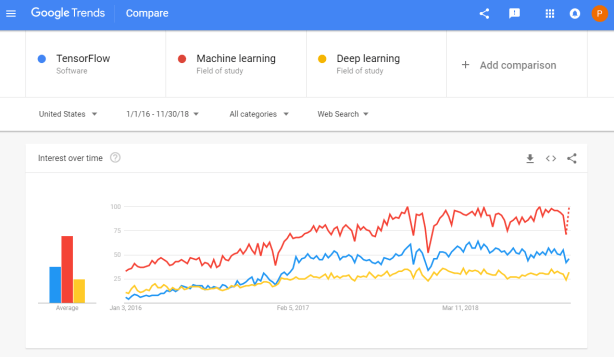
Tensorflow is a open-source machine learning (ML) framework. It’s primarily used to build neural networks, and thus very often used to conduct so-called deep learning through multi-layered neural nets.
Although there are other ML frameworks — such as Caffe or Torch — Tensorflow is particularly famous because it was developed by researchers of Google’s Brain Lab. There are widespread debates on which framework is best, nonetheless, Tensorflow does a pretty good job on marketing itself.
Google search engine searches on Tensorflow in comparison to searches on Machine learing and Deep learning
Bret Beheim — senior researcher at the Max Planck Institute for Evolutionary Anthropology — posted a great GIF animation of the response to his research survey. He calls the figure citation gates, relating the year of scientific publication to the likelihood that the research materials are published open-source or accessible.
To generate the visualization, Bret used R’s base plotting functionality combined with Thomas Lin Pedersen‘s R package tweenrto animate it.
I've been experimenting with R animations using the tweenR package for visualizing the results of our reproducibility survey, and I think it turned out pretty nice. pic.twitter.com/MRerAWHNYT
Bret shared his R code for the above GIF of his citation gateson GitHub. With the open source code, this amazing visual display inspired others to make similar GIFs for their own projects. For example, Anne-Wil Kruijt’s dance of the confidence intervals:
Two wks ago I built a shiny 'CI demo' app for a job interview. Yet I wasn't quite content with it. Then 2 days ago @babeheim posted an amazing gif (srsly, go check it!). Super inspired, & borrowing heavily from his code: my rendition of 'the Dance of the Confidence Intervals' pic.twitter.com/ORheOBBzDm
A spin-off of the citation gates: A gif showing confidence intervals of sample means.
Applied to a Human Resource Management context, we could use this similar animation setup to explore, for instance, recruitment, selection, or talent management processes.
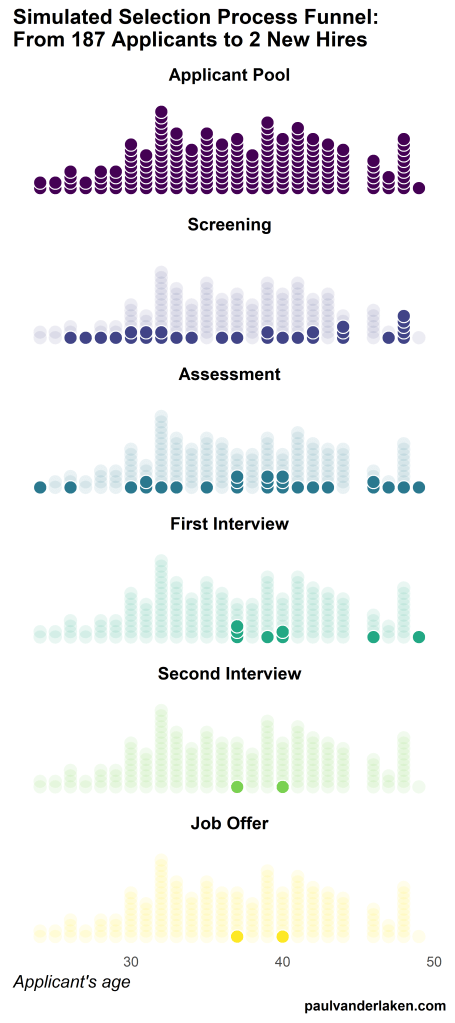
Unfortunately, I couldn’t get the below figure to animate properly yet, but I am working on it (damn ggplot2 facets). It’s a quick simulation of how this type of visualization could help to get insights into the recruitment and selection process for open vacancies.
The figure shows how nearly 200 applicants — sorted by their age — go through several selection barriers. A closer look demonstrates that some applicants actually skip the screening and assessment steps and join via a fast lane in the first interview round, which could happen, for instance, when there are known or preferred internal candidates. When animated, such insights would become more clearly visible.
I’ve mentioned before that I dislike wordclouds (for instance here, or here) and apparently others share that sentiment. In his recent Medium blog, Daniel McNichol goes as far as to refer to the wordcloud as the pie chart of text data! Among others, Daniel calls wordclouds disorienting, one-dimensional, arbitrary and opaque and he mentions their lack of order, information, and scale.
Wordcloud of the negative characteristics of wordclouds, via Medium
Instead of using wordclouds, Daniel suggests we revert to alternative approaches. For instance, in their Tidy Text Mining with R book, Julia Silge and David Robinson suggest using bar charts or network graphs, providing the necessary R code. Another alternative is provided in Daniel’s blog: the chatterplot!
While Daniel didn’t invent this unorthodox wordcloud-like plot, he might have been the first to name it a chatterplot. Daniel’s chatterplot uses a full x/y cartesian plane, turning the usually only arbitrary though exploratory wordcloud into a more quantitatively sound, information-rich visualization.
R package ggplot’s geom_text() function — or alternatively ggrepel‘s geom_text_repel() for better legibility — is perfectly suited for making a chatterplot. And interesting features/variables for the axis — apart from the regular word frequencies — can be easily computed using the R tidytext package.
Here’s an example generated by Daniel, plotting words simulatenously by their frequency of occurance in comments to Hacker News articles (y-axis) as well as by the respective popularity of the comments the word was used in (log of the ranking, on the x-axis).
[CHATTERPLOTs are] like a wordcloud, except there’s actual quantitative logic to the order, placement & aesthetic aspects of the elements, along with an explicit scale reference for each. This allows us to represent more, multidimensional information in the plot, & provides the viewer with a coherent visual logic& direction by which to explore the data.
I highly recommend the use of these chatterplots over their less-informative wordcloud counterpart, and strongly suggest you read Daniel’s original blog, in which you can also find the R code for the above visualizations.
Marcus Volz is a research fellow at the University of Melbourne, studying geometric networks, optimisation and computational geometry. He’s interested in visualisation, and always looking for opportunities to represent complex information in novel ways to accelerate learning and uncover the unexpected.
One of Marcus’ hobbies is the visualization of mathematical patterns and statistical algorithms via R. He has a whole portfolio full of them, including a Github page with all the associated R code. For my recent promotion, my girlfriend asked Marcus to generate a K-nearest neighbors visual and she had it printed on a large canvas.
The picture contains about 10.000 points, randomly uniformly distributed across x and y, connected by lines with their closest k other points. Marcus shared the code to generate such k-nearest neighbor algorithm plots here on Github. So if you know your way around R, you could make your own version:
#' k-nearest neighbour graph
#'
#' Computes a k-nearest neighbour graph for a given set of points. Refer to the \href{https://en.wikipedia.org/wiki/Nearest_neighbor_graph}{Wikipedia article} for details.
#' @param points A data frame with x, y coordinates for the points
#' @param k Number of neighbours
#' @keywords nearest neightbour graph
#' @export
#' @examples
#' k_nearest_neighbour_graph()
k_nearest_neighbour_graph <- function(points, k=8) {
get_k_nearest <- function(points, ptnum, k) {
xi <- points$x[ptnum]
yi <- points$y[ptnum] points %>%
dplyr::mutate(dist = sqrt((x - xi)^2 + (y - yi)^2)) %>%
dplyr::arrange(dist) %>%
dplyr::filter(row_number() %in% seq(2, k+1)) %>%
dplyr::mutate(xend = xi, yend = yi)
}
1:nrow(points) %>%
purrr::map_df(~get_k_nearest(points, ., k))
}
Those less versed in R can use Marcus package mathart. With this package, Marcus shares many more visual depictions of cool algorithms! You can install the package and several dependencies with the following lines of code:
This page of Marcus’ mathart Github repository contains the code exact code for these and many other visualizations of algorithms and statistical phenomena. Do check it out if you’re interested!
Also, check out the “Fun” section of my R tips and tricks list for more cool visuals you can generate in R!
I recently came across this lovely article where Ali Spittel provides 7 tips for writing cleaner JavaScript code. Enthusiastic about her guidelines, I wanted to translate them to the R programming environment. However, since R is not an object-oriented programming language, not all tips were equally relevant in my opinion. Here’s what really stood out for me.
Suppose we want to create our own custom function to derive the average value of a vector v (please note that there is a base::mean function to do this much more efficiently). We could use the R code below to compute that the average of vector 1 through 10 is 5.5.
avg <- function(v){
s = 0
for(i in seq_along(v)) {
s = s + v[i]
}
return(s / length(v))
}
avg(1:10) # 5.5
However, Ali rightfully argues that this code can be improved by making the variable and function names much more explicit. For instance, the refigured code below makes much more sense on a first look, while doing exactly the same.
averageVector <- function(vector){
sum = 0
for(i in seq_along(vector)){
sum = sum + vector[i]
}
return(sum / length(vector))
}
averageVector(1:10) #5.5
Of course, you don’t want to make variable and function names unnecessary long (e.g., average would have been a great alternative function name, whereas computeAverageOfThisVector is probably too long). I like Ali’s principle:
Don’t minify your own code; use full variable names that the next developer can understand.
2. Write short functions that only do one thing
Ali argues “Functions are more understandable, readable, and maintainable if they do one thing only. If we have a bug when we write short functions, it is usually easier to find the source of that bug. Also, our code will be more reusable.” It thus helps to break up your code into custom functions that all do one thing and do that thing good!
For instance, our earlier function averageVector actually did two things. It first summated the vector, and then took the average. We can split this into two seperate functions in order to standardize our operations.
sumVector <- function(vector){
sum = 0
for(i in seq_along(vector)){
sum = sum + vector[i]
}
return(sum)
}
averageVector <- function(vector){
sum = sumVector(vector)
average = sum / length(vector)
return(average)
}
sumVector(1:10) # 55
averageVector(1:10) # 5.5
If you are writing a function that could be named with an “and” in it — it really should be two functions.
3. Documentation
Personally, I am terrible in commenting and documenting my work. I am always too much in a hurry, I tell myself. However, no more excuses! Anybody should make sure to write good documentation for their code so that future developers, including future you, understand what your code is doing and why!
Ali uses the following great example, of a piece of code with magic numbers in it.
Now, you might immediately recognize the number Pi in this return statement, but others may not. And maybe you will need the value Pi somewhere else in your script as well, but you accidentally use three decimals the next time. Best to standardize and comment!
PI <- 3.14 # PI rounded to two decimal places
areaOfCircle <- function(radius) {
# Implements the mathematical equation for the area of a circle:
# Pi times the radius of the circle squared.
return(PI * radius ** 2)
}
The above is much clearer. And by making PI a variable, you make sure that you use the same value in other places in your script! Unfortunately, R doesn’t handle constants (unchangeable variables), but I try to denote my constants by using ALL CAPITAL variable names such as PI, MAX_GROUP_SIZE, or COLOR_EXPERIMENTAL_GROUP.
Do note that R has a built in variable pi for purposes such as the above.
I love Ali’s general rule that:
Your comments should describe the “why” of your code.
However, more elaborate R programming commenting guidelines are given in the Google R coding guide, stating that:
Functions should contain a comments section immediately below the function definition line. These comments should consist of a one-sentence description of the function; a list of the function’s arguments, denoted by Args:, with a description of each (including the data type); and a description of the return value, denoted by Returns:. The comments should be descriptive enough that a caller can use the function without reading any of the function’s code.
Either way, prevent that your comments only denote “what” your code does:
# EXAMPLE OF BAD COMMENTING ####
PI <- 3.14 # PI
areaOfCircle <- function(radius) {
# custom function for area of circle
return(PI * radius ** 2) # radius squared times PI
}
5. Be Consistent
I do not have as strong a sentiment about consistency as Ali does in her article, but I do agree that it’s nice if code is at least somewhat in line with the common style guides. For R, I like to refer to my R resources list which includes several common style guides, such as Google’s or Hadley Wickham’s Advanced R style guide.
Today I learned about dygraphs, a fast, flexible open source JavaScript charting library. As everything in JavaScript, the charts produced by dygraphs integrate completely in the webbrowser and are thus very functional and interactive. See, for instance, the below where the graph highlights the y-axis value for both time series in the graph based on the x-axis value of my mouse location (January 24 2009). Very cool!
Fortunately, I do know my way around R, and of course someone had already integrated dypgrahs in R in the form of the dygraphs R package. It works like a charm!