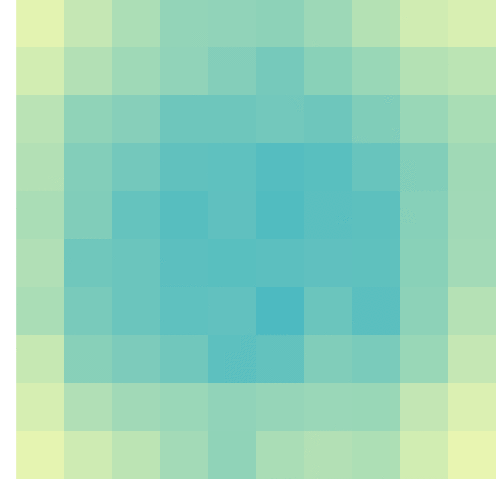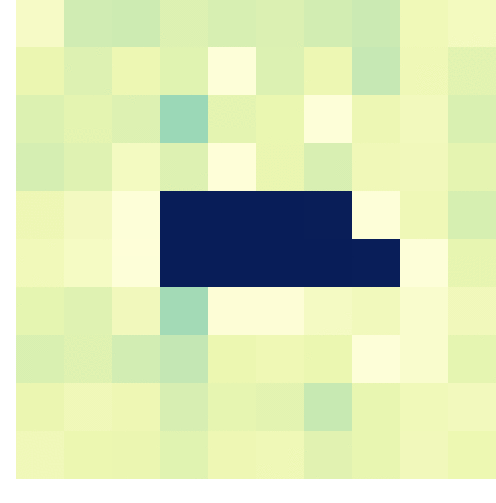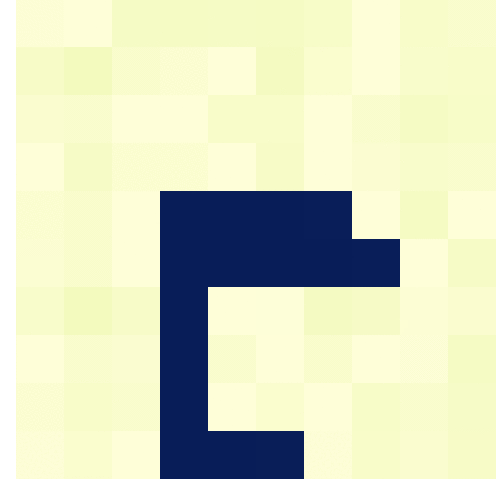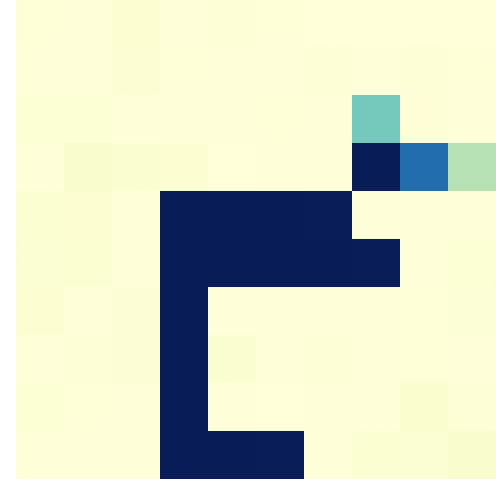Survival of the Best Fit was built by Gabor Csapo, Jihyun Kim, Miha Klasinc, and Alia ElKattan. They are software engineers, designers and technologists, advocating for better software that allows members of the public to question its impact on society.
You don’t need to be an engineer to question how technology is affecting our lives. The goal is not for everyone to be a data scientist or machine learning engineer, though the field can certainly use more diversity, but to have enough awareness to join the conversation and ask important questions.
With Survival of the Best Fit, we want to reach an audience that may not be the makers of the very technology that impact them everyday. We want to help them better understand how AI works and how it may affect them, so that they can better demand transparency and accountability in systems that make more and more decisions for us.
I found that the game provides a great intuitive explanation of how (humas) bias can slip into A.I. or machine learning applications in recruitment, selection, or other human resource management practices and processes.
Note, as Joachin replied below, that the game apparently does not learn from user-input, but is programmed to always result in bias towards blues. I kind of hoped that there was actually an algorithm “learning” in the backend, and while the developers could argue that the bias arises from the added external training data (you picked either Google, Apple, or Amazon to learn from), it feels like a bit of a disappointment that there is no real interactivity here.
[Awful A.I.] aims to track all of them. We hope that Awful AI can be a platform to spur discussion for the development of possible contestational technology (to fight back!).
The Awful A.I. list contains a few dozen applications of machine learning where the results were less than optimal for several involved parties. These AI solutions either resulted in discrimination, disinformation (fake news), mass surveillance, or severely violate privacy or ethical issues in many other ways.
We’ve all heard of Cambridge Analytica, but there are many more on this Awful A.I. list:
Deep Fakes – Deep Fakes is an artificial intelligence-based human image synthesis technique. It is used to combine and superimpose existing images and videos onto source images or videos. Deepfakes may be used to create fake celebrity pornographic videos or revenge porn. [AI assisted fake porn][CNN Interactive Report]
Social Credit System – Using a secret algorithm, Sesame credit constantly scores people from 350 to 950, and its ratings are based on factors including considerations of “interpersonal relationships” and consumer habits. [summary][Foreign Correspondent (video)][travel ban]
SenseTime & Megvii– Based on Face Recognition technology powered by deep learning algorithm, SenseFace and Megvii provides integrated solutions of intelligent video analysis, which functions in target surveillance, trajectory analysis, population management. [summary][forbes][The Economist (video)]
David Dao is a PhD student at DS3Lab — the computer science dpt. of Zurich — and maintains the awful AI list. The cover photo was created by LargeStupidity on Drawception
A while back I discovered this free game called Screeps: an RTS colony-simulation game specifically directed AI programmers. I was immediately intrigued by the concept, but it took me a while to find the time and courage to play. When I finally got to playing though, I lost myself in the game for several days on end.
Screeps means “scripting creeps.”
It’s an open-source sandbox MMO RTS game for programmers, wherein the core mechanic is programming your units’ AI. You control your colony by writing JavaScript which operate 24/7 in the single persistent real-time world filled by other players on par with you.
Basically, screeps is very little game. You start with in a randomly generated canyon of some 400 by 400 pixels, with nothing more than some basic resources and your base. Nothing fun will happen. Even better, nothing at all will happen. Unless you program it yourself.
As a player, it is your job to “script” your own creeps’ AI. And your buildings AI for that matter. You will need to write a program that makes your base spawn workers. And next those workers will need to be programmed to actually work. You need to direct them to go to the resources, explain them how to mine the resources, when to stop mining, and how to return the mined resources to your base. You will probably also want some soldiers and some other defenses, so those need to be spawned with their own special instructions as well.
Everything needs to be scripted well, as the game (and thus your screeps) runs on special servers, 24/7, so also when you are not playing yourself. Truly your personal, virtual, mini-AI colony.
The programming mostly occurs in JavaScript. This can be difficult for those like myself who do not know JavaScript, but even I managed to have some basic workers running up and down my screen in a matter of hours. Step by step, you will learn (be forced) to create different worker types (harvesters, builders, repairmen, and even some stupid soldiers) and even some basic colony management scripts (spawning workers, spending resources, upgrading stuff). In the mean time, you will silently learn some JavaScript while playing. As I put in more and more hours, I could even see how to improve on my earlier scripts. This makes screeps a fun and rewarding gaming and learning experience.
Do expect to run into frustrations though! If you’re no JavaScript expert you will personally create a lot of bugs. Of which the game by default send you messages, as your colony will get stuck overnight. Moreover, you will likely need to Google every single thing you want to do at the start. I found great help in this YouTube tutorial to get me started. Finally, you are only under nooby-protection for the first so-many hours, after which you will quickly get slaughtered by all the advanced multi-CPU players on the servers.
Heck, it was fun while it lasted : )
PS. I read here that, using WebAssembly, one could also compile code written in different languages and run it in Screeps: C/C++ or Rust code, as well as other supported languages.
Past days, I discovered this series of blogs on how to win the classic game of Battleships (gameplay explanation) using different algorithmic approaches. I thought they might amuse you as well : )
The story starts with this 2012 Datagenetics blog where Nick Berry constrasts four algorithms’ performance in the game of Battleships. The resulting levels of artificial intelligence (AI) seem to compare respectively to a distracted baby, two sensible adults, and a mathematical progidy.
The first, stupidest approach is to just take Random shots. The AI resulting from such an algorithm would just pick a random tile to shoot at each turn. Nick simulated 100 million games with this random apporach and computed that the algorithm would require 96 turns to win 50% of games, given that it would not be defeated before that time. At best, the expertise level of this AI would be comparable to that of a distracted baby. Basically, it would lose from the average toddler, given that the toddler would survive the boredom of playing such a stupid AI.
A first major improvement results in what is dubbed the Hunt algorithm. This improved algorithm includes an instruction to explore nearby spaces whenever a prior shot hit. Every human who has every played Battleships will do this intuitively. A great improvement indeed as Nick’s simulations demonstrated that this Hunt algorithm completes 50% of games within ~65 turns, as long as it is not defeated beforehand. Your little toddler nephew will certainly lose, and you might experience some difficulty as well from time to time.
A visual representation of the “Hunting” of the algorithm on a hit [via]
Another minor improvement comes from adding the so-called Parity principle to this Hunt algorithm (i.e., Nick’s Hunt + Parity algorithm). This principle instructs the algorithm to take into account that ships will always cover odd as well as even numbered tiles on the board. This information can be taken into account to provide for some more sensible shooting options. For instance, in the below visual, you should avoid shooting the upper left white tile when you have already shot its blue neighbors. You might have intuitively applied this tactic yourself in the past, shooting tiles in a “checkboard” formation. With the parity principle incorporated, the median completion rate of our algorithm improves to ~62 turns, Nick’s simulations showed.
Now, Nick’s final proposed algorithm is much more computationally intensive. It makes use of Probability Density Functions. At the start of every turn, it works out all possible locations that every remaining ship could fit in. As you can imagine, many different combinations are possible with five ships. These different combinations are all added up, and every tile on the board is thus assigned a probability that it includes a ship part, based on the tiles that are already uncovered.
Computing the probability that a tile contains a ship based on all possible board layouts [via]
At the start of the game, no tiles are uncovered, so all spaces will have about the same likelihood to contain a ship. However, as more and more shots are fired, some locations become less likely, some become impossible, and some become near certain to contain a ship. For instance, the below visual reflects seven misses by the X’s and the darker tiles which thus have a relatively high probability of containing a ship part.
An example distribution with seven misses on the grid. [via]
Nick simulated 100 million games of Battleship for this probabilistic apporach as well as the prior algorithms. The below graph summarizes the results, and highlight that this new probabilistic algorithm greatly outperforms the simpler approaches. It completes 50% of games within ~42 turns! This algorithm will have you crying at the boardgame table.
Relative performance of the algorithms in the Datagenetics blog, where “New Algorithm” refers to the probabilistic approach and “No Parity” refers to the original “Hunt” approach.
Reddit user /u/DataSnaek reworked this probablistic algorithm in Python and turned its inner calculations into a neat GIF. Below, on the left, you see the probability of each square containing a ship part. The brighter the color (white <- yellow <- red <- black), the more likely a ship resides at that location. It takes into account that ships occupy multiple consecutive spots. On the right, every turn the algorithm shoots the space with the highest probability. Blue is unknown, misses are in red, sunk ships in brownish, hit “unsunk” ships in light blue (sorry, I am terribly color blind).
The probability matrix as a heatmap for every square after each move in the game. [via]
This latter attempt by DataSnaek was inspired by Jonathan Landy‘s attempt to train a reinforcement learning (RL) algorithm to win at Battleships. Although the associated GitHub repository doesn’t go into much detail, the approach is elaborately explained in this blog. However, it seems that this specific code concerns the training of a neural network to perform well on a very small Battleships board, seemingly containing only a single ship of size 3 on a board with only a single row of 10 tiles.
Fortunately, Sue He wrote about her reinforcement learning approach to Battleships in 2017. Building on the open source phoenix-battleship project, she created a Battleship app on Heroku, and asked co-workers to play. This produced data on 83 real, two-person games, showing, for instance, that Sue’s coworkers often tried to hide their size 2 ships in the corners of the Battleships board.
Probability heatmaps of ship placement in Sue He’s reinforcement learning Battleships project [via]
Next, Sue scripted a reinforcement learning agent in PyTorch to train and learn where to shoot effectively on the 10 by 10 board. It became effective quite quickly, requiring only 52 turns (on average over the past 25 games) to win, after training for only a couple hundreds games.
The performance of the RL agent at Battleships during the training process [via]
However, as Sue herself notes in her blog, disappointly, this RL agent still does not outperform the probabilistic approach presented earlier in this current blog.
Reddit user /u/christawful faced similar issues. Christ (I presume he is called) trained a convolutional neural network (CNN) with the below architecture on a dataset of Battleships boards. Based on the current board state (10 tiles * 10 tiles * 3 options [miss/hit/unknown]) as input data, the intermediate convolutional layers result in a final output layer containing 100 values (10 * 10) depicting the probabilities for each tile to result in a hit. Again, the algorithm can simply shoot the tile with the highest probability.
Christ’s convolutional neural network architecture for Battleships [via]
Christ was nice enough to include GIFs of the process as well [via]. The first GIF shows the current state of the board as it is input in the CNN — purple represents unknown tiles, black a hit, and white a miss (i.e., sea). The next GIF represent the calculated probabilities for each tile to contain a ship part — the darker the color the more likely it contains a ship. Finally, the third picture reflects the actual board, with ship pieces in black and sea (i.e., miss) as white.
As cool as this novel approach was, Chris ran into the same issue as Sue, his approach did not perform better than the purely probablistic one. The below graph demonstrates that while Christ’s CNN (“My Algorithm”) performed quite well — finishing a simulated 9000 games in a median of 52 turns — it did not outperform the original probabilistic approach of Nick Berry — which came in at 42 turns. Nevertheless, Chris claims to have programmed this CNN in a couple of hours, so very well done still.
The performance of Christ’s Battleship CNN compared to Nick Berry’s original algorithms [via]
Interested by all the above, I searched the web quite a while for any potential improvement or other algorithmic approaches. Unfortunately, in vain, as I did not find a better attempt than that early 2012 Datagenics probability algorithm by Nick.
Surely, with today’s mass cloud computing power, someone must be able to train a deep reinforcement learner to become the Battleship master? It’s not all probability right, there must be some patterns in generic playing styles, like Sue found among her colleagues. Or maybe even the ability of an algorithm to adapt to the opponent’s playin style, as we see in Libratus, the poker AI. Maybe the guys at AlphaGo could give it a shot?
For starters, Christ’s provided some interesting improvements on his CNN approach. Moreover, while the probabilistic approach seems the best performing, it might not the most computationally efficient. All in all, I am curious to see whether this story will continue.
I recently got pointed towards a 2017 paper on bioRxiv that blew my mind: three researchers at the Computational Neuroscience Laboratories at Kyoto, Japan, demonstrate how they trained a deep neural network to decode human functional magnetic resonance imaging (fMRI) patterns and then generate the stimulus images.
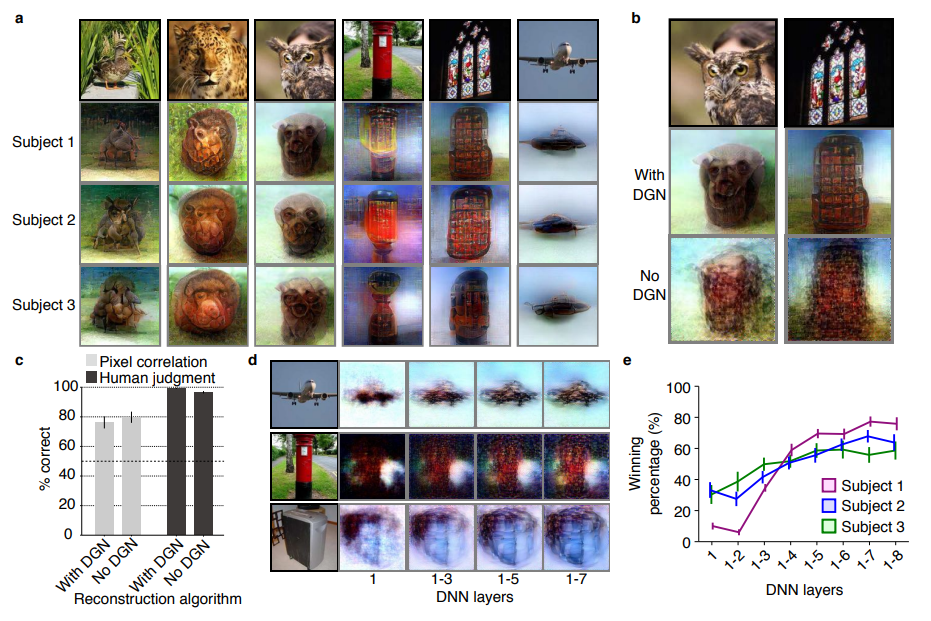
In simple words, the scholars used sophisticated machine learning to reconstruct the photo’s their research particpants saw based on their brain activity… INSANE! The below shows the analysis workflow, and an actual reconstructed image. More reconstructions follow further on.
Figure 1 | Deep image reconstruction. Overview of deep image reconstruction is shown. The pixels’ values of the input image are optimized so that the DNN features of the image are similar to those decoded from fMRI activity. A deep generator network (DGN) is optionally combined with the DNN to produce natural-looking images, in which optimization is performed at the input space of the DGN. [original]Three healthy young adults participated in two types of experiments: an image presentation experiment and an imagery experiment.
In the image presentation experiments, participants were presented with several natural images from the ImageNet database, with 40 images geometrical shapes, and with 10 images of black alphabetic characters. These visual stimuli were rear-projected onto a screen in an fMRI scanner bore. Data from each subject were collected over multiple scanning sessions spanning approximately 10 months. Images were flashed at 2 Hz for several seconds. In the imagery experiment, subjects were asked to visually imagine / remember one of 25 images of the presentation experiments. Subjects were
required to start imagining a target image after seeing some cue words.
In both experimental setups, fMRI data were collected using 3.0-Tesla Siemens MAGNETOM Verio scanner located at the Kokoro Research Center, Kyoto University.
The results, some of which I copied below, are plainly amazing.
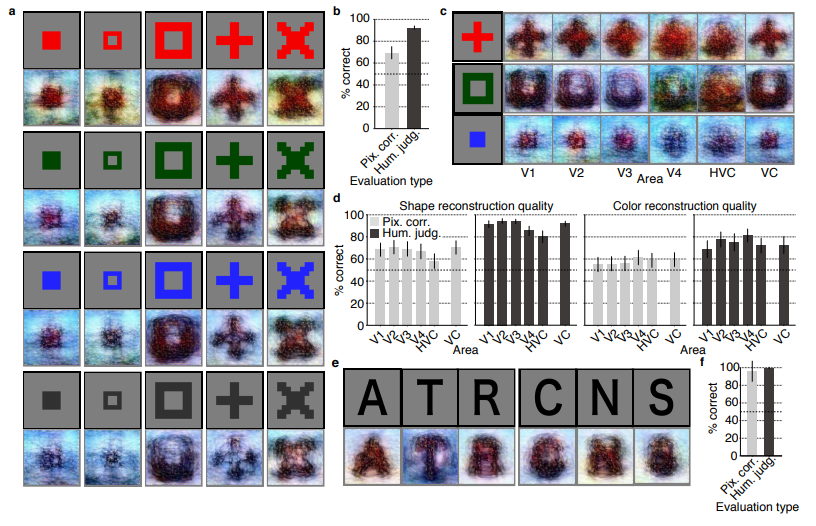
Figure 2 | Seen natural image reconstructions. Images with black and gray frames show presented and reconstructed images, respectively (reconstructed from VC activity). a) Reconstructions utilizing the DGN (using DNN1–8). Three reconstructed images correspond to reconstructions from three subjects. b) Reconstructions with and without the DGN (DNN1–8). The first, second, and third rows show presented images, reconstructions with and without the DGN, respectively. c) Reconstruction quality of seen natural images (error bars, 95% confidence interval (C.I.) across samples; three subjects pooled; chance level, 50%). d) Reconstructions using different combinations of DNN layers (without the DGN). e) Subjective assessment of reconstructions from different combinations of DNN layers (error bars, 95% C.I. across samples) [original]Figure 3 | Seen artificial shape reconstructions. Images with black and gray frames show presented and reconstructed images (DNN 1–8, without the DGN). a) Reconstructions for seen colored artificial shapes (VC activity). b, Reconstruction quality of colored artificial shapes. c) Reconstructions of colored artificial shapes obtained from multiple visual areas. d) Reconstruction quality of shape and colors for different visual areas. e) Reconstructions of alphabetical letters. f) Reconstruction quality for alphabetical letters. For b, d, f, error bars indicate 95% C.I. across samples (three subjects pooled; chance level, 50%) [original] Supplementary Figure 2 | Other examples of natural image reconstructions obtained with the DGN. Images with black and gray frames show presented and reconstructed images, respectively (reconstructed from VC activity using all DNN layers). Three reconstructed images correspond to reconstructions from three subjects. [original]Supplementary Figure 3 | Reconstructions through optimization processes. Reconstructed images obtained through the optimization processes are shown (reconstructed from VC activity of Subject 1 using all DNN layers and the DGN). Images with black and gray frames show presented and reconstructed images, respectively. [original]There were many more examples of reconstructed images, as well as much more detailed information regarding the machine learning approach and experimental setup, so I strongly advise you check out the orginal paper.
I can’t even imagine what such technology would imply for society… Proper minority report stuff here.
Here’s the abstract as an additional teaser:
Abstract
Machine learning-based analysis of human functional magnetic resonance imaging
(fMRI) patterns has enabled the visualization of perceptual content. However, it has been limited to the reconstruction with low-level image bases (Miyawaki et al., 2008; Wen et al., 2016) or to the matching to exemplars (Naselaris et al., 2009; Nishimoto et al., 2011). Recent work showed that visual cortical activity can be decoded (translated) into hierarchical features of a deep neural network (DNN) for the same input image, providing a way to make use of the information from hierarchical visual features (Horikawa & Kamitani, 2017). Here, we present a novel image reconstruction method, in which the pixel values of an image are optimized to make its DNN features similar to those decoded from human brain activity at multiple layers. We found that the generated images resembled the stimulus images (both natural images and artificial shapes) and the subjective visual content during imagery. While our model was solely trained with natural images, our method successfully generalized the reconstruction to artificial shapes, indicating that our model indeed ‘reconstructs’ or ‘generates’ images from brain activity, not simply matches to exemplars. A natural image prior introduced by another deep neural network effectively rendered semantically meaningful details to reconstructions by constraining reconstructed images to be similar to natural images. Furthermore, human judgment of reconstructions suggests the effectiveness of combining multiple DNN layers to enhance visual quality of generated images. The results suggest that hierarchical visual information in the brain can be effectively combined to reconstruct perceptual and subjective images.
In the video below, one of my favorite YouTube channels (Two Minute Papers) discusses a new super resolution project where academic scholars taught a neural network to improve low quality photo’s. The researchers took the same picture with multiple camera’s of varying quality and allowed a neural network to learn how the lowest quality pictures can be adjusted to more closely resemble their high quality counterparts. A very interesting approach and the results are just mind-boggling: