The repository consists of tools for multiple languages (R, Python, Matlab, Java) and resources in the form of:
Books & Academic Papers
Online Courses and Videos
Outlier Datasets
Algorithms and Applications
Open-source and Commercial Libraries/Toolkits
Key Conferences & Journals
Outlier Detection (also known as Anomaly Detection) is an exciting yet challenging field, which aims to identify outlying objects that are deviant from the general data distribution. Outlier detection has been proven critical in many fields, such as credit card fraud analytics, network intrusion detection, and mechanical unit defect detection.
A friend of mine pointed me to this great website where you can interactively practice and learn new programming skills by working through small coding challenges, like making a game.
CodinGame.com is an gamified learning community and website that allows you to learn new concepts by solving fun challenges. Pick from over 25 programming languages, including Python, C, C++, C#, Java, JavaScript, Go, and many more. In a matter of hours, you will work on hot programming topics, discover new languages, algorithms, and tricks in courses crafted by top developers.
I found this interesting blog by Guilherme Duarte Marmerola where he shows how the predictions of algorithmic models (such as gradient boosted machines, or random forests) can be calibrated by stacking a logistic regression model on top of it: by using the predicted leaves of the algorithmic model as features / inputs in a subsequent logistic model.
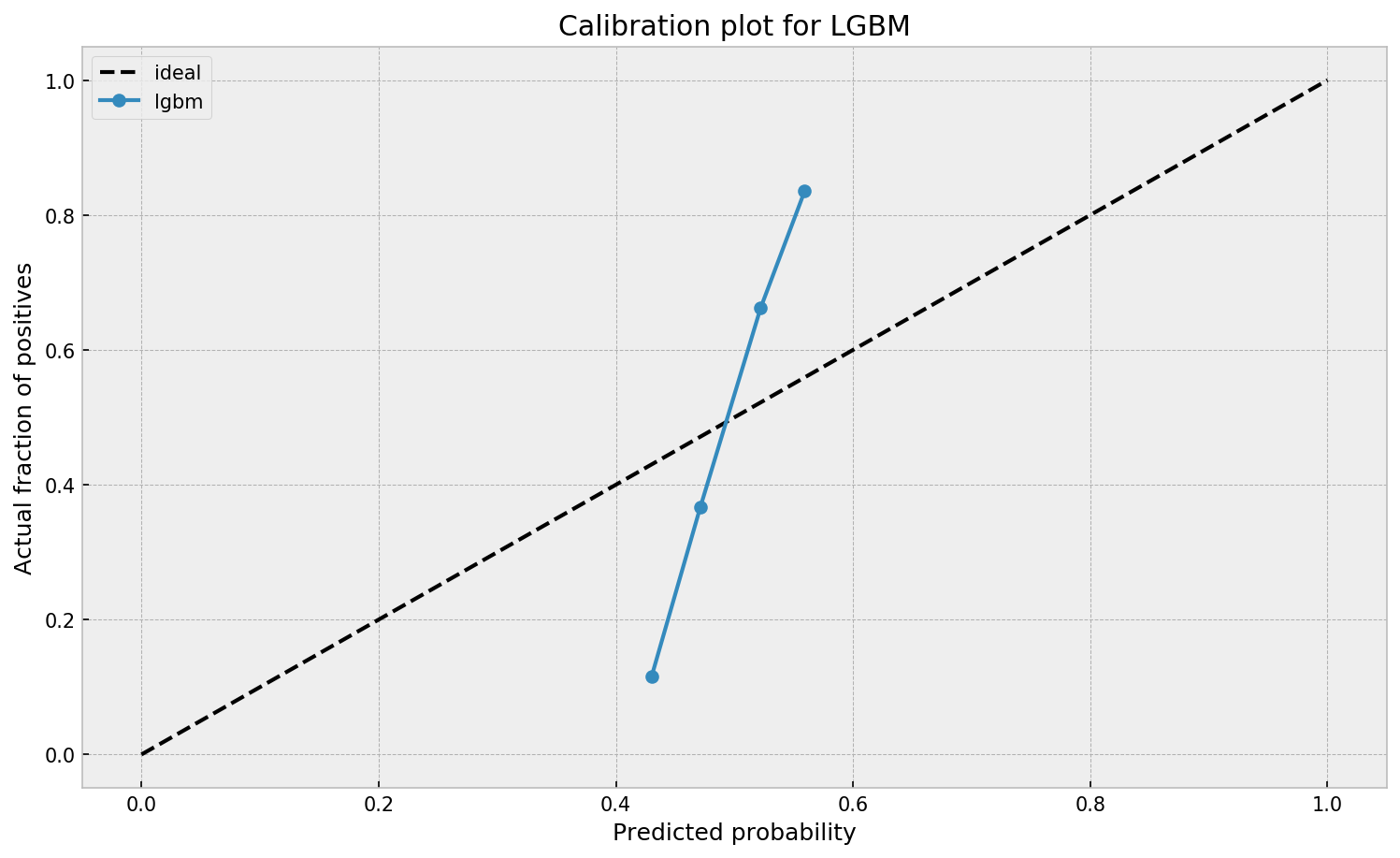
When working with ML models such as GBMs, RFs, SVMs or kNNs (any one that is not a logistic regression) we can observe a pattern that is intriguing: the probabilities that the model outputs do not correspond to the real fraction of positives we see in real life.
This is visible in the predictions of the light gradient boosted machine (LGBM) Guilherme trained: its predictions range only between ~ 0.45 and ~ 0.55. In contrast, the actual fraction of positive observations in those groups is much lower or higher (ranging from ~ 0.10 to ~0.85).
I highly recommend you look at Guilherme’s code to see for yourself what’s happening behind the scenes, but basically it’s this:
Train an algorithmic model (e.g., GBM) using your regular features (data)
Retrieve the probabilities GBM predicts
Retrieve the leaves (end-nodes) in which the GBM sorts the observations
Turn the array of leaves into a matrix of (one-hot-encoded) features, showing for each observation which leave it ended up in (1) and which not (many 0’s)
Basically, until now, you have used the GBM to reduce the original features to a new, one-hot-encoded matrix of binary features
Now you can use that matrix of new features as input for a logistic regression model predicting your target (Y) variable
Apparently, those logistic regression predictions will show a greater spread of probabilities with the same or better accuracy
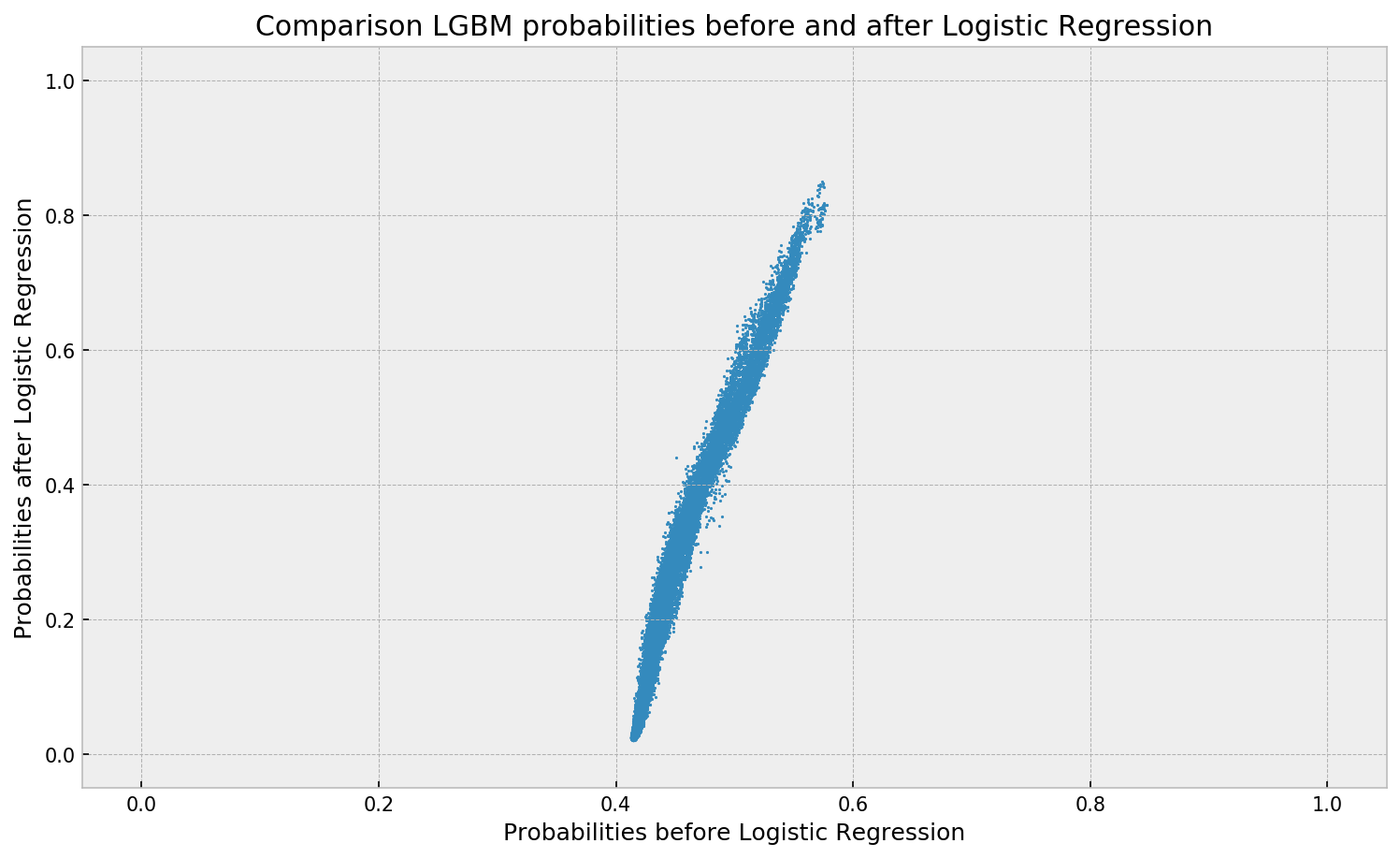
Here’s a visual depiction from Guilherme’s blog, with the original GBM predictions on the X-axis, and the new logistic predictions on the Y-axis.
As you can see, you retain roughly the same ordering, but the logistic regression probabilities spread is much larger.
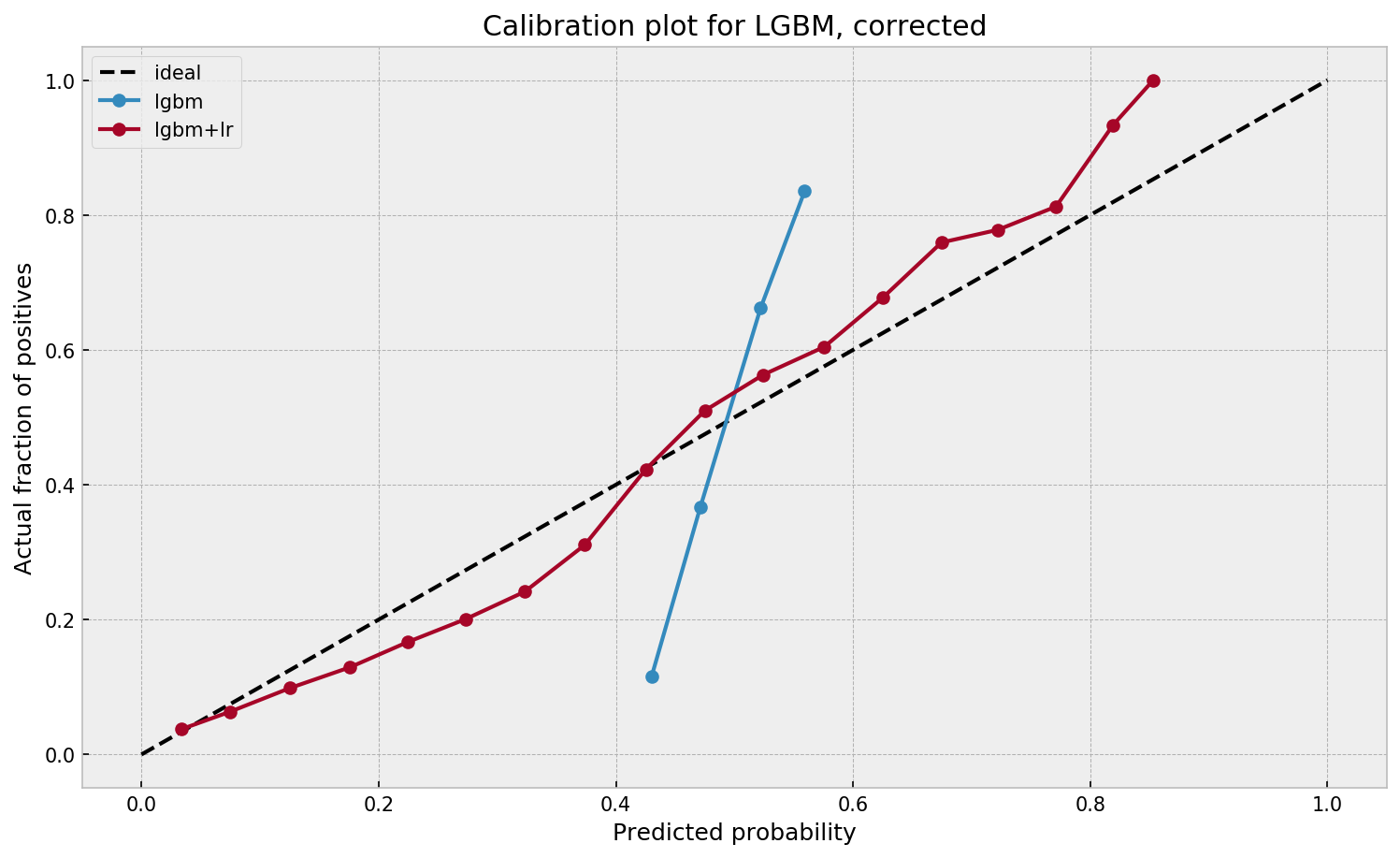
Now according to Guilherme and the Facebook paper he refers to, the accuracy of the logistic predictions should not be less than those of the original algorithmic method.
Much better. The calibration plot of lgbm+lr is much closer to the ideal. Now, when the model tells us that the probability of success is 60%, we can actually be much more confident that this is the true fraction of success! Let us now try this with the ET model.
In his blog, Guilherme shows the same process visually for an Extremely Randomized Trees model, so I highly recommend you read the original article. Also, you can find the complete code on his GitHub.
YouTube recommended I’d watch this recorded presentation by Raymond Hettinger at PyBay2019 last October. Quite a long presentation for what I’d normally watch, but what an eye-openers it contains!
Raymond Hettinger is a Python core developer and in this video he presents 10 programming strategies in these 60 minutes, all using live examples. Some are quite obvious, but the presentation and examples make them very clear. Raymond presents some serious programming truths, and I think they’ll stick.
First, Raymond discusses chunking and aliasing. He brings up the theory that the human mind can only handle/remember 7 pieces of information at a time, give or take 2. Anything above proves to much cognitive load, and causes discomfort as well as errors. Hence, in a programming context, we need to make sure programmers can use all 7 to improve the code, rather than having to decypher what’s in front of them. In a programming context, we do so by modularizing and standardizing through functions, modules, and packages. Raymond uses the Python random module to hightlight the importance of chunking and modular code. This part was quite long, but still interesting.
For the next two strategies, Raymond quotes the Feinmann method of solving problems: “(1) write down a clear problem specification; (2) think very, very hard; (3) write down a solution”. Using the example of a tree walker, Raymond shows how the strategies of incremental development and solving simpler programs can help you build programs that solve complex problems. This part only lasts a couple of minutes but really underlines the immense value of these strategies.
Next, Raymond touches on the DRY principle: Don’t Repeat Yourself. But in a context I haven’t seen it in yet, object oriented programming [OOP], classes, and inherintance.
Raymond continues to build his arsenal of programming strategies in the next 10 minutes, where he argues that programmers should repeat tasks manually until patterns emerge, before they starting moving code into functions. Even though I might not fully agree with him here, he does have some fun examples of file conversion that speak in his case.
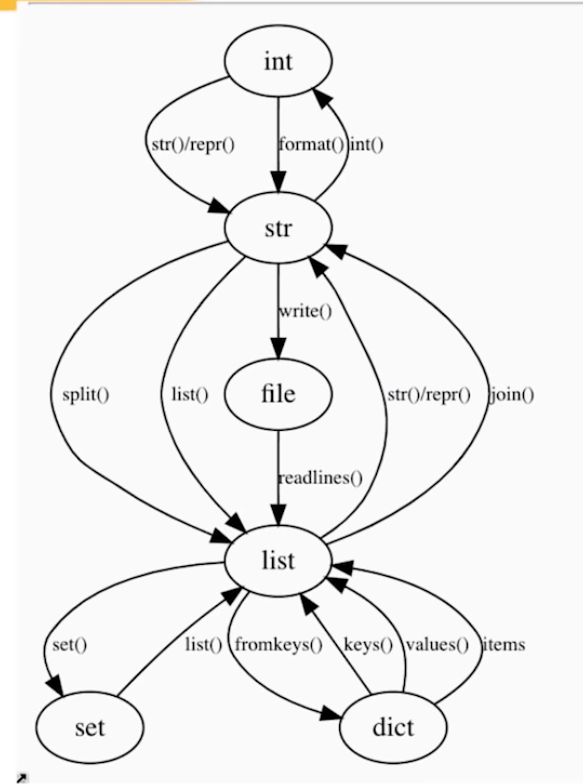
Lastly, Raymond uses the graph below to make the case that OOP is a graph traversal problem. According to Raymond, the Python ecosystem is so rich that there’s often no need to make new classes. You can simply look at the graph below. Look for the island you are currently on, check which island you need to get to, and just use the methods that are available, or write some new ones.
While there were several more strategies that Raymond wanted to discuss, he doesn’t make it to the end of his list of strategies as he spend to much time on the first, chunking bit. Super curious as to the rest? Contact Raymond on Twitter.
Harvard (bio)statisticians Miguel Hernan and Jamie Robins just released their new book, online and accessible for free!
The Causal Inference book provides a cohesive presentation of causal inference, its concepts and its methods. The book is divided in 3 parts of increasing difficulty: causal inference without models, causal inference with models, and causal inference from complex longitudinal data. Here’s the official Harvard page for the book release.
This is definitely an interesting read for epidemiologists, statisticians, psychologists, economists, sociologists, political scientists, data scientists, computer scientists, and any other person with a love for proper data analysis!
After several years of proscrastinating, the inevitable finally happened: Three months ago, I committed to learning Python!
I must say that getting started was not easy. One afternoon three months ago, I sat down, motivated to get started. Obviously, the first step was to download and install Python as well as something to write actual Python code. Coming from R, I had expected to be coding in a handy IDE within an hour or so. Oh boy, what was I wrong.
Apparently, there were already a couple of versions of Python present on my computer. And apparently, they were in grave conflict. I had one for the R reticulate package; one had come with Anaconda; another one from messing around with Tensorflow; and some more even. I was getting all kinds of error, warning, and conflict messages already, only 10 minutes in. Nothing I couldn’t handle in the end, but my good spirits had dropped slightly.
With Python installed, the obvious next step was to find the RStudio among the Python IDE’s and get working in that new environment. As an rational consumer, I went online to read about what people recommend as a good IDE. PyCharm seemed to be quite fancy for Data Science. However, what’s this Spyder alternative other people keep talking about? Come again, there are also Rodeo, Thonny, PyDev, and Wing? What about those then? A whole other group of Pythonista’s said that, as I work in Data Science, I should get Anaconda and work solely in Jupyter Notebooks! Okay…? But I want to learn Python to broaden my skills and do more regular software development as well. Maybe I start simple, in a (code) editor? However, here we have Atom, Sublime Text, Vim, and Eclipse? All these decisions. And I personally really dislike making regrettable decisions or committing to something suboptimal. This was already taking much, much longer than the few hours I had planned for setup.
This whole process demotivated so much that I reverted back to programming in R and RStudio the week after. However, I had not given up. Over the course of the week, I brought the selection back to Anaconda Jupyter Notebooks, PyCharm, and Atom, and I was ready to pick one. But wait… What’s this Visual Studio Code (VSC) thing by Microsoft. This looks fancy. And it’s still being developed and expanded. I had already been working in Visual Studio learning C++, and my experiences had been good so far. Moreover, Microsoft seems a reliable software development company, they must be able to build a good IDE? I decided to do one last deepdive.
The more I read about VSC and its features for Python, the more excited I got. Hey, VSC’s Python extension automatically detects Python interpreters, so it solves my conflicts-problem. Linting you say? Never heard of it, but I’ll have it. Okay, able to run notebooks, nice! Easy debugging, testing, and handy snippets… Okay! Machine learning-based IntelliSense autocompletes your Python code – that sounds like something I’d like. A shit-ton of extensions? Yes please! Multi-language support – even tools for R programming? Say no more! I’ll take it. I’ll take it all!
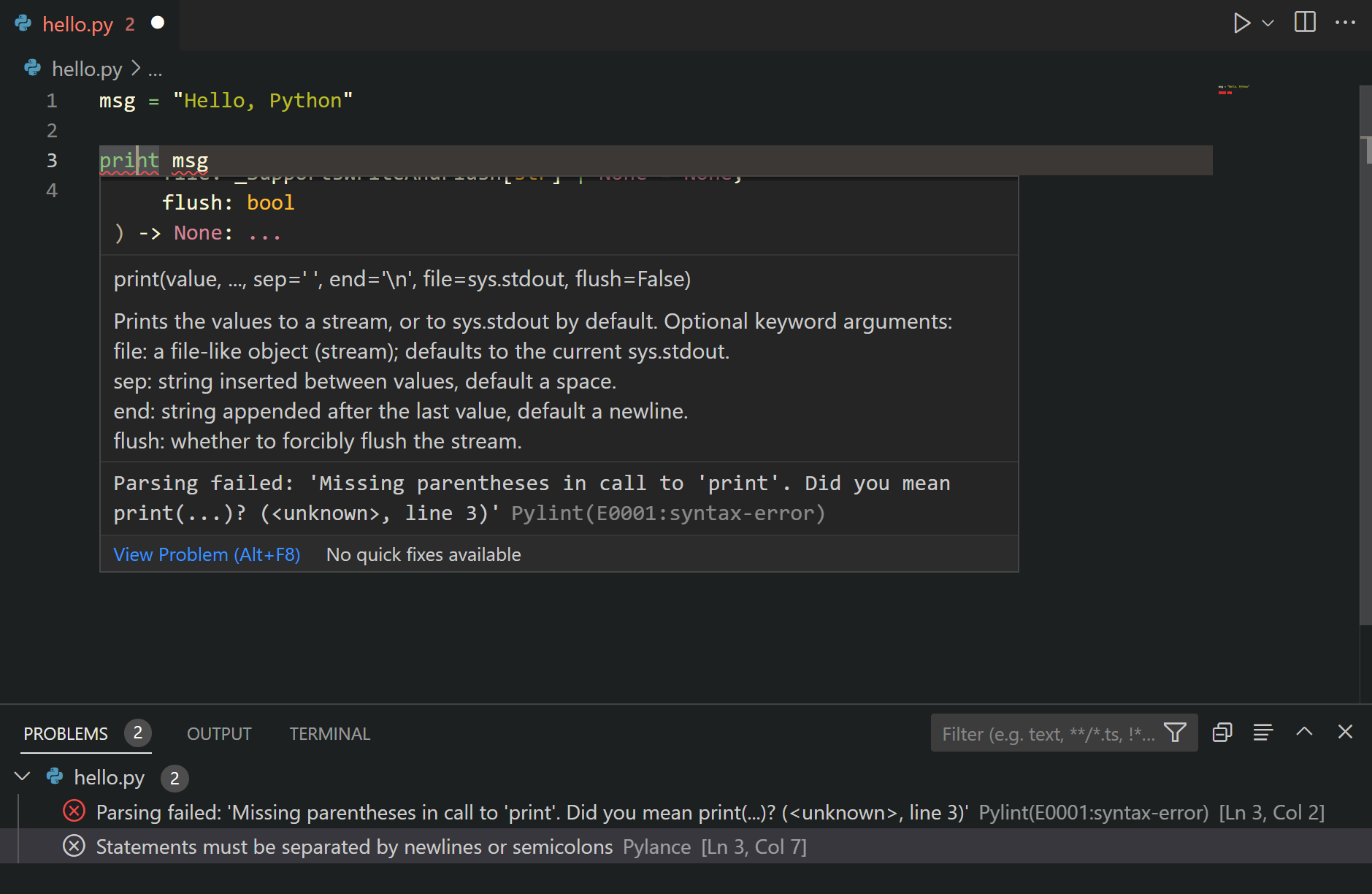
Linting in VSC provides code suggestions
My goods friends at Microsoft were not done yet though. To top it all of, they have documented everything so well. It’s super easy to get started! There are numerous ordered pages dedicated to helping you set up and discover your new Python environment in VSC:
The Microsoft VSC pages also link to some more specific resources:
Editing Python in VS Code: Learn more about how to take advantage of VS Code’s autocomplete and IntelliSense support for Python, including how to customize their behvior… or just turn them off.
Linting Python: Linting is the process of running a program that will analyse code for potential errors. Learn about the different forms of linting support VS Code provides for Python and how to set it up.
Debugging Python: Debugging is the process of identifying and removing errors from a computer program. This article covers how to initialize and configure debugging for Python with VS Code, how to set and validate breakpoints, attach a local script, perform debugging for different app types or on a remote computer, and some basic troubleshooting.
Unit testing Python: Covers some background explaining what unit testing means, an example walkthrough, enabling a test framework, creating and running your tests, debugging tests, and test configuration settings.
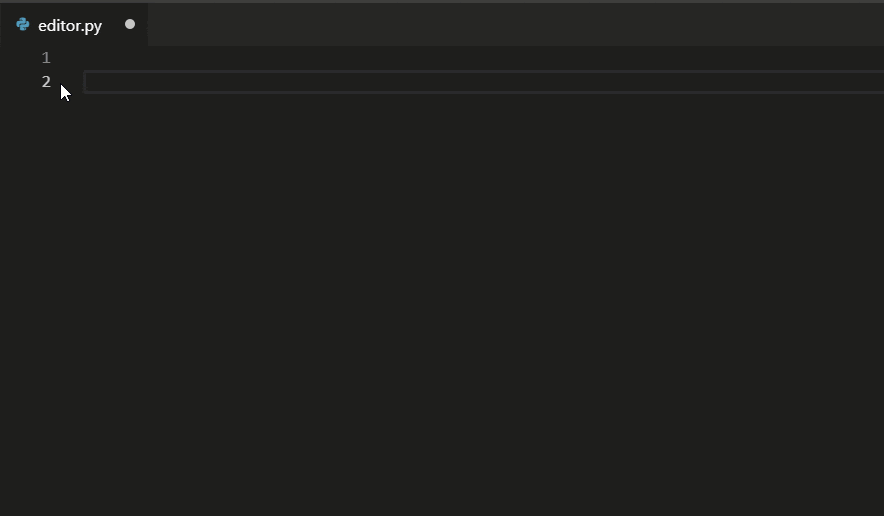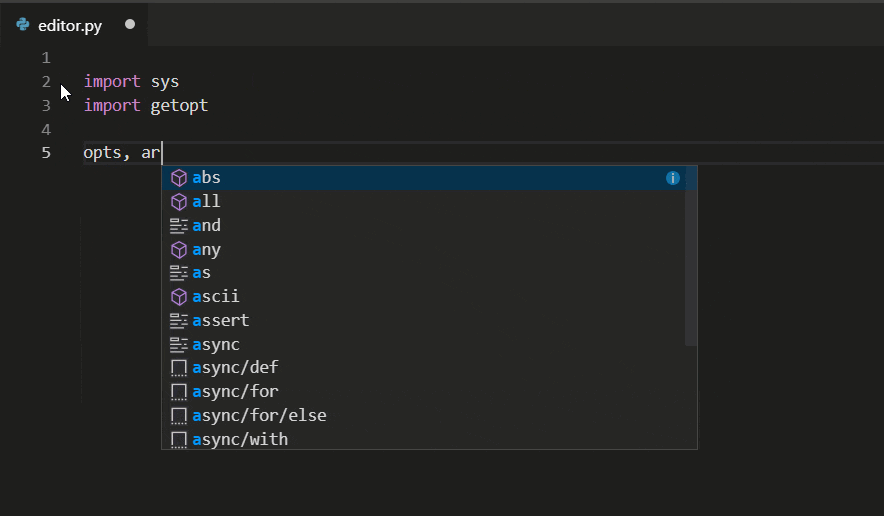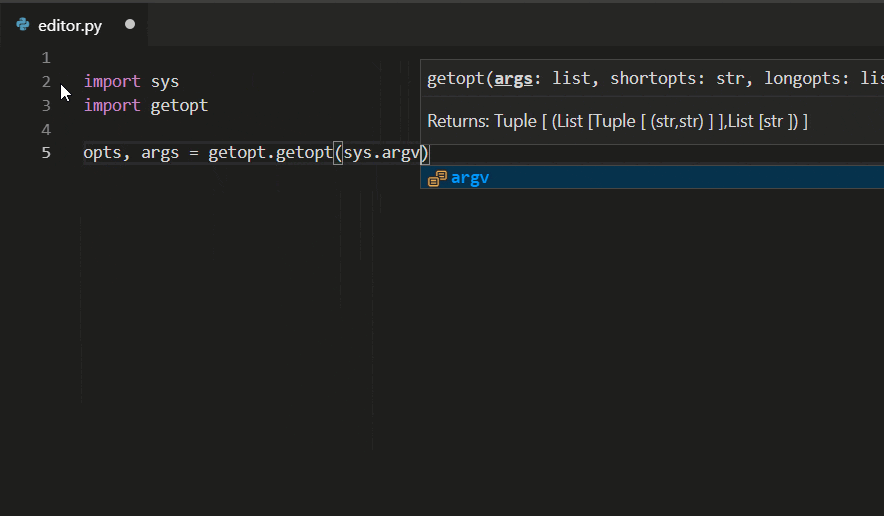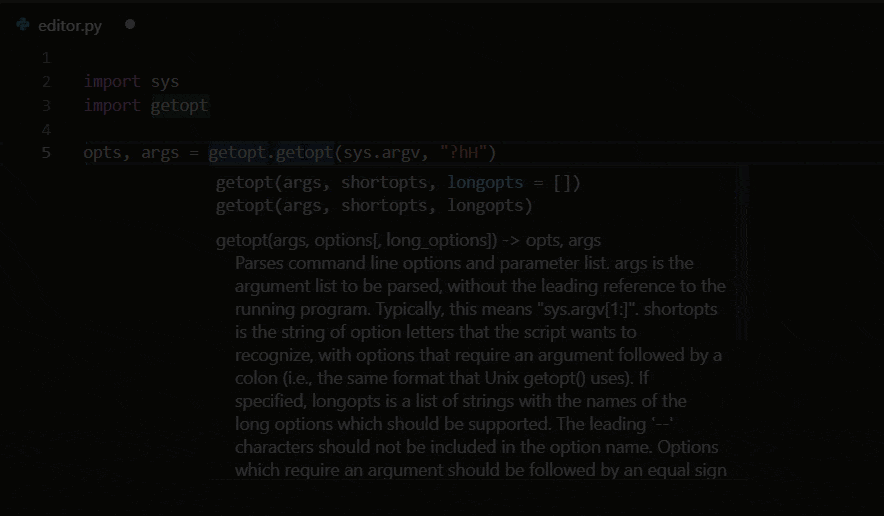
Python IntelliSense in VSC makes real-time code autocomplete suggestions
My Own Python Journey
So three months in I am completely blown away at how easy, fun, and versatile the language is. Nearly anything is possible, most of the language is intuitive and straightforward, and there’s a package for anything you can think of. Although I have spent many hours, I am very happy with the results. I did not get this far, this quickly, in any other language. Let me share some of the stuff I’ve done the past three months.
I’ve mainly been building stuff. Some things from scratch, others by tweaking and recycling other people’s code. In my opinion, reusing other people’s code is not necessarily bad, as long as you understand what the code does. Moreover, I’ve combed through lists and lists of build-it-yourself projects to get inspiration for projects and used stuff from my daily work and personal life as further reasons to code. I ended up building:
solutions to the first 31 problems of Project Euler, which I highly recommend you try to solve yourself!
solutions to the first dozen problems posed in Automate the Boring Stuff with Python. This book and online tutorial forces you to get your hands dirty right from the start. Simply amazing content and the learning curve is precisely good
"Programming today is a race between software engineers striving to build bigger and better idiot-proof programs, and the universe trying to build bigger and better idiots. So far, the universe is winning." – Rick Cook#programming#coding#ArtificialStupidity no.20 pic.twitter.com/cBiR1HQszn
all Socratica Python Youtube videos. They are simply a fantastic introduction to the language and amazingly amusing. You can sponsor them here
hours and hours of Corey Shafer’s Youtube channel. Seriously good quality content, and more in-depth than Socratica. Corey covers the versatile functionalities included in the standard Python libraries and then some more
Although it is no longer maintained, you might find some more, interesting links on my Python resources page or here, for those transitioning from R. If only the links to the more up-to-date resources pages. Anyway, hope this current blog helps you on your Python journey or to get Python and Visual Studio Code working on your computer. Please feel free to share any of the stories, struggles, or successes you experience!