In optimizing their transportation services, Uber uses evolutionary strategies and genetic algorithms to train deep neural networks through reinforcement learning. A lot of difficult words in one sentence; you can imagine the complexity of the process.
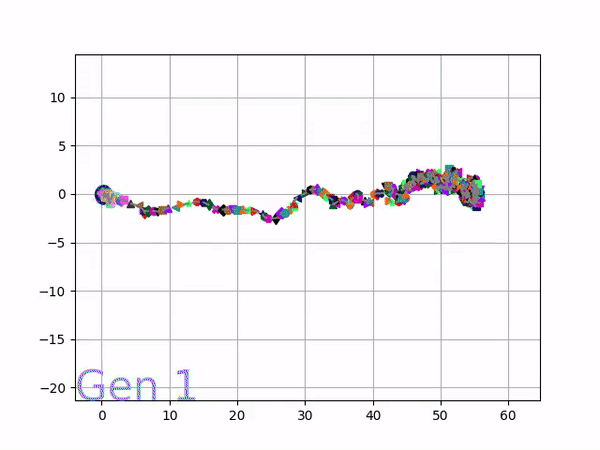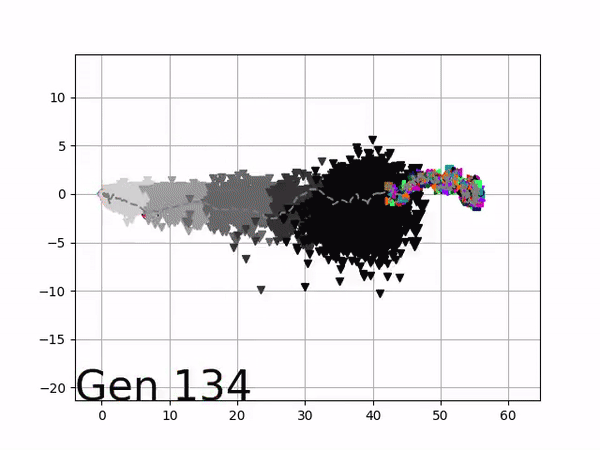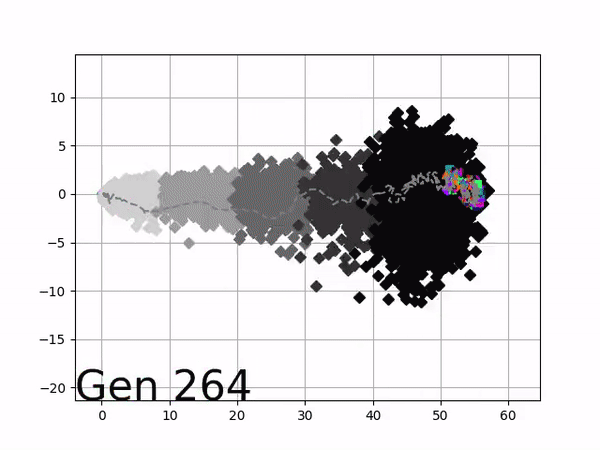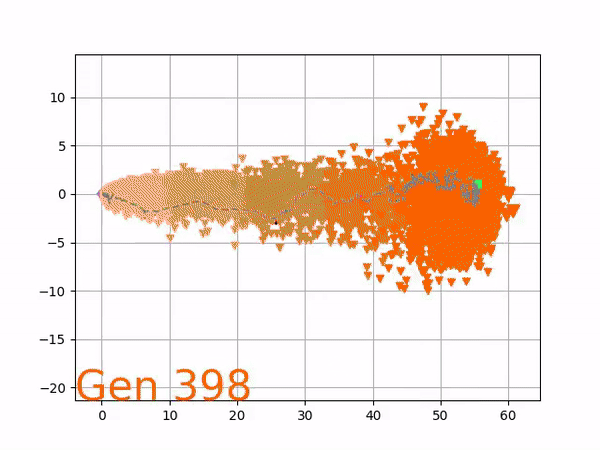
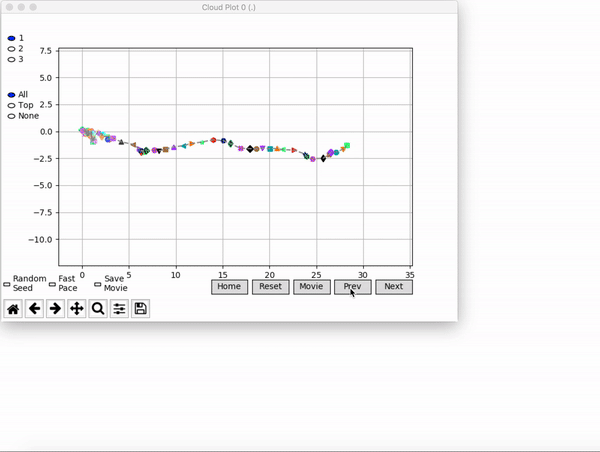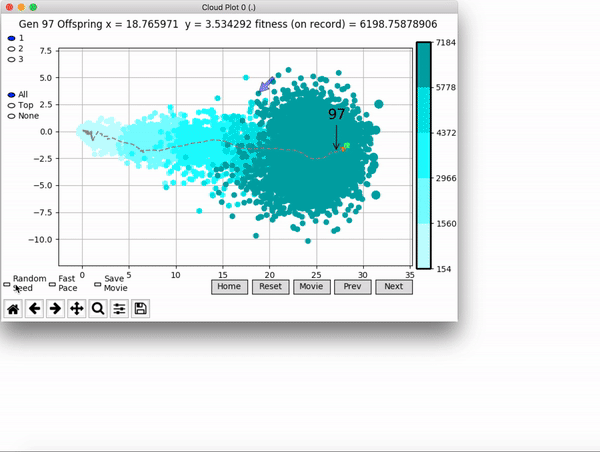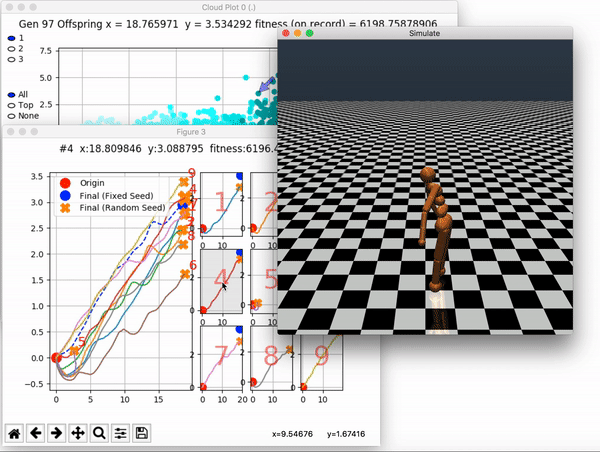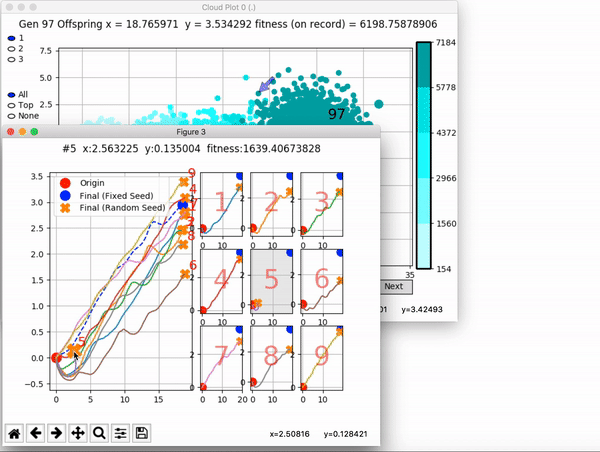
Because it is particularly difficult to observe the underlying dynamics of this learning process in neural network optimization, Uber built VINE – a Visual Inspector for NeuroEvolution. VINE helps to discover how evolutionary strategies and genetic optimizing are performing under the hood. In a recent article, they demonstrate how VINE works on the MujocoHumanoid Locomotion task.
[…] In the Humanoid Locomotion Task, each pseudo-offspring neural network controls the movement of a robot, and earns a score, called its fitness, based on how well it walks. [Evolutionary principles] construct the next parent by aggregating the parameters of pseudo-offspring based on these fitness scores […]. The cycle then repeats.
VINE plots parent neural networks and their pseudo-offspring according to their performance. Users can then interact with these plots to:
visualize parents, top performance, and/or the entire pseudo-offspring cloud of any generation,
compare between and within generation performance,
and zoom in on any pseudo-offspring (points) in the plot to display performance information.
The GIFs below demonstrate what VINE is capable of displaying:
The evolution of performance over generations. The color changes in each generation. Within a generation, the color intensity of each pseudo-offspring is based on the percentile of its fitness score in that generation (aggregated into five bins). [original]Vine allows user to deep dive into each single generation, comparing generations and each pseudo-offspring within them [original]VINE can be found at this link. It is lightweight, portable, and implemented in Python.
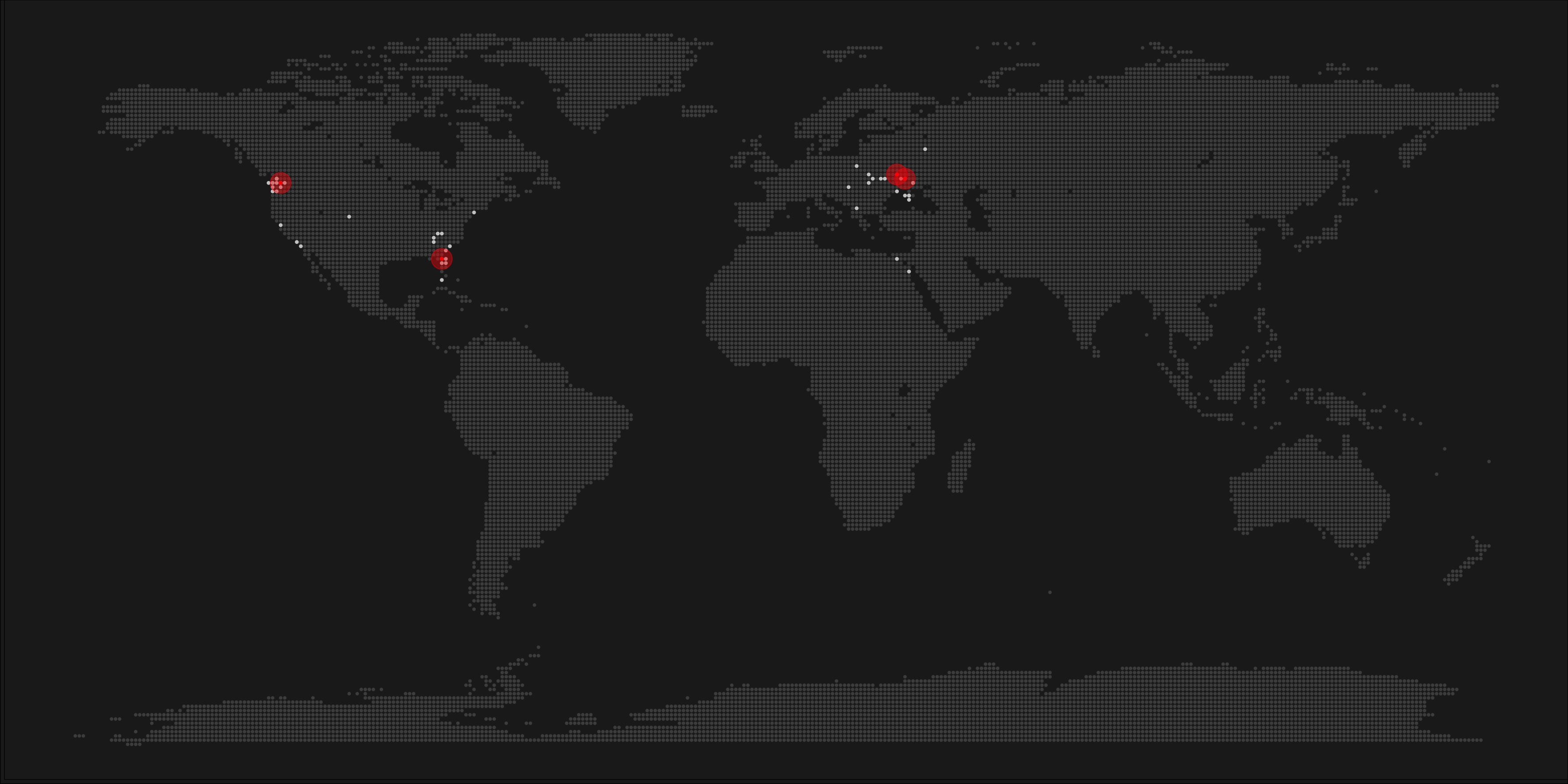
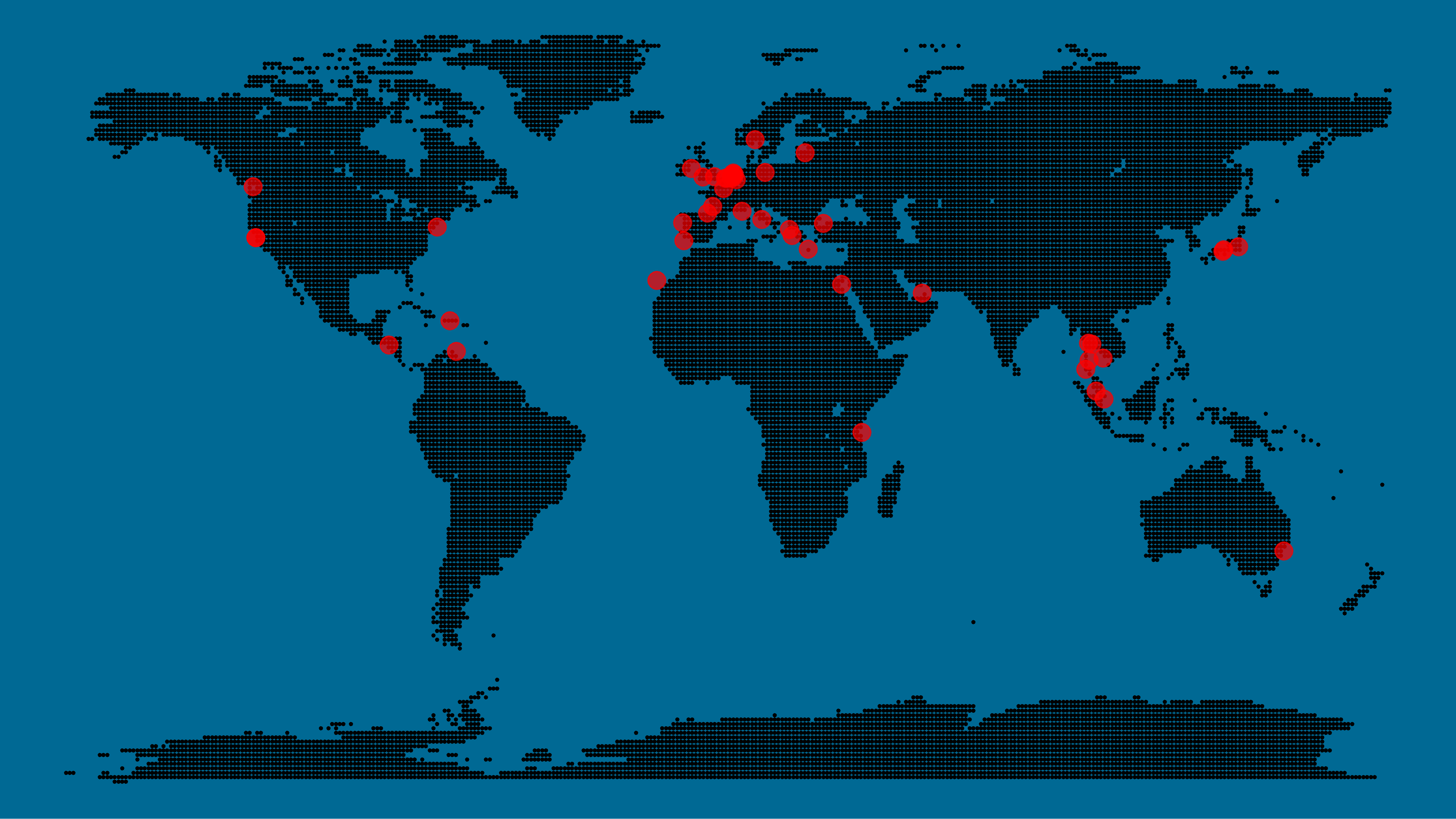
A pixel map of holiday and living locations made by Taras Kaduk in R [original]
Taras Kaduk seems as excited about R and the tidyverse as I am, as he built the beautiful map above. It flags all the cities he has visited and, in red, the cities he has lived. Taras was nice enough to share his code here, in the original blog post.
Now, I am not much of a globetrotter, but I do like programming. Hence, I immediately wanted to play with the code and visualize my own holiday destinations. Below you can find my attempt. The updated code I also posted below, but WordPress doesn’t handle code well, so you better look here.
Let’s run you through the steps to make such a map. First, we need to load some packages. I use the apply family to install and/or load a set of packages so that if I/you run the script on a different computer, it will still work. In terms of packages, the tidyverse (read more) includes some nice data manipulation packages as well as the famous ggplot2 package for visualizations. We need maps and ggmap for their mapping functionalities. here is a great little package for convenient project management, as you will see (read more).
Next, we need to load in the coordinates (longitudes and latitudes) of our holiday destinations. Now, I started out creating a dataframe with city coordinates by hand. However, this was definitely not a scale-able solution. Fortunately, after some Googling, I came across ggmap::geocode(). This function allows you to query the Google maps API(no longer works) Data Science Toolkit, which returns all kinds of coordinates data for any character string you feed it.
Although, I ran into two problems with this approach, this was nothing we couldn’t fix. First, my home city of Breda apparently has a name-city in the USA, which Google favors. Accordingly, you need to be careful and/or specific regarding the strings you feed to geocode() (e.g., “Breda NL“). Second, API’s often have a query limit, meaning you can only ask for data every so often. geocode() will quickly return NAs when you feed it more than two, three values. Hence, I wrote a simple while loop to repeat the query until the API retrieves coordinates. The query will pause shortly in between every attempt. Returned coordinates are then stored in the empty dataframe I created earlier. Now, we can easily query a couple dozen of locations without errors.
You can try it yourself: all you need to change is the city_name string.
### cities data ----------------------------------------------------------------
# cities to geolocate
city_name <- c("breda NL", "utrecht", "rotterdam", "tilburg", "amsterdam",
"london", "singapore", "kuala lumpur", "zanzibar", "antwerp",
"middelkerke", "maastricht", "bruges", "san fransisco", "vancouver",
"willemstad", "hurghada", "paris", "rome", "bordeaux",
"berlin", "kos", "crete", "kefalonia", "corfu",
"dubai", " barcalona", "san sebastian", "dominican republic",
"porto", "gran canaria", "albufeira", "istanbul",
"lake como", "oslo", "riga", "newcastle", "dublin",
"nice", "cardiff", "san fransisco", "tokyo", "kyoto", "osaka",
"bangkok", "krabi thailand", "chang mai thailand", "koh tao thailand")
# initialize empty dataframe
tibble(
city = city_name,
lon = rep(NA, length(city_name)),
lat = rep(NA, length(city_name))
) ->
cities
# loop cities through API to overcome SQ limit
# stop after if unsuccessful after 5 attempts
for(c in city_name){
temp <- tibble(lon = NA)
# geolocate until found or tried 5 times
attempt <- 0 # set attempt counter
while(is.na(temp$lon) & attempt < 5) {
temp <- geocode(c, source = "dsk")
attempt <- attempt + 1
cat(c, attempt, ifelse(!is.na(temp[[1]]), "success", "failure"), "\n") # print status
Sys.sleep(runif(1)) # sleep for random 0-1 seconds
}
# write to dataframe
cities[cities$city == c, -1] <- temp
}
Now, Taras wrote a very convenient piece of code to generate the dotted world map, which I borrowed from his blog:
With both the dot data and the cities’ geocode() coordinates ready, it is high time to visualize the map. Note that I use one geom_point() layer to plot the dots, small and black, and another layer to plot the cities data in transparent red. Taras added a third layer for the cities he had actually lived in; I purposefully did not as I have only lived in the Netherlands and the UK. Note that I again use the convenient here::here() function to save the plot in my current project folder.
I very much like the look of this map and I’d love to see what innovative, other applications you guys can come up with. To copy the code, please look here on RPubs. Do share your personal creations and also remember to take a look at Taras original blog!
Apparently, I was not the only geek who decided to celebrate the 20th anniversary of the Harry Potter saga with statistical analysis. Students Moritz Haine and Markus Dienstknecht of the Data Science for Decision Making Master at Maastricht University started their own celebratory project as part of a course Information Retrieval and Text Mining.
Students in previous years looked at for example Lord of the Rings, Star Wars and Game of Thrones. However, to our surprise, Harry Potter was missing. Since the books are about magic, we decided it would be interesting to identify all of the spells and the wizards that cast the most spells
Moritz Haine
From the books, the students extracted 41 different wizards, 64 different spells and 253 spells. Moritz points out that they could only include spoken spells, even though the most powerful wizards can also cast spells without naming them. They expect this might be the reason why Dumbledore and Voldemort are not ranked as high. At the end of their project, Moritz and Markus visualized their results in a spell-character mapping.
A network mapping of the characters and spells casted in the Harry Potter saga [original]This is the latest addition to my collection of Harry Potter analyses, to which a similar, interactive web application of spell usage was added only last week.
I would like to demonstrate how regular expressions can be used to retrieve (sub)strings that follow a specific format. We could use regex to examine, for instance, when, and by whom, which magical spells are cast.
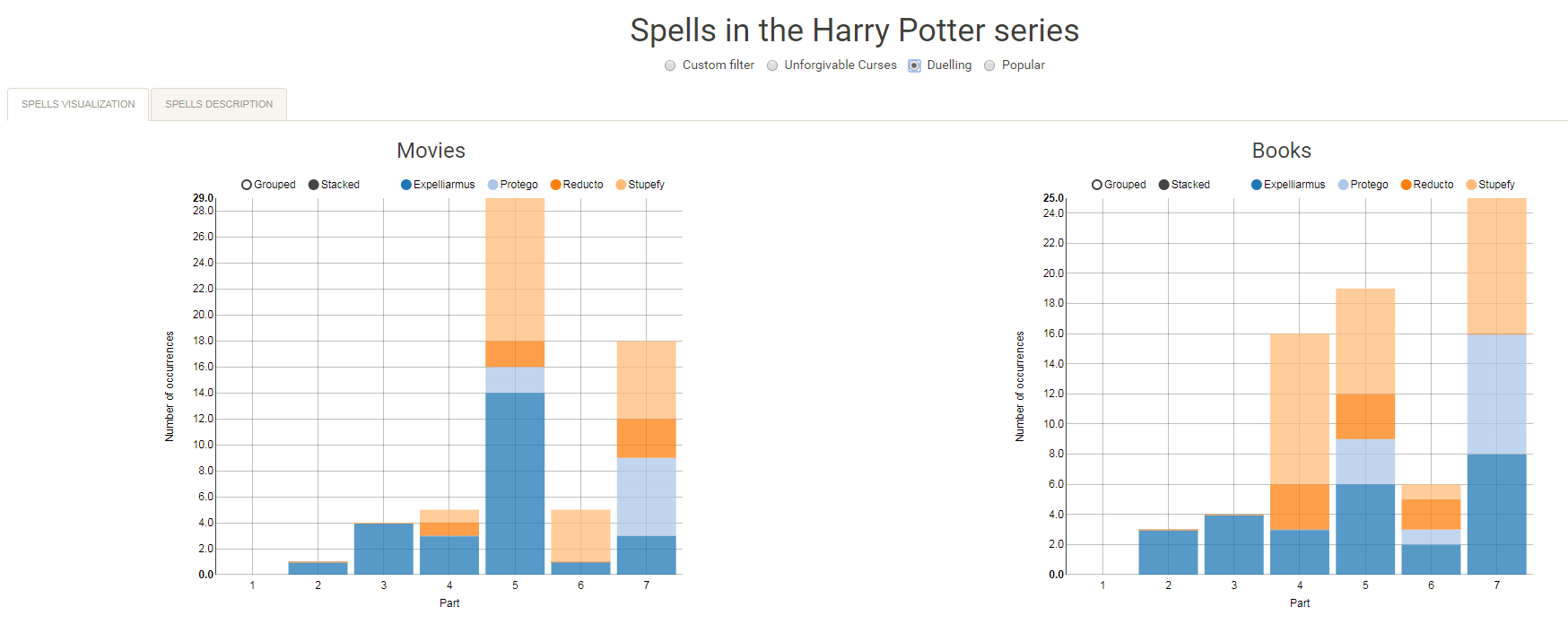
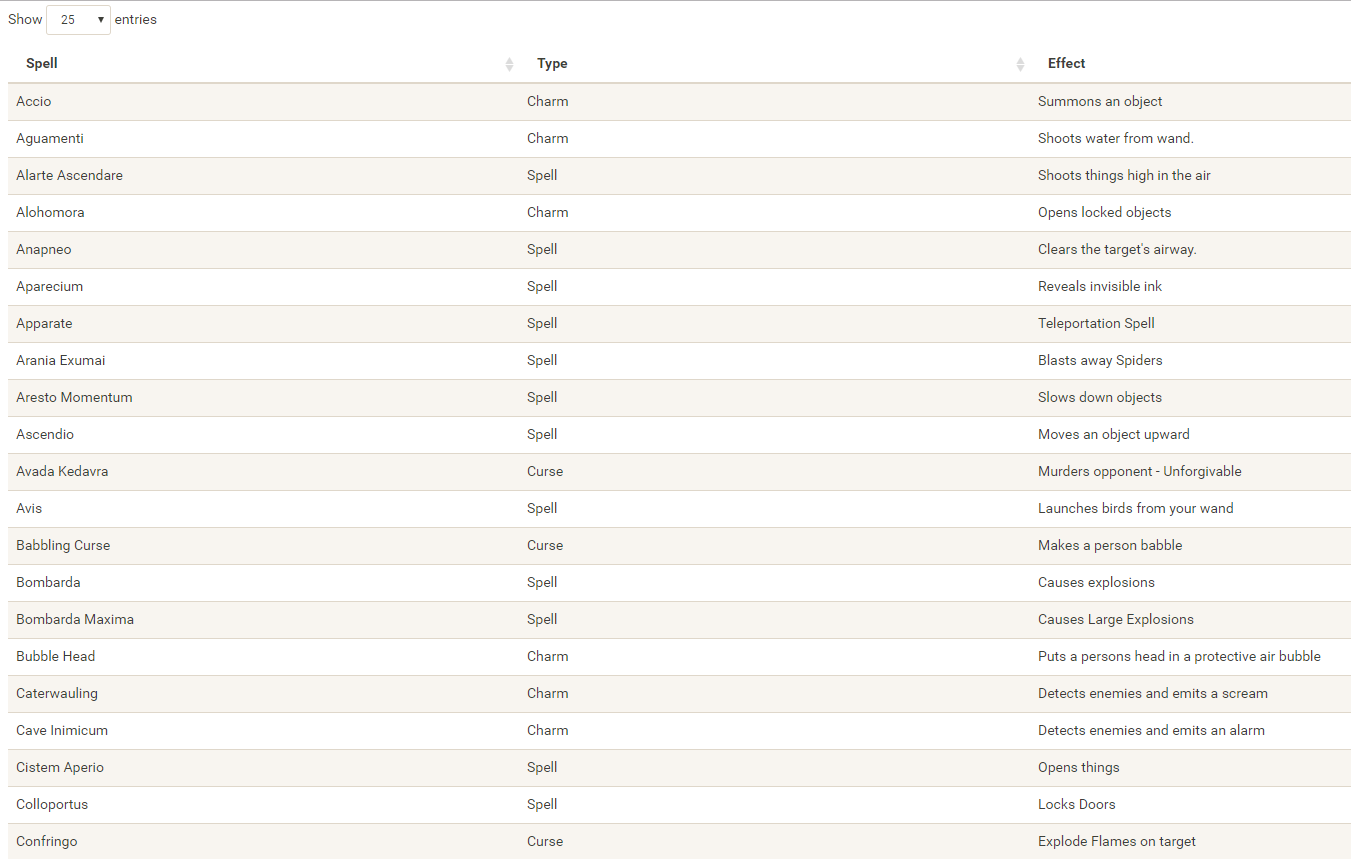
Well, Prusinowskik (real name unknown) beat me to it, and how! S/He formed a comprehensive list of all spells found in the Harry Potter saga (see below), and categorized these into “spells“, “charms“, and “curses“, and into “popular“, “dueling” and “unforgivable” purposes. Next, Prusinowskik built an interactive Shiny application with lovely JavaScript graphs (package: rCharts) for us to discover precisely when during the saga which spells are cast (see also below). Moreover, the analysis was repeated for both the books and the movies.
Truly excellent work Prusinowskik! The Shiny app can be found here.
Past weekend, I visited the casino with some friends. Of all games, we enjoy North-American-style Baccarat the most. This type of Baccarat is often called Punto Banco. In short, Punto Banco is a card game in which two hands compete: the “player” and the “banker“. During each coup (a round of play), both hands get dealt either 2 or 3 cards, depending on a complex drawing schema, and all cards have a certain value. Put simply, the hand with the highest total value of cards wins the coup, after which a new one starts. Before each coup, gamblers may bet which of the hands will win. Neither hand is in any way associated with the actual house or player/gambler, so bets may be placed on both. All in all, three different bets can be placed in a game of Punto Banco:
The player hand has the highest total value, in which case the player wins (Punto);
The banker hand has the highest total value, in which case the banker wins (Banco);
The player and banker hands have equal total value, in which case there is a tie (Egalité).
If a gambler correctly bets either Punto or Banco, their bets get a 100% payoff. However, a house tax will often be applied to Banco wins. For instance, Banco wins may only pay off 95% or specific Banco wins (e.g., total card value of 5) may pay off less (e.g., 50%). Depending on house rules, a correct bet on a tie (Egalité) will pay off either 800% or 900%. A wrong bet on Punto or Banco stands in case Egalité is dealt. In all other cases of wrong bets, the house takes the money.
My friends and I like Punto Banco because it is completely random but seems “gameable”. Punto Banco is played with six or eight decks so there is no way to know which cards will be next. Moreover, the card-drawing rules are quite complex, so you never really know what’s going to happen. Sometimes both Punto and Banco get only two cards, at other times, the hand you bet on will get its third card, which might just turn things around. Punto Banco’s perceived gameability comes through our human fallacies to see patterns in randomness. Often, casino’s will place a monitor with the last fifty-so results (see below) to tempt gamblers to (erroneously) spot and bet on patterns. Alternatively, you might think it’s smart to bet against the table (play Punto when everybody else goes for Banco) or play on whatever bet won last hand. As the hands are dealt quite quickly in succession, and the minimal bet is often 10+ euro/dollar, Punto Banco is a quick way to find out how lucky you are.
Examples of Baccarat monitors, often placed next to a table.
So back to last weekend’s trip to the casino. Unfortunately, my friends and I lost quite some money at the Punto Banco table. We know the house has an edge (though smaller than in other games) but normally we are quite lucky. We often discuss what would be good strategies to minimize this houses’ edge. Obviously, you want to play as few games as possible, but that’s as far as we got in terms of strategy. Normally, we just test our luck and randomly bet Punto or Banco, and sparsely on Egalité.
As a statistical programmer, I thought it might be interesting to simulate the game and its odds from the bottom up. On the one hand, I wanted to get a sense of how favorable the odds are to the house. On the other hand, I was curious as to what extent strategies may be more or less successful in retaining at least some of your hard-earned cash.
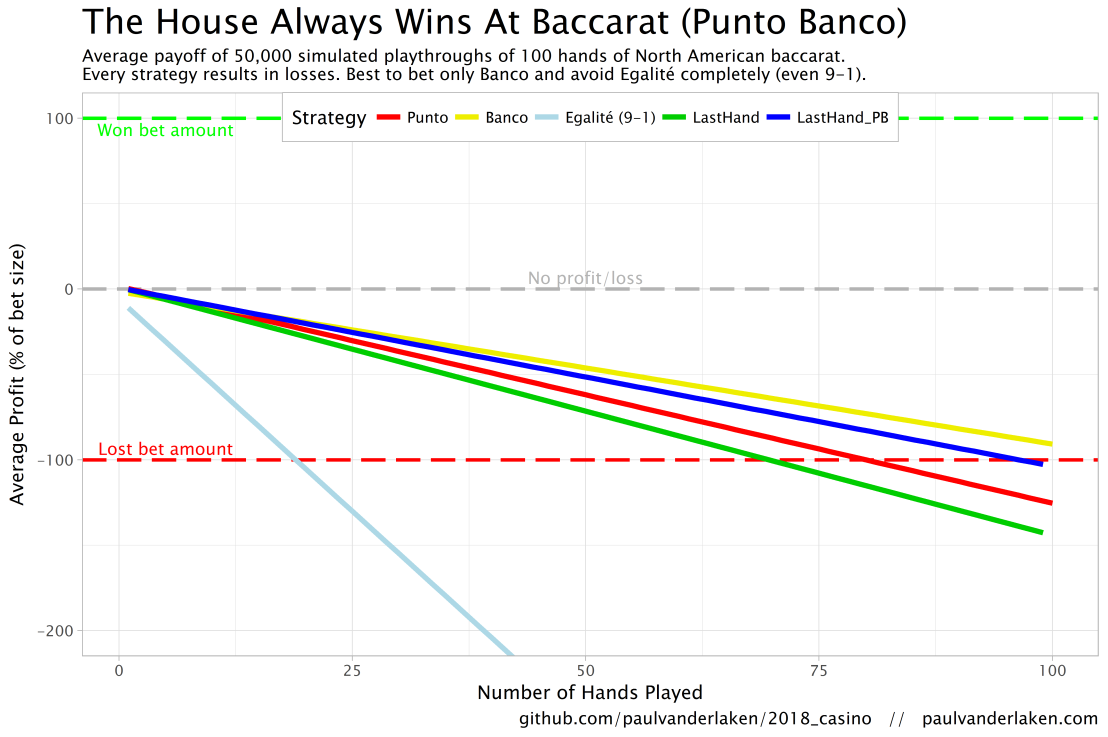
In my simulations, I follow the Holland Casino Punto Banco rules, meaning a six-deck shoe and a Banco win with 5 pays out 50%. I did adopt the more lenient 9-1 payoff for Egalité though. Several hours of programming and some million simulated Baccarat hands later, here are the results:
Do not play Baccarat / Punto Banco if you do not want to lose your money. Obviously, it’s best to not set foot in the casino if you can’t afford to lose some money. However, I eagerly pay for the entertainment value I get from it.
You lose least if you stick to Banco. Despite having only a 50% payoff when Banco wins with 5, the odds are best for Banco due to the drawing rules. Indeed, according to the Wizard of Odds, the house edge for Banco (1.06%) is slightly lower than that of Punto (1.24%).
Whatever you do, do not bet on Egalité. Because most casino’s pay out 8 to 1 in case of a correctly predicted tie, betting on one seems about the worst gambling strategy out there. With a house edge of over 14%, you are better off playing most other games (Wizard of Odds). Although casino’s paying out a tie 9 to 1 decrease the house edge to just below 5%, this is still way worse than playing either Punto or Banco.
The figure below shows the results of the five strategies I tested using 50,000 simulations of 100 consecutive hands. Based on the results, I was reluctant to develop and test other strategies as results look quite straightforward: play Banco. Additionally, Wikipedia cites Thorp (1984, original reference unknown) who suggested that there are no strategies that will really result in any significant player advantage, except maybe for the endgame of a deck, which presumably requires a lot of card counting. If you nevertheless want to test other strategies, please be my guest, here are my five:
Punto: Always bet on Punto.
Banco: Always bet on Banco.
Egalité: Always bet on Egalité.
LastHand: Bet on the outcome of the last hand/coup.
LastHand_PB: Bet on the outcome of the last hand/coup, only if this was Punto or Banco.
The above figure depicts the expected value of each strategy over a series of consecutive hands played. Clearly, the payoff is quite linear, independent of your strategy. The more hands you play, the more you lose. However, also clear is that some strategies outperform others. After 100 hands of Baccarat, playing only Banco will on average result in a total loss below the amount you wager. For example, if you bet 10 euro every hand, you will have a loss of about 9 euro’s after 100 rounds, on average. This is in line with the ~1% house edge reported by the Wizard of Odds. Similarly, betting only Punto will result in a loss of about 130% of the bet amount, which is also conform the ~1.4% house edge reported by the Wizard of Odds. Betting on Punto or Banco based on whichever won last (LastHand_PB) performs somewhere in between these two strategies, losing just over 100% of the bet amount in 100 hands. Your expected losses increase when you just bet on whichever outcome came last, including Egalité, resulting in around ~-150% after 100 hands. This is mainly because betting on Egalité, which seems about the worst strategy ever, will result in a remarkable 493.9% loss after 100 hands.
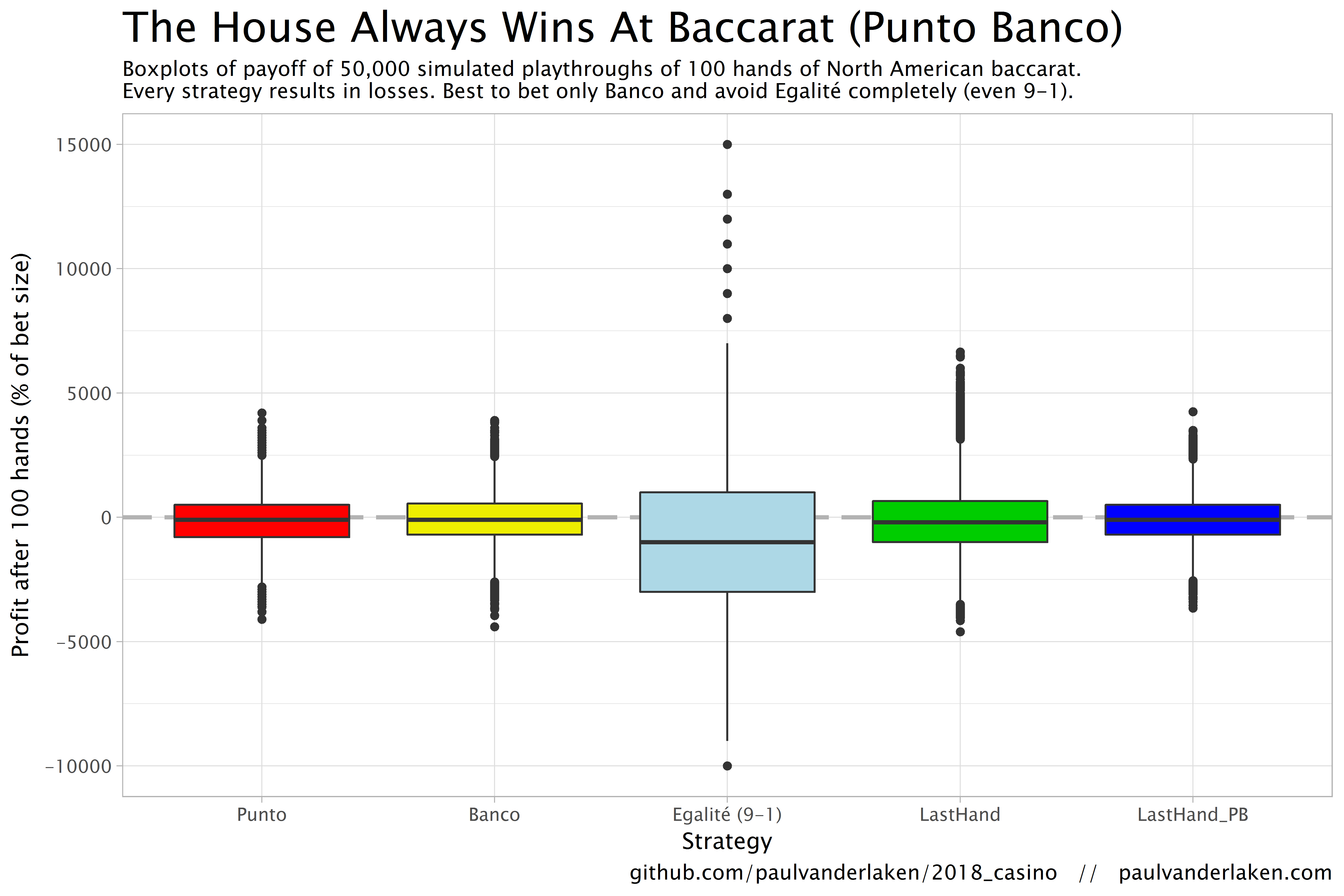
Apart from these average or expected values, I was also interested in the spread of outcomes of our thousands of simulations. Particularly because gamblers on a lucky streak may win much more when betting on Egalité, as the payoff is larger (8-1 or 9-1). The figure below shows that any strategy including Egalité will indeed result in a wider spread of outcomes. Betting on Egalité may thus be a good strategy if you are by some miracle divinely lucky, have information on which cards are coming next, or have an agreement with the dealer (disclaimer: this is a joke, please do not ever bet on Egalité with the intention of making money or try to cheat at the casino).
If you want to know how I programmed these simulations, please visit the associated github repository or reach out. I intend on simulating the payoff for various other casino games in the near future (first up: BlackJack), so if you are interested keep an eye on my website or twitter.
Sentiment analysis is a topic I cover regularly, for instance, with regard to Harry Plotter, Stranger Things, or Facebook. Usually I stick to the three sentiment dictionaries (i.e., lexicons) included in the tidytext R package (Bing, NRC, and AFINN) but there are many more one could use. Heck, I’ve even tried building one myself using a synonym/antonym network (unsuccessful, though a nice challenge). Two lexicons that did become famous are SentiWordNet, accessible via the lexicon R package, and the Loughran lexicon, designed specifically for the analysis of shareholder reports.
Josh Yazman did the world a favor and compared the quality of the five lexicons mentioned above. He observed their validity in relation to the millions of restaurant reviews in the Yelp dataset. This dataset includes both textual reviews and 1 to 5 star ratings. Here’s a summary of Josh’s findings, including two visualizations (read Josh’s full blog + details here):
NRC overestimates the positive sentiment.
AFINN also provides overly positive estimates, but to a lesser extent.
Loughran seems unreliable altogether (on Yelp data).
Bing estimates are accurate as long as texts are long enough (e.g., 200+ words).
SentiWordNet‘s estimates are mostly valid and precise, also on shorter texts, but may include minor outliers.
Sentiment scores by Yelp rating, estimated using each lexicon. [original]The average sentiment score estimated using lexicons, where words are randomly sampled from the Yelp dataset. Note that, although both NRC and Bing scores are relatively positive on average, they also demonstrate a larger spread of scores (which is a good thing if you assume that reviews vary in terms of sentiment). [original]On a more detailed level, David Robinson demonstrated how to uncover performance errors or quality issues in lexicons, in his 2016 blog on the AFINN lexicon. Using only the most common words (i.e., used in 200+ reviews for at least 10 businesses) of the same Yelp dataset, David visualized the inconsistencies between the AFINN sentiment lexicon and the Yelp ratings in two very smart and appealing ways:
Words’ AFINN sentiment score by the average rating of the reviews they used in [original]As the figure above shows, David found a strong positive correlations between the sentiment score assigned to words in the AFINN lexicon and the way they are used in Yelp reviews. However, there are some exception – words that did not have the same meaning in the lexicon and the observed data. Examples of words that seem to cause errors are die and bomb (both negative AFINN scores but used in positive Yelp reviews) or, the other way around, joke and honor (positive AFINN scores but negative meanings on Yelp).
A graph of the frequency with which words are used in reviews, by the average rating of the reviews they occur in, colored for their AFINN sentiment score [original]With the graph above, it is easy to see what words cause inaccuracies. Blue words should be in the upper section of this visual while reds should be closer to the bottom. If this is not the case, a word likely has a different meaning in the lexicon respective to how it’s used on Yelp. These lexicon-data differences become increasingly important as words are located closer to the right side of the graph, which means they more frequently screw up your sentiment estimates. For instance, fine, joke, fuck and hopecause much overestimation of positive sentiment while fresh is not considered in the positive scores it entails and die causes many negative errors.
TL;DR: Sentiment lexicons vary in terms of their quality/performance. If your texts are short (few hundred words) you might be best off using Bing (tidytext). In other cases, opt for SentiWordNet (lexicon), which considers a broader vocabulary. If possible, try to evaluate inaccuracies, outliers, and/or prediction errors via data visualizations.