.label.color = c("#0072B2", "#D55E00", "darkgreen"), title = "Car performance predicted by transmission and cylinder count", subtitle = "Source: 1974 Motor Trend US magazine" ) + ggplot2::scale_y_discrete(labels = c("transmission", "cylinders", "interaction")) + ggplot2::labs(x = "regression coefficient", y = NULL)