In a world where data really matters, we all want to create effective charts. But data visualization is rarely taught in schools, or covered in on-the-job training. Most of us learn as we go along, and therefore we often make choices or mistakes that confuse and disorient our audience. From overcomplicating or overdressing our charts, to conveying an entirely inaccurate message, there are common design pitfalls that can easily be avoided. We’ve put together these pointers to help you create simpler charts that effectively get across the meaning of your data.
Based on work by experts such as Stephen Few, Dona Wong, Albert Cairo, Cole Nussbaumer Knaflic, and Andy Kirk, the authors at Geckoboard wrote down a list of recommendations which I summarize below:
Present the facts
Start your axis at zero whenever possible, to prevent misinterpretation. Particularly bar charts.
The width and height of line and scatter plots influence its messages.
Area and size are hard to interpret. Hence, there’s often a better alternative to the pie chart. Read also this.
2018 seemed to be the year of challengesgoing viral on the web. Most of them were plain stupid and/or dangerous. However, one viral challenge I did like: #100DaysOfCode
1. Code minimum an hour every day for the next 100 days.
2. Tweet your progress every day with the #100DaysOfCode hashtag.
3. Each day, reach out to at least two people on Twitter who are also doing the challenge
Many (aspiring) programming professionals competed in this challenge, sharing their learning journeys in domains from web development, machine learning, or data visualization.
With this blog, I wanted to share two of those learning journeys that stood out for me.
Machine learning
First, there’s Avik Jain’s 100 days of Machine Learning code repository on Github. Avik’s repository contains all learning activities he followed during the 53 days of programming he completed. Some of Avik’s entries really stood out, and I particularly liked his educational infographics:
Just look at the wonderful design and visual aids on this decision tree for dummies infographic, pseudocode and all:
Day 23: Decision trees for dummies. This just looks fabulous right?!
Although Avik didn’t seem to have completed the full 100 days, many others did.
Data visualization
I have blogged about Hannah Yan Han‘s 100 days of code project before, but she definately deserves another mention here. Her 100 days revolved around data science, data visualization, and storytelling using both R and Python. You can find her #100DaysOfCode Medium page here, and her associated Github repository here.
For example, one day Hannah explored where instant noodles come from, how they are served, and whether people like them or not.
What I found so great about Hannah’s project is that she picked a novel dataset every couple of days. Moreover, she used a extremely large variety of different visualization formats. All visuals were equally beautiful, but Hannah made sure to pick the right one for the purpose she was trying to serve. If you are interested in data visualization, you seriously should check out Hannah’s 100DaysOfCode Medium page.
GIFs or animations are rising quickly in the data visualization world (see for instance here).
However, in my personal experience, they are not as widely used in business settings. You might even say animations are frowned by, for instance, LinkedIn, which removed the option to even post GIFs on their platform!
Nevertheless, animations can be pretty useful sometimes. For instance, they can display what happens during a process, like a analytical model converging, which can be useful for didactic purposes. Alternatively, they can be great for showing or highlighting trends over time.
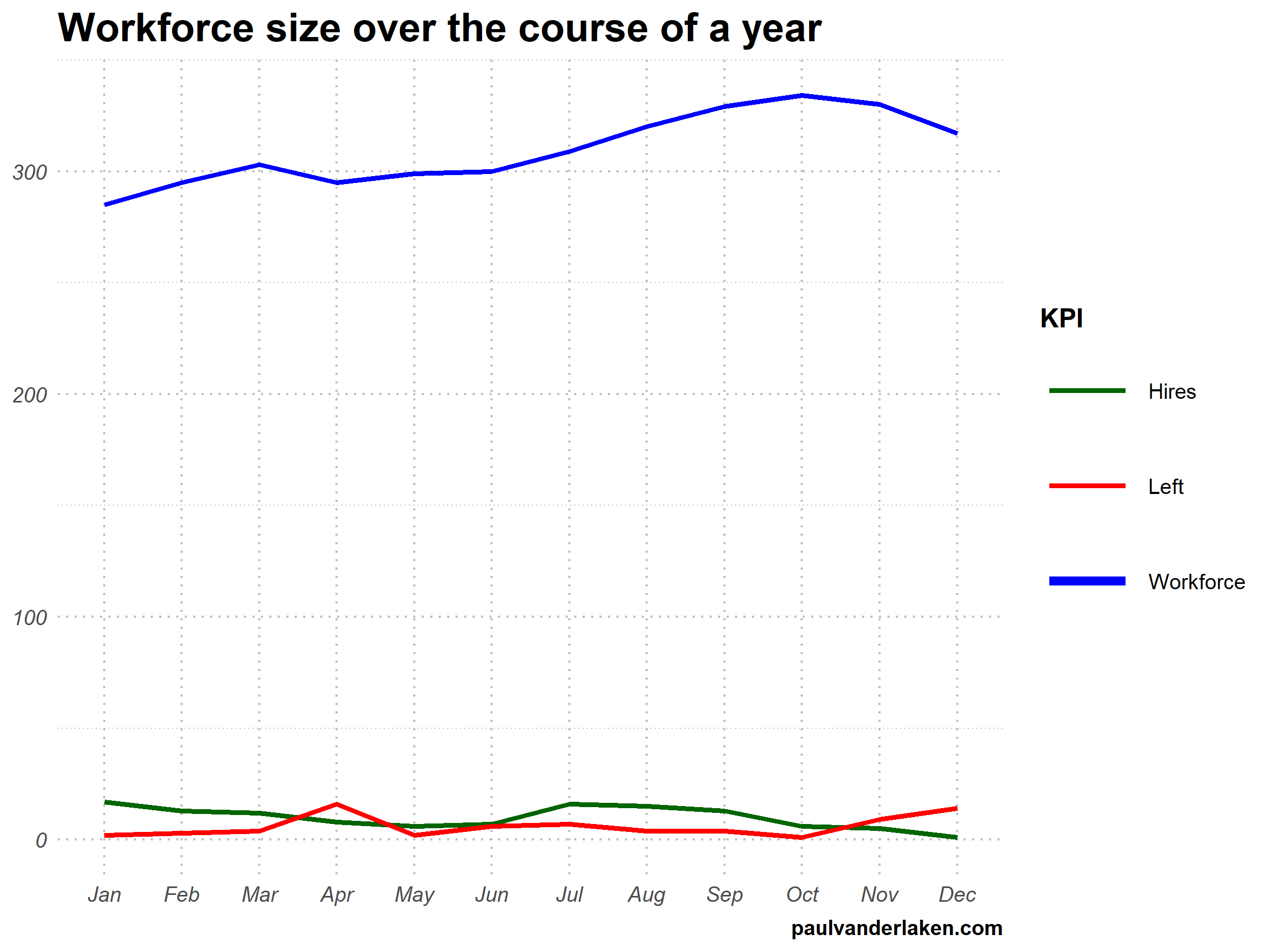
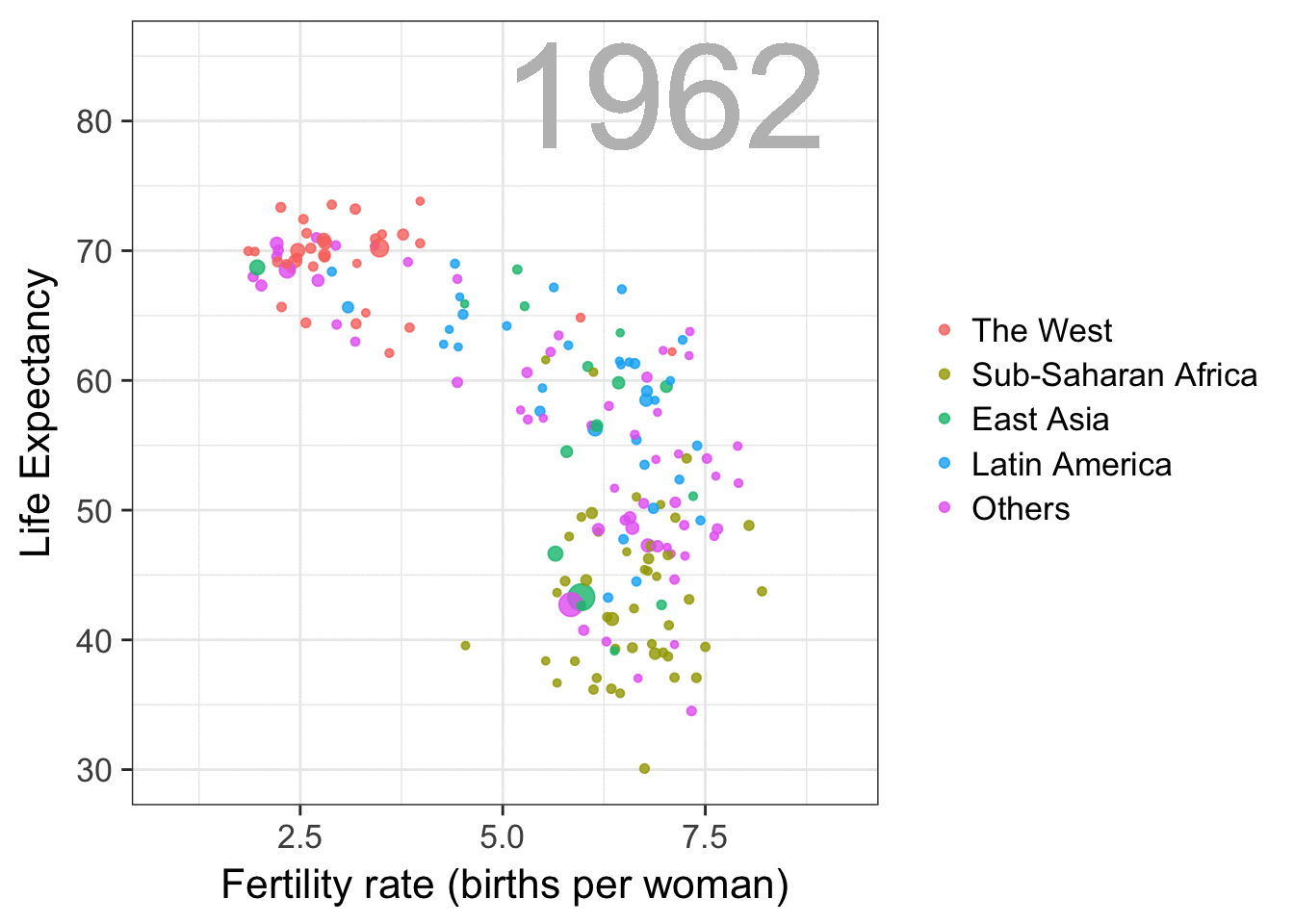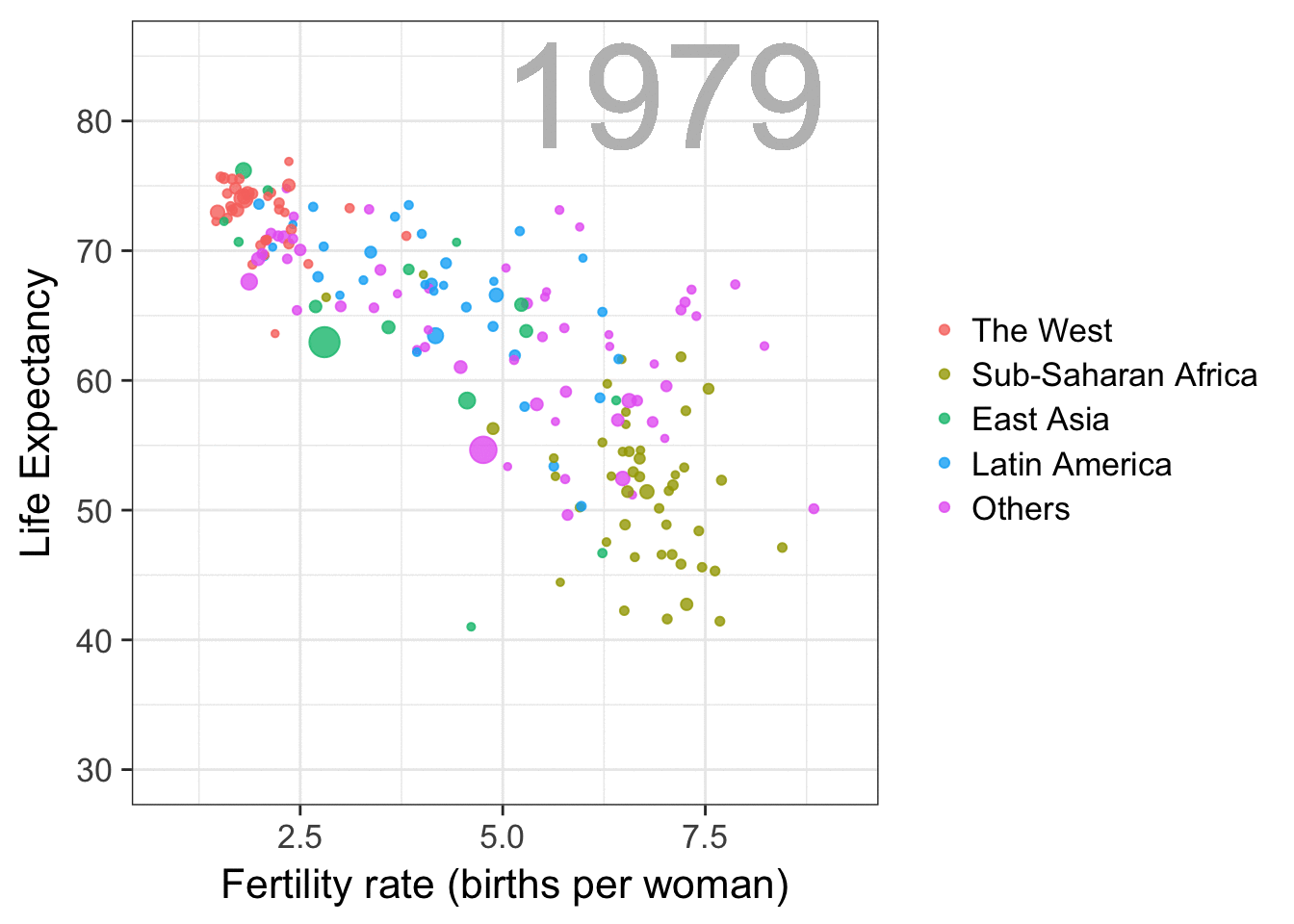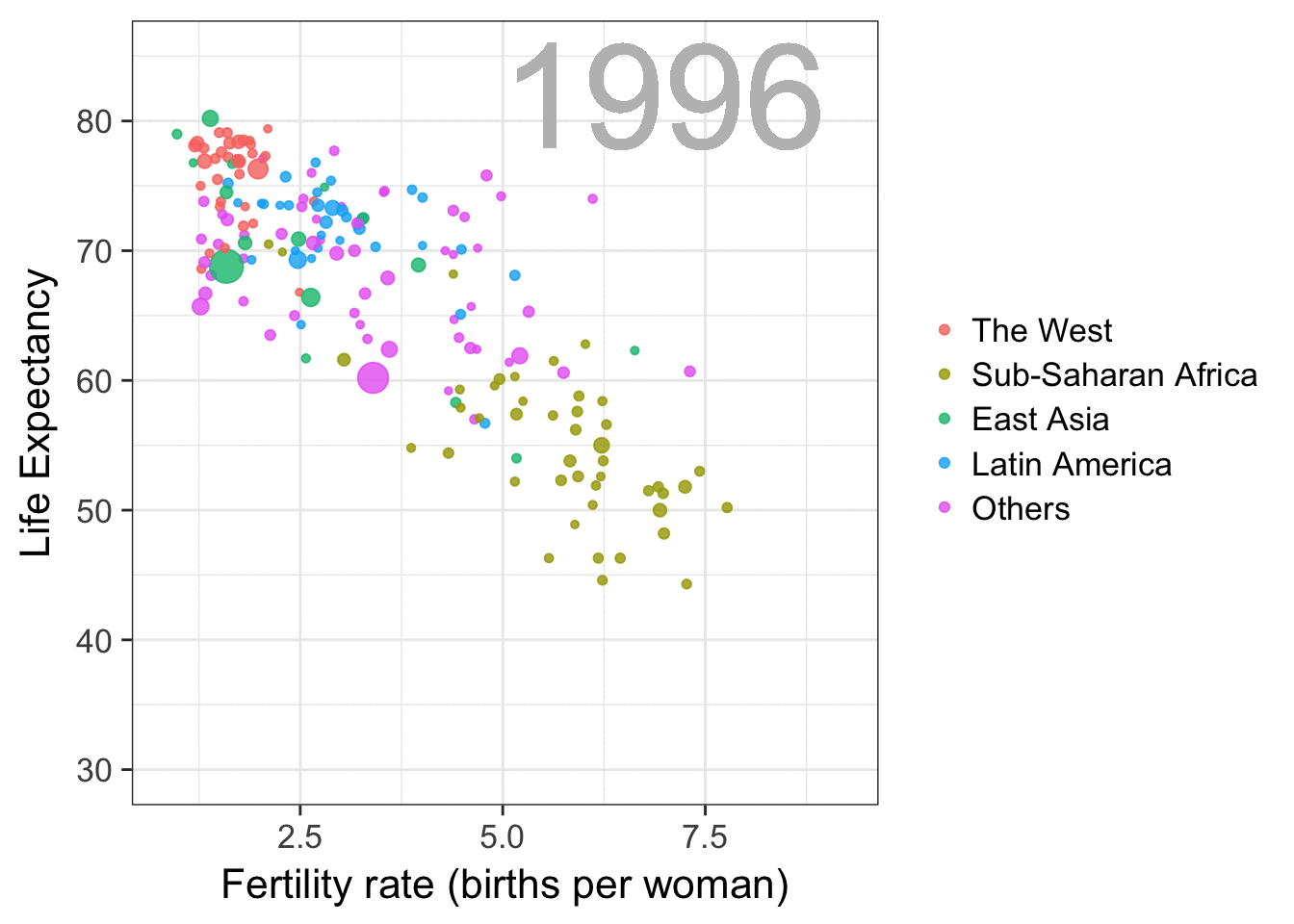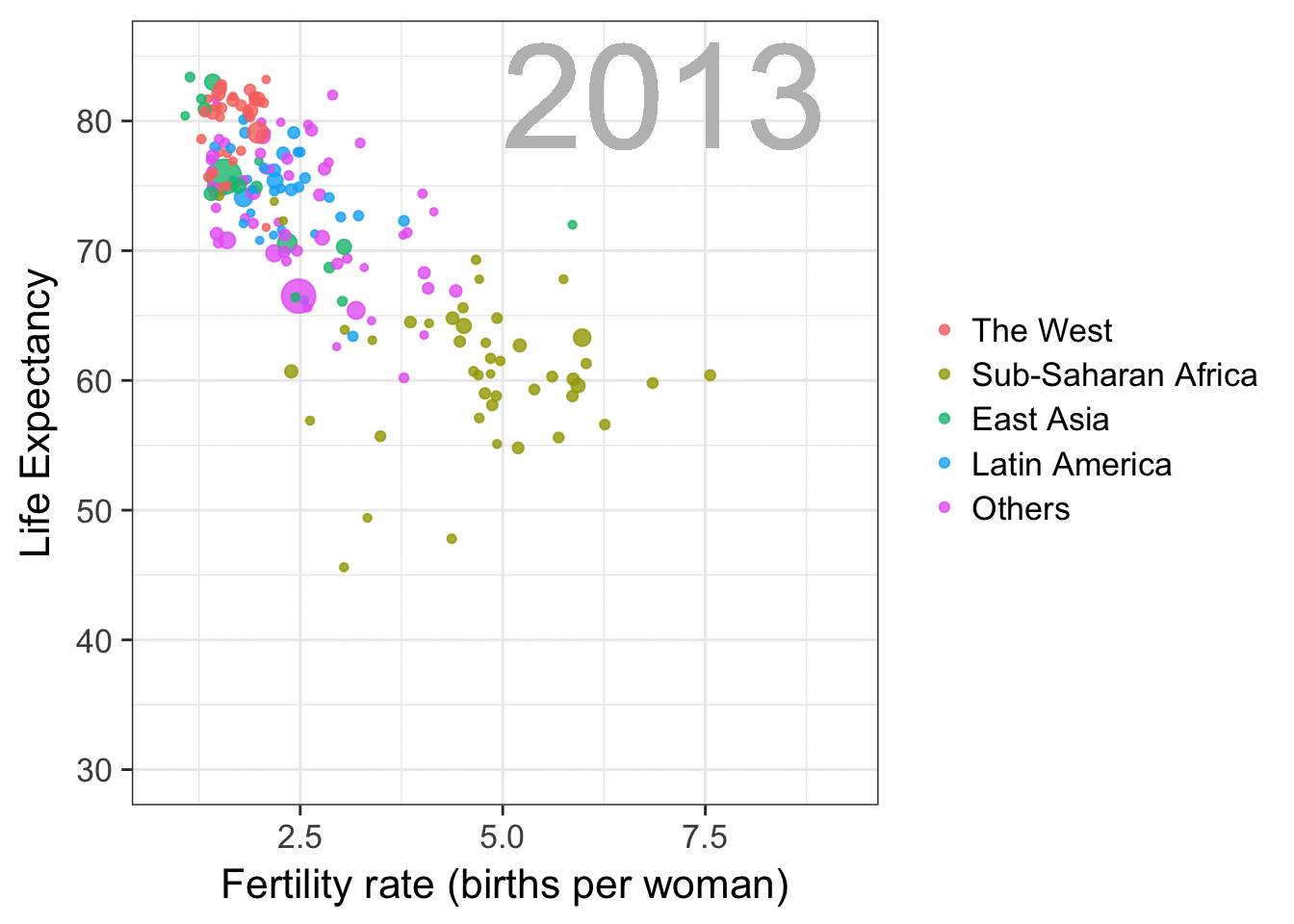
I am curious what you think are the pro’s and con’s of animations. Below, I posted two visualizations of the same data. The data consists of the simulated workforce trends, including new hires and employee attrition over the course of twelve months.
versus
Would you prefer the static, or the animated version? Please do share your thoughts in the comments below, or on the respective LinkedIn and Twitter posts!
Want to reproduce these plots? Or play with the data? Here’s the R code:
# transform to long format wf_long <- gather(wf, key = "variable", value = "value", -month) capitalize the name of variables wf_long$variable <- capitalize_string(wf_long$variable)
# VISUALIZE & ANIMATE #### # draw workforce plot ggplot(wf_long, aes(x = month, y = value, group = variable)) + geom_line(aes(col = variable, size = variable == "workforce")) + scale_color_manual(values = COLORS) + scale_size_manual(values = c(LINE_SIZE2, LINE_SIZE1), guide = FALSE) + guides(color = guide_legend(override.aes = list(size = c(rep(LINE_SIZE2, 2), LINE_SIZE1)))) + # theme_PVDL() + labs(x = NULL, y = NULL, color = "KPI", caption = "paulvanderlaken.com") + ggtitle("Workforce size over the course of a year") + NULL -> workforce_plot
Browse through hundreds of helpful data visualization tools, programs, and services. All neatly organized by Andy Kirk in categories: data handling, applications, programming, web-based, qualitative, mapping, specialist, and colour. What a great repository!
I’ve mentioned before that I dislike wordclouds (for instance here, or here) and apparently others share that sentiment. In his recent Medium blog, Daniel McNichol goes as far as to refer to the wordcloud as the pie chart of text data! Among others, Daniel calls wordclouds disorienting, one-dimensional, arbitrary and opaque and he mentions their lack of order, information, and scale.
Wordcloud of the negative characteristics of wordclouds, via Medium
Instead of using wordclouds, Daniel suggests we revert to alternative approaches. For instance, in their Tidy Text Mining with R book, Julia Silge and David Robinson suggest using bar charts or network graphs, providing the necessary R code. Another alternative is provided in Daniel’s blog: the chatterplot!
While Daniel didn’t invent this unorthodox wordcloud-like plot, he might have been the first to name it a chatterplot. Daniel’s chatterplot uses a full x/y cartesian plane, turning the usually only arbitrary though exploratory wordcloud into a more quantitatively sound, information-rich visualization.
R package ggplot’s geom_text() function — or alternatively ggrepel‘s geom_text_repel() for better legibility — is perfectly suited for making a chatterplot. And interesting features/variables for the axis — apart from the regular word frequencies — can be easily computed using the R tidytext package.
Here’s an example generated by Daniel, plotting words simulatenously by their frequency of occurance in comments to Hacker News articles (y-axis) as well as by the respective popularity of the comments the word was used in (log of the ranking, on the x-axis).
[CHATTERPLOTs are] like a wordcloud, except there’s actual quantitative logic to the order, placement & aesthetic aspects of the elements, along with an explicit scale reference for each. This allows us to represent more, multidimensional information in the plot, & provides the viewer with a coherent visual logic& direction by which to explore the data.
I highly recommend the use of these chatterplots over their less-informative wordcloud counterpart, and strongly suggest you read Daniel’s original blog, in which you can also find the R code for the above visualizations.
Today I learned about dygraphs, a fast, flexible open source JavaScript charting library. As everything in JavaScript, the charts produced by dygraphs integrate completely in the webbrowser and are thus very functional and interactive. See, for instance, the below where the graph highlights the y-axis value for both time series in the graph based on the x-axis value of my mouse location (January 24 2009). Very cool!
Fortunately, I do know my way around R, and of course someone had already integrated dypgrahs in R in the form of the dygraphs R package. It works like a charm!


























{kind=link}